月間特許トレンドウォッチ
生成系AIは、データから新しいコンテンツを生成する革新的な技術です。まるで無限の創造力を持つ作家やアーティストがデジタルの世界に誕生したかのように、テキスト、画像、音楽、そして動画の生成が可能になり、さまざまな分野で驚異的な進化を遂げています。今回は、そんな生成系AIの主要な種類と主なサービス、そしてその近年の発展状況について考察していきます。
生成系AIの種類
生成系AIは大きく分けて、以下のような種類に分類されます。
1.テキスト生成
テキスト生成AIは、入力されたデータに基づいて新しい文章を生成します。例えば、ニュース記事、ブログ投稿、詩、小説などを自動生成します。
GPT-4o(OpenAI): 高度な言語モデルで、質問応答、記事生成、翻訳など幅広い用途に使用されています。
Jasper(旧名:Jarvis): コンテンツマーケティングに特化したAIライティングツール。
2.画像生成
画像生成AIは、与えられたテキストや他の画像を基に新しい画像を生成します。
DALL-E(OpenAI): テキストから高解像度の画像を生成するAI。
Midjourney: 芸術作品やデザインに使用される画像生成ツール。
3 音楽生成
音楽生成AIは、新しい楽曲を作成するために使用されます。
Amper Music: AIによってカスタマイズされた音楽を生成するプラットフォーム。
AIVA(Artificial Intelligence Virtual Artist): 映画、広告、ゲーム用の音楽を生成するAI。
4 動画生成
動画生成AIは、テキストや画像から新しい動画を生成します。
Synthesia: テキストからプロフェッショナルな動画を生成するプラットフォーム。
Runway: AIを使った動画編集と生成ツール。
生成系AIの発展性
近年の生成系AIの発展は目覚ましいものがあります。以下はテキスト生成AIの市場成長を示すグラフです。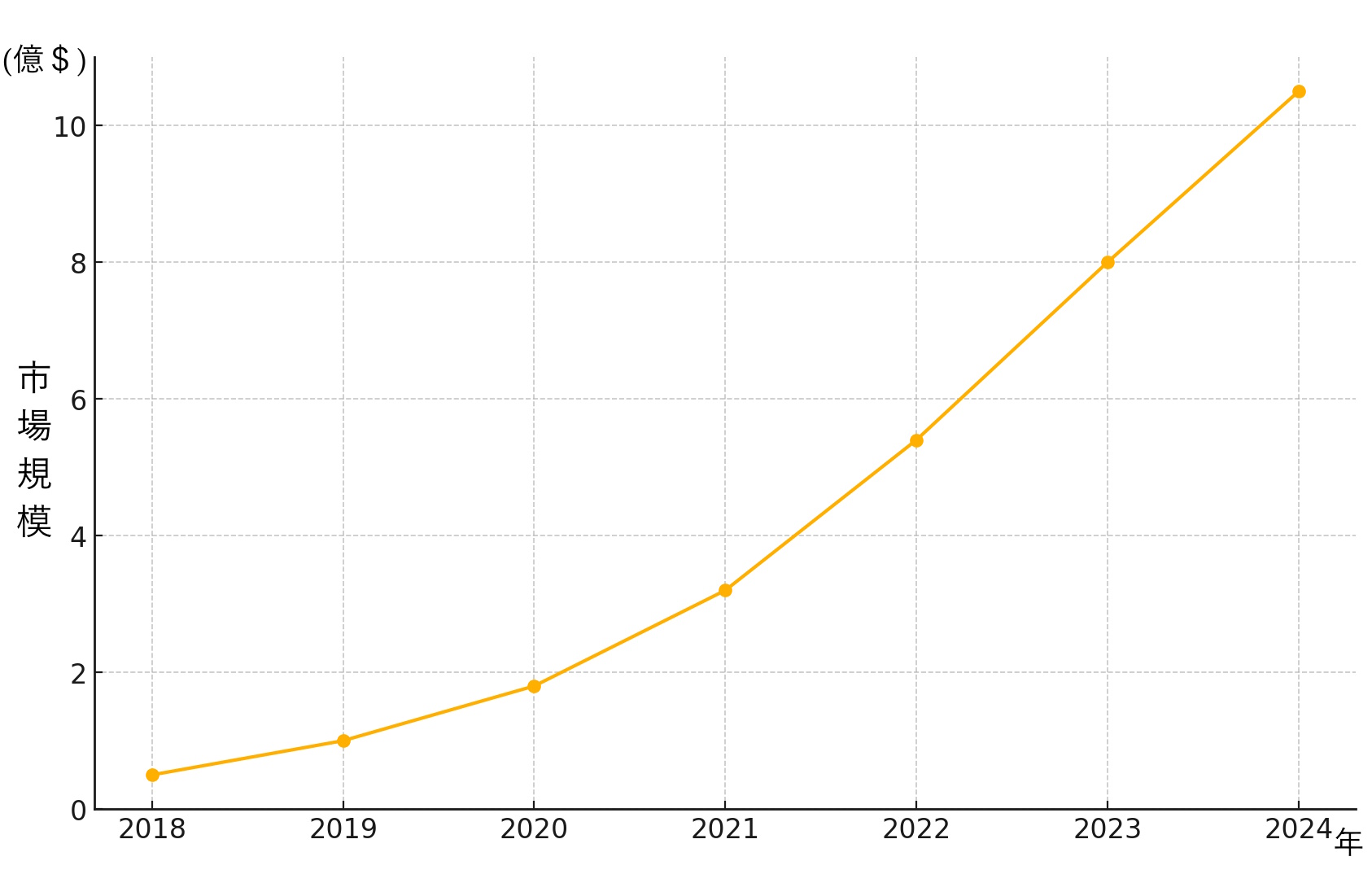
テキスト生成AIの市場はGPT-3の登場により精度と多様性が飛躍的に向上し、急速に成長しました。
例えば、2018年には市場規模が約0.5億ドルであったのに対し、2024年には約10.5億ドルに達すると予測されています。この成長は、企業がコンテンツ生成の効率化を求めていることや、個別化された顧客体験の提供を目指していることが背景にあります。テキスト生成AIは、ニュース記事の作成、カスタマーサポートの自動応答、クリエイティブライティングなど、さまざまな用途で利用されています。
画像生成AIもまた急速に進化しています。
| 年 | モデル名 | パラメータ数 (億) | 生成画像の品質 (PSNR) |
|---|---|---|---|
| 2018年 | GAN | 0.2 | 25.0 |
| 2020年 | StyleGAN2 | 1.0 | 28.5 |
| 2022年 | DALL-E | 17.5 | 30.2 |
| 2023年 | Midjourney V5 | 26.0 | 32.1 |
| 2024年 | DALL-E 3 | 35.0 | 33.5 |
初期のGenerative Adversarial Networks(GAN)が登場したころは、生成された画像の品質は低かったですが、その後のStyleGANやDALL-Eの登場により、画像生成の品質は飛躍的に向上しました。例えば、2020年のStyleGAN2は、1億のパラメータを持ち、生成される画像の品質はPSNR(Peak Signal-to-Noise Ratio)で28.5という高い数値を達成しました。
さらに、2024年にはDALL-E 3が登場し、35億のパラメータを持つこのモデルは、PSNRで33.5を記録し、よりリアルで高品質な画像生成が可能となりました。これにより、デザイン、広告、エンターテイメントなどの分野での応用が急速に広がっています。
音楽生成AI、動画生成AIも同様に進歩を遂げています。
例えば、Amper MusicやAIVAなどのサービスは、映画や広告、ゲームのためのオリジナル音楽を短時間で生成することができます。これにより、クリエイティブプロセスの効率化が図られ、個別のニーズに応じた音楽の提供が可能になっています。
SynthesiaやRunwayなどのサービスは、テキストや静止画からプロフェッショナルな動画を生成することができ、広告やマーケティング、教育分野での利用が進んでいます。特に、リアルタイムでの動画生成技術が進化し、ライブイベントやオンライン教育の質を大幅に向上させています。
生成系AIのこれから
生成系AIの未来は、教育、医療、エンターテインメントといった多岐にわたる分野での応用が期待されています。
教育分野では、生成系AIを活用した自動教材生成や個別指導が進化し、教育の質とアクセスが飛躍的に向上するでしょう。例えば、生徒一人ひとりに合わせたカリキュラムの作成や、リアルタイムでのフィードバックが可能になります。
医療分野では、膨大な医療データを基に新薬の候補を生成するAIや、個々の患者に最適な治療法を提案するAIが既に登場しており、今後も患者の診断と治療に革命をもたらすでしょう。具体的には、遺伝子データ解析を通じてパーソナライズされた治療計画の立案や、AIによる早期診断が期待されています。
エンターテインメント分野では、映画やゲームのストーリーライン生成、キャラクターの自動生成などが進み、クリエイティブなプロジェクトの新たな可能性が広がります。例えば、ユーザーの好みに合わせたオリジナルコンテンツの生成や、リアルタイムでのインタラクティブな物語体験が実現されるでしょう。
生成系AIは、テキスト、画像、音楽、動画など様々なコンテンツを生成する能力を持ち、近年その技術は急速に進化しています。市場規模の拡大や性能の向上は、生成系AIの発展を物語っています。今後も多くの分野で応用が進むことでしょう。
このように、生成系AIの進化は我々の生活を豊かにし、新しい可能性を広げる大きな要因となっています。将来的には、さらに多様なサービスやアプリケーションが登場し、生成系AIの利便性と影響力は一層増していくでしょう。
パテントディスカバリー

今回紹介する特許は、テキスト入力から高品質な画像を生成する画期的なシステムです。従来の画像生成システムは、低品質や非効率性の問題を抱えていましたが、本発明は、テキストエンコーダと画像エンコーダを共同でトレーニングすることにより、テキストの意味を正確に反映し、視覚的に魅力的な画像を迅速に生成します。
具体的には、テキストエンコーダがテキスト記述を多次元ベクトル表現に変換し、それを画像エンコーダが画像埋め込みに変換します。さらに、拡散モデルやオートレグレッシブモデルを活用することで、画像のバリエーションや品質が大幅に向上します。この技術は、クリエイティブ業界や教育分野など、多岐にわたる分野で革新をもたらすことが期待されています。
発明の背景
本発明は、テキスト入力に基づいて画像を生成するシステムに関するものです。従来の画像生成システムでは、低品質で低解像度の画像が生成されがちで、視覚的な魅力に欠ける上、効率的でなく、時間がかかることが課題でした。また、生成された画像は人間が理解しにくい場合が多く、テキストの意味を正確に反映しないことも頻繁にありました。さらに、画像のバリエーションが少なく、一つのテキスト入力に対して多様な画像を生成することが難しいという問題もありました。
従来の画像生成システムでは、トレーニングや生成の過程が非効率であり、時間がかかるという問題がありました。また、生成された画像が人間にとって理解しにくい場合が多く、テキストの意味を正確に反映しないことが頻繁にありました。さらに、生成された画像のバリエーションが少なく、一つのテキスト入力に対して多様な画像を生成することが難しいという問題もありました。
発明の目的
本発明の目的は、テキスト入力に基づいて高品質で多様な画像を生成するシステムおよび方法を提供することです。このシステムは、テキスト記述を多次元ベクトル表現に変換するテキストエンコーダと、そのベクトル表現を基に画像埋め込みを生成する画像エンコーダを含むことで、テキストの意味を正確に反映し、高解像度で視覚的に魅力的な画像を生成します。
また、生成プロセスの効率を向上させ、ユーザーが望む特定の特徴やスタイルを忠実に再現する画像を提供することを目指しています。これにより、従来のシステムの限界を克服し、テキスト入力に対応する多様で高品質な画像生成を実現します。
具体的には、次のような技術的目標を達成します。
高品質な画像生成:テキスト記述に基づいて、視覚的に魅力的で高解像度の画像を生成します。
効率的なプロセス:訓練と画像生成のプロセスを効率化し、時間とリソースを節約します。
正確な意味の反映:テキストの意味を正確に反映し、ユーザーの要求に合致する画像を生成します。
多様な画像生成:一つのテキスト入力に対して多様な画像を生成し、ユーザーのニーズに対応します。
修正と操作の柔軟性:生成された画像を容易に修正・操作できるようにし、生成プロセスの中間ステップを視覚化できる機能を提供します。
発明の詳細
まず、本発明の技術的にキーとなる要素について、まとめておきます。
本発明は、テキスト入力に基づいて高品質で多様な画像を生成するためのシステムおよび方法に関するものであり、以下の技術的な詳細を含みます。
システム構成
1. テキストエンコーダ
テキスト記述を多次元ベクトル表現に変換します。これにより、テキストの意味や構造が数値化され、後続の処理に利用できる形にします。
2. 画像エンコーダ
ベクトル表現を基に画像埋め込みを生成します。画像エンコーダは、画像の特徴を抽出し、それを多次元ベクトルとして表現します。
3. サブモデル
第1のサブモデルは、テキストエンコーダからの出力を受け取り、画像埋め込みを生成します。
第2のサブモデルは、生成された画像埋め込みを用いて最終的な出力画像を生成します。
動作フロー
1. テキストの入力
ユーザーからのテキスト記述を取得し、テキストエンコーダに入力します。
2. テキストエンコード
テキストエンコーダがテキスト記述を多次元ベクトル表現に変換します。
3. 画像埋め込みの生成
第1のサブモデルがテキストエンコーダの出力を基に画像埋め込みを生成します。これにより、テキスト記述に対応する視覚情報が数値化されます。
4. 出力画像の生成
第2のサブモデルが画像埋め込みを基に最終的な出力画像を生成します。このプロセスでは、画像の特徴やスタイルが反映され、視覚的に魅力的な画像が生成されます。
技術的改善
1. 高品質な画像生成
テキスト入力に基づいて高解像度で視覚的に魅力的な画像を生成します。これにより、従来のシステムの低品質な画像生成の問題を克服します。
2. 効率的なプロセス
トレーニングと画像生成のプロセスを効率化し、時間とリソースを節約します。これにより、実用性の高いシステムを提供します。
3. 正確な意味の反映
テキストの意味を正確に反映し、ユーザーの要求に合致する画像を生成します。これにより、ユーザーが望む特定の特徴やスタイルを忠実に再現します。
4. 多様な画像生成
一つのテキスト入力に対して複数のバリエーションを持つ画像を生成し、ユーザーの様々なニーズに対応します。これにより、より多様な用途に対応可能な画像生成を実現します。
5. 修正と操作の柔軟性
生成された画像を容易に修正・操作できるようにし、生成プロセスの中間ステップを視覚化できる機能を提供します。これにより、ユーザーが生成された画像をカスタマイズしやすくなります。
本発明は、テキストエンコーダと画像エンコーダの共同トレーニングを通じて、高品質で多様な画像生成を実現し、従来のシステムの限界を克服することを実現します。
以下では図面を参照しながらさらに深堀りしていきます。
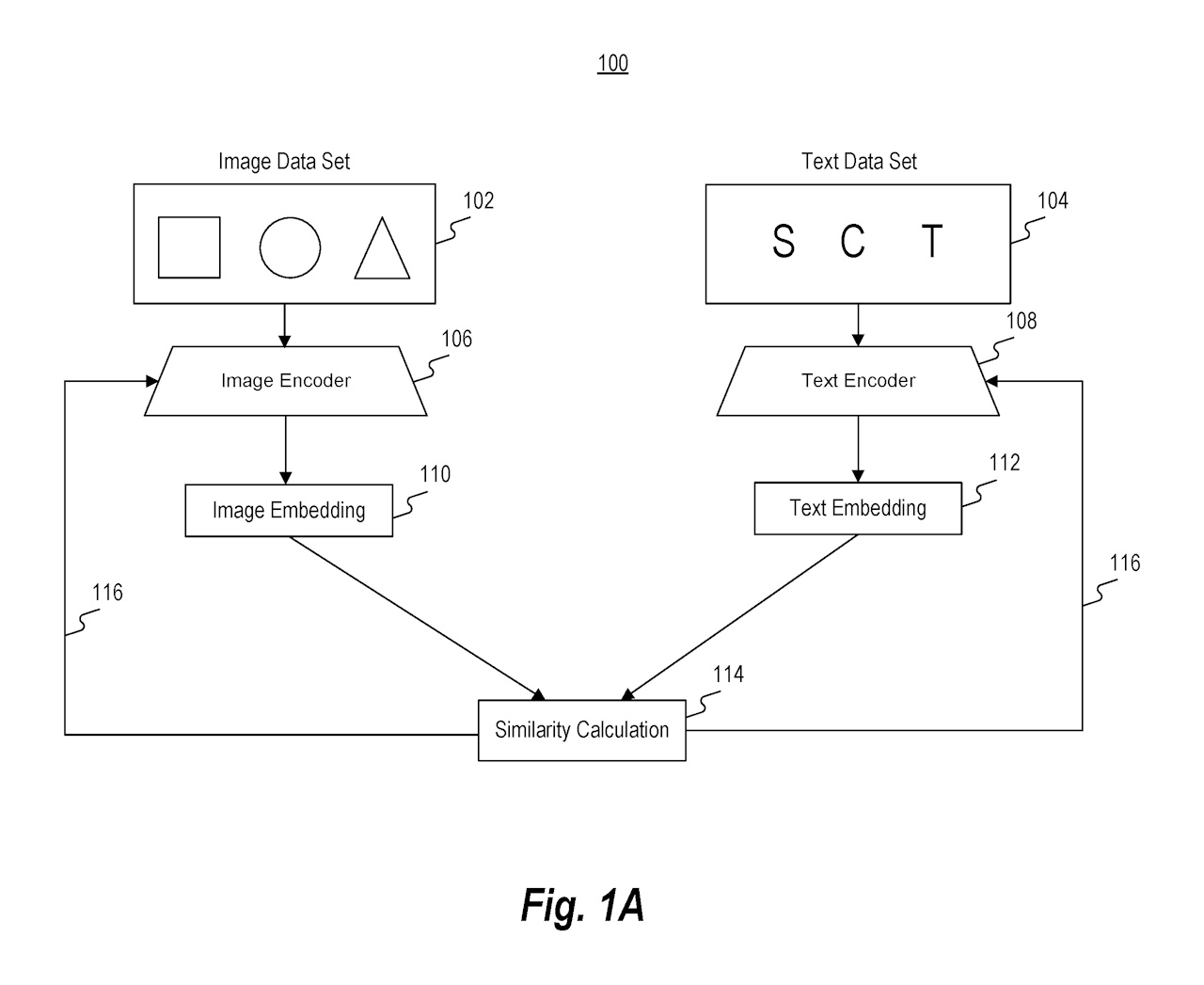
図1Aは、テキスト入力に対応する画像を生成するモデルをトレーニングするための機能ブロック図を示しています。まず、データベースから画像データセット102と対応するテキストデータセット104を収集します。これらのデータセットは、インターネットなどのデータソースに含まれています。画像データセットは画像エンコーダ106に入力され、テキストデータセットはテキストエンコーダ108に入力されます。これに基づいて、画像エンコーダとテキストエンコーダが共同でトレーニングされ、画像埋め込み110とテキスト埋め込み112が生成されます。これらの埋め込みは、デジタルまたは数学的な表現(ベクトル、行列など)を含みます。
トレーニングプロセスでは、画像埋め込みとテキスト埋め込みの間の類似性計算114が行われます。類似性計算は、主にコサイン類似度を使用して、画像とテキストのペアが正しく対応しているかを評価します。トレーニング中、エンコーダは反復的に更新され、正しいペアのコサイン類似度を増加させ、不正なペアのコサイン類似度を減少させます。
トレーニングが完了すると、生成された画像埋め込みとテキスト埋め込みは、デバイスや他の機械学習モデルで利用可能になります。テキスト記述にアクセスし、それをテキストエンコーダに入力してテキスト埋め込みを生成し、第1のサブモデルに入力します。このサブモデルは、テキスト記述やテキスト埋め込みを基に画像埋め込みを生成し、最終的に出力画像を生成するプロセスに貢献します。モジュール性により、サブモデルは他のモデルやステージと容易に交換でき、カスタマイズが可能です。
コサイン類似度について
コサイン類似度(Cosine Similarity)は、二つのベクトル間の類似度を測る指標の一つです。これは、二つのベクトルが成す角度のコサイン値を計算することで求められます。
具体的には、コサイン類似度は次の式で表されます:
Cosine Similarity = (A・B)/(‖A‖・‖B‖)
ここでA・Bは二つのベクトルの内積、‖A‖・‖B‖はそれぞれのベクトルの大きさ(ノルム)です。
コサイン類似度の値は -1 から 1 の範囲で、1 に近いほど二つのベクトルが同じ方向を向いていることを示し、0 に近いと直交している(無関係)ことを示し、-1 に近いと反対方向を向いていることを示します。
この指標は、特に文書やテキストの類似度を測る際に広く用いられます。例えば、テキストデータをベクトル化してコサイン類似度を計算することで、異なる文書間の内容の類似度を定量的に評価することができます。
図1Bは、本開示の実施形態に基づくテキスト入力に対応する画像生成の機能図を示しています。画像生成モデルのトレーニングは、画像エンコーダ134とテキストエンコーダ132のトレーニングを含みます。結合表現137は、テキスト埋め込み136と画像埋め込み135の潜在空間表現です。トレーニング完了後、テキストエンコーダ132と画像エンコーダ134は固定され、機械学習モデルの一部として使用されます。
画像生成リクエスト128は、情報の電子送信として入力/出力デバイス318に送信されます。ユーザーは、入力/出力デバイス318と対話することで画像生成リクエスト128を開始します。テキスト記述130に対応する画像を生成するプロセスは、テキスト記述130をテキストエンコーダ132に入力し、テキスト埋め込み136を生成することから始まります。このテキスト埋め込み136は、第1のサブモデル138への入力となります。
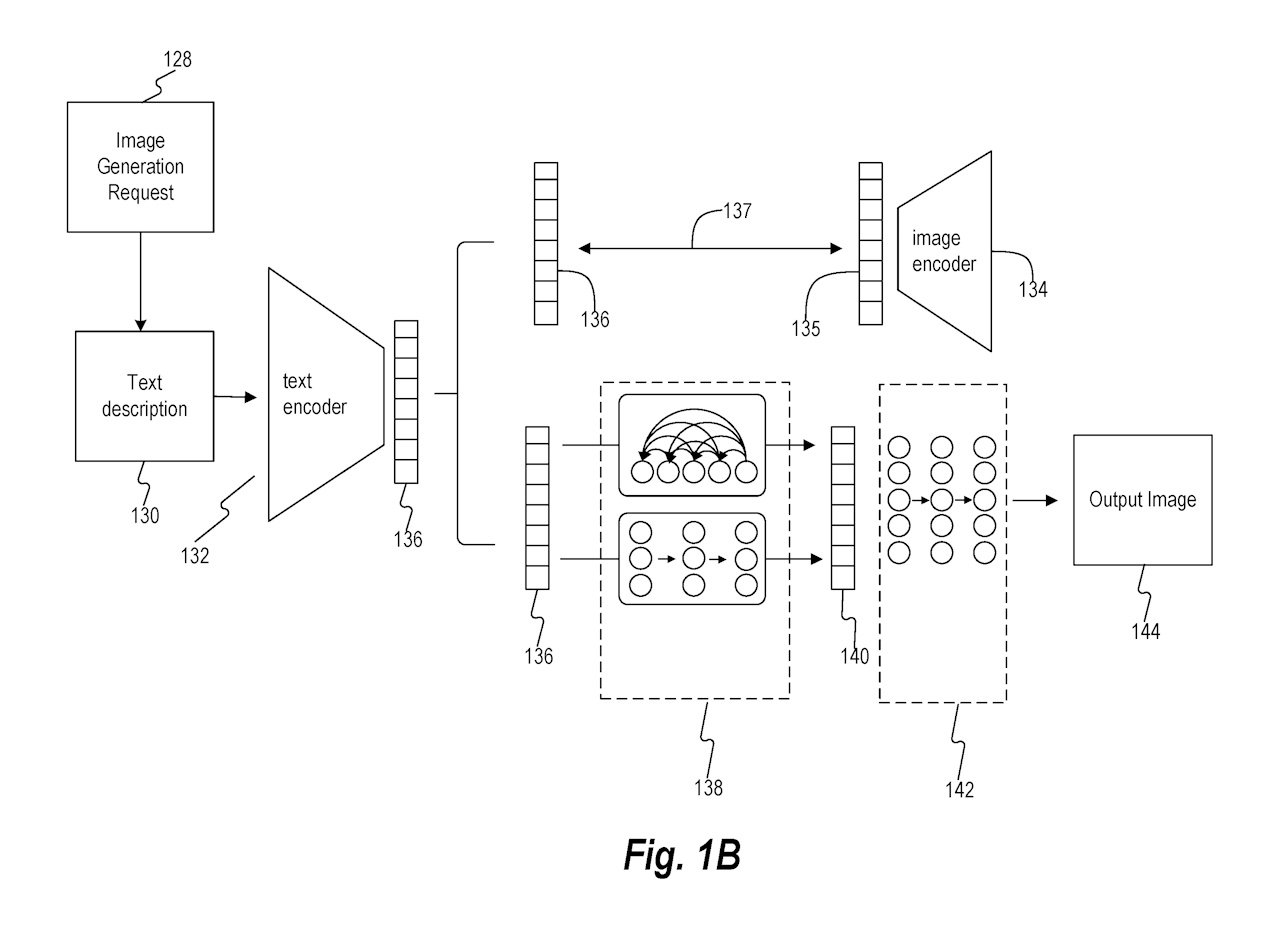
第1のサブモデルは、テキスト記述またはテキスト埋め込みに基づいて、対応する画像埋め込みを生成するように構成されています。サブモデルはモジュラー式であり、異なる機械学習手法を統合できます。第1のサブモデルは、複数のモデルクラスを使用して、テキスト埋め込み入力に基づいて対応する画像埋め込みを生成します。対応する画像埋め込みは、第1のサブモデルの出力として生成される画像埋め込みを表します。これらの対応する画像埋め込みは、テキストエンコーダと画像エンコーダの共同トレーニング中に生成される画像埋め込みとは異なる場合があります。
第1のサブモデルは、テキスト埋め込みおよびテキスト記述から画像埋め込みを生成する事前モデルを含みます。事前モデルは、異なる入力表現間を変換するように構成されています。例えば、事前モデルは、テキスト埋め込みと画像埋め込み間をマッピングできます。事前モデルは、入力の次元数を低減することもでき、この処理は他の操作を実行する前に行われます(例えば、主成分分析による低次元入力を用いるなどの手法が例示できます)。
図2は、テキスト入力に対応する画像を生成するための方法のフローチャートを示しており、以下のステップで構成されています。
ステップ202:テキスト記述にアクセス
最初に、システムはテキスト記述にアクセスします。このステップでは、テキスト記述を取得、リクエスト、受信、または取得するプロセスが含まれます。ユーザーが入力したテキストやリクエストに基づき、プロセッサがテキスト記述にアクセスします。
ステップ204:テキストエンコーダへの入力
次に、テキスト記述をテキストエンコーダに入力します。このエンコーダは、テキストを別の表現(デジタルまたは数学的表現)に変換し、テキストのパターンや関係性を保持します。具体的には、テキストエンコーダはニューラルネットワーク(例えば、トランスフォーマー)であり、テキストを数値、ベクトル、テンソル、または空間フォーマットにマッピングします。
ステップ206:テキスト埋め込みの生成
テキストエンコーダからテキスト埋め込みを受け取ります。テキスト埋め込みは、テキスト入力をベクトル表現にマッピングしたものです。
ステップ208:第1のサブモデルへの入力
テキスト記述またはテキスト埋め込みを第1のサブモデルに入力します。第1のサブモデルは、オートレグレッシブプライアや拡散プライアなどのモデルを含み、テキスト記述やテキスト埋め込みをトランスフォーマーでトークンとして符号化します。これにより、テキストや埋め込みのシーケンスを予測します。
ステップ210:画像埋め込みの生成
第1のサブモデルは、テキスト記述やテキスト埋め込みに基づいて対応する画像埋め込みを生成します。これにより、テキスト入力から得られる画像特徴の数値表現が作成されます。
ステップ212:第2のサブモデルへの入力
生成された画像埋め込みを第2のサブモデルに入力します。このサブモデルは、生成された画像埋め込みを受け取り、最終的な出力画像を生成するためのさらなる処理を行います。
ステップ214:出力画像の生成
第2のサブモデルは、テキスト記述または画像埋め込みに基づいて出力画像を生成します。このプロセスでは、画像データの操作や計算が含まれます。例として、生成逆対照ネットワーク(GAN)、畳み込みニューラルネットワーク(CNN)、変分オートエンコーダ(VAE)などが使用されます。
ステップ216:出力画像のアクセス
最終的に生成された出力画像をデバイスにアクセス可能にします。これは、ネットワークを通じた情報の送信、デバイスでの保存、デバイスへの通知などの形式で行われます。生成された画像は、ユーザーのリクエストに応じてアクセス可能になります。
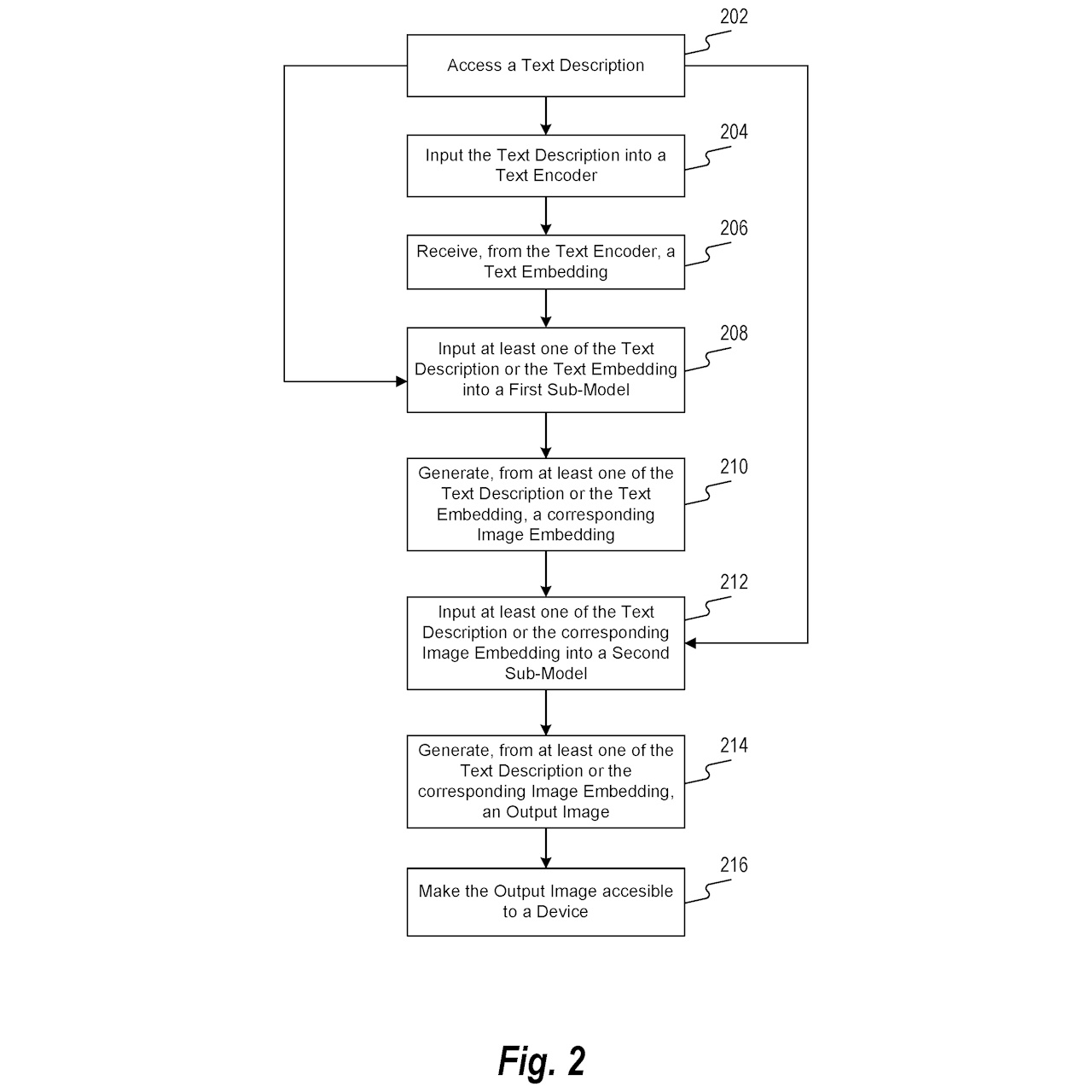
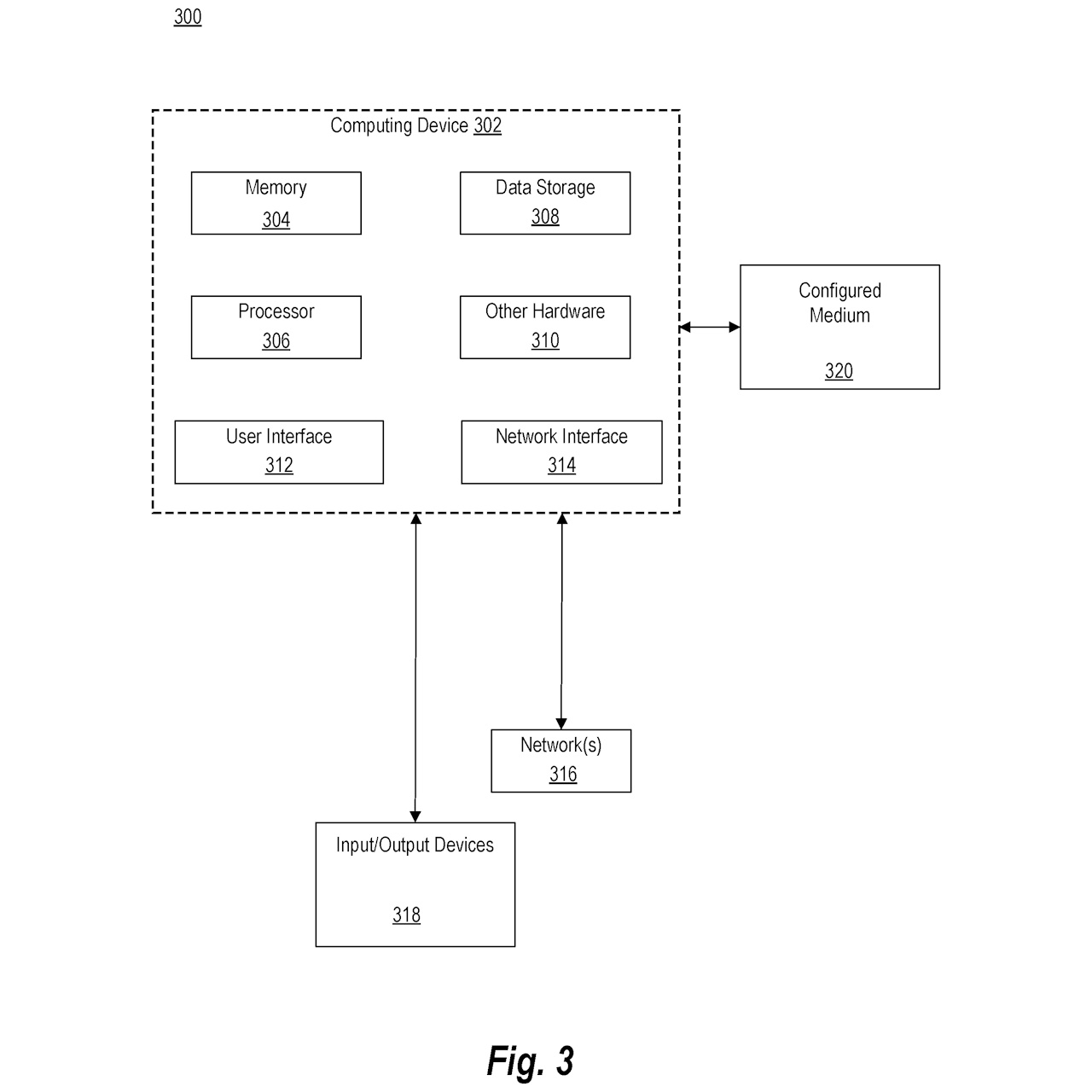
図3は、本開示の様々な側面を実装するための典型的なオペレーティング環境を示しています。図3に示されるように、オペレーティング環境300はコンピュータ形態の汎用コンピューティングデバイス302を含みます。コンピュータ302の構成要素には、プロセッサ306、データストレージ308、システムメモリ304、およびその他のハードウェア310が含まれます。システムバスを介して、これらのコンポーネントは相互にデータを送受信します。
コンピュータ302は、単一プロセッサまたは複数プロセッサを搭載したコンピュータデバイスです。オペレーティング環境300には、LAN、WAN、クライアントサーバーネットワーク、ピアツーピアネットワーク、またはクラウド内で通信可能にリンクされた複数のコンピューティングデバイスが含まれます。これらのコンピュータデバイスは、エンドユーザー向け、管理者向け、サーバーとして、分散処理ノードとして、または特殊目的の処理デバイスとして構成されており、機械学習モデルのトレーニングおよび使用が可能です。
ユーザーは、ディスプレイ、キーボード、マウス、マイク、タッチパッド、カメラ、センサーなどの入力/出力デバイス318を使用してコンピュータシステムと対話します。これらのデバイスは、システムバスを介してプロセッサ306およびメモリに接続されます。ユーザーインターフェース312は、ユーザーとシステムとの間のインタラクションをサポートします。ユーザーは、タブレット、電子デジタイザ、マイク、キーボード、ポインティングデバイス(マウス、トラックボール、タッチパッドなど)を通じてコマンドと情報を入力します。
コンピュータシステムは、ネットワーク316を介して他のデバイスと通信します。ネットワークインターフェース314は、ネットワークインターフェースカード(NIC)や仮想ネットワークインターフェース(VIF)などのネットワークインターフェース装置を含みます。コンピュータシステムは、プログラムモジュールをリモートメモリストレージデバイスに保存し、ネットワークを介して接続された複数のコンピューティングデバイスを含むことができます。
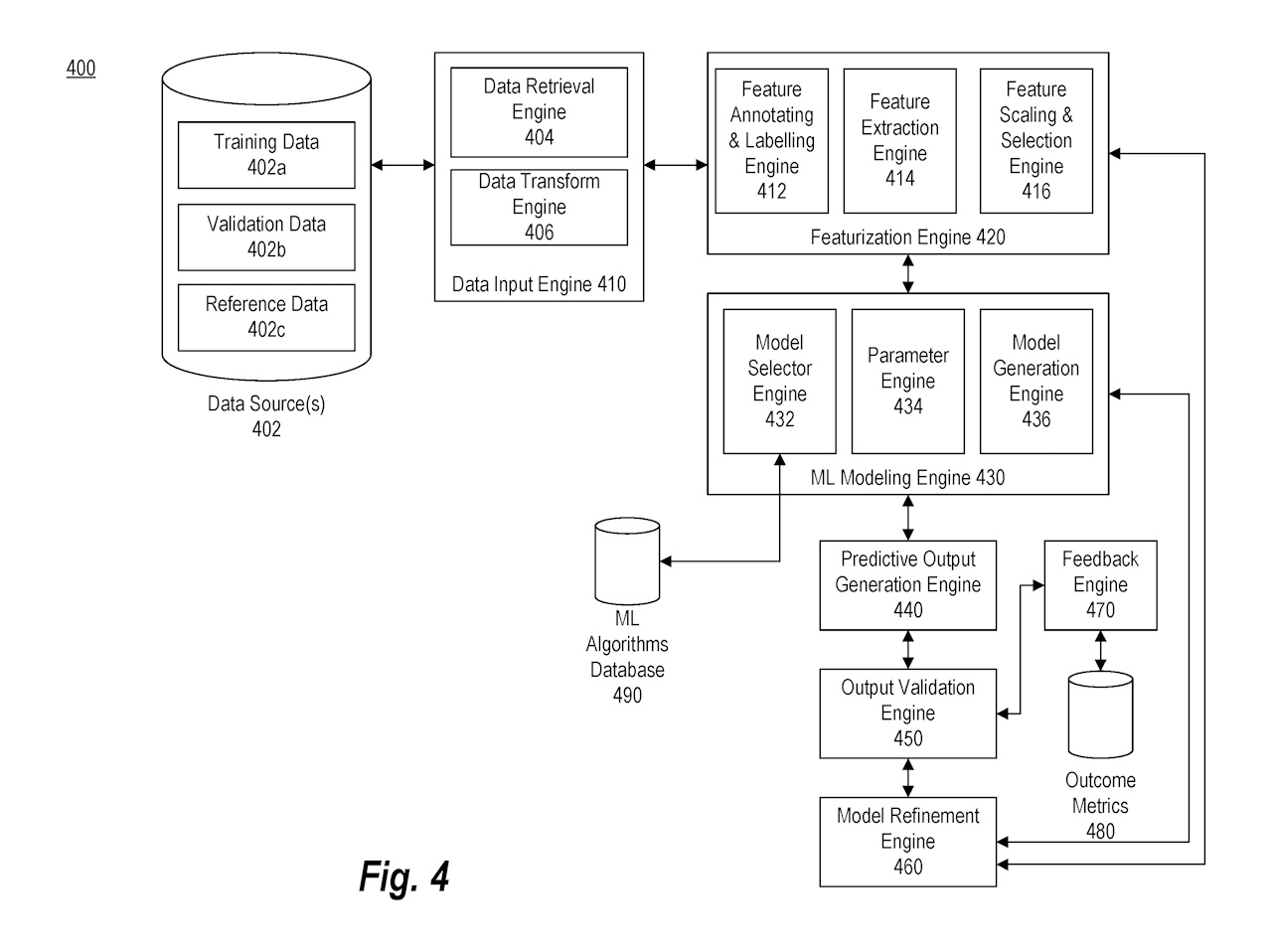
図4は、本開示の各種側面を実装するための典型的な機械学習プラットフォームを示すブロック図です。システム400は、データ入力エンジン410、特徴抽出エンジン420、機械学習(ML)モデリングエンジン430、予測出力生成エンジン440、出力検証エンジン450、フィードバックエンジン470、およびモデル精緻化エンジン460を含みます。データ入力エンジン410は、データ取得エンジン404とデータ変換エンジン406を含み、データソース402からデータを取得し、適切な形式に変換します。特徴抽出エンジン420は、特徴の注釈付け、抽出、スケーリング、選択を行います。MLモデリングエンジン430は、機械学習モデルのトレーニング、再構成、検証、テストを実行します。予測出力生成エンジン440はモデル出力を生成し、出力検証エンジン450がその出力を検証します。フィードバックエンジン470はユーザーや機械からのフィードバックを受け取り、モデル精緻化エンジン460がモデルを更新・再構成します。システム全体が分散処理や負荷分散を通じて効率的に動作します。
ここがポイント!
この特許の重要なポイントは、テキスト入力に基づいて高品質な画像を生成するためのシステムおよび方法の革新にあります。
1. テキストエンコーダと画像エンコーダの共同トレーニング
本発明は、テキストエンコーダと画像エンコーダを共同でトレーニングすることにより、テキストの意味を正確に捉え、それを基に画像を生成します。テキストエンコーダはテキスト入力を多次元ベクトルに変換し、画像エンコーダはそのベクトルを用いて画像埋め込みを生成します。これにより、テキストの意味を忠実に反映した画像を生成することが可能になります。
2. 高品質な画像生成
従来のシステムが低品質な画像を生成する問題を解決するため、本発明は高解像度で視覚的に魅力的な画像を生成する技術を提供します。これにより、生成される画像の実用性と視覚的な魅力が向上します。
3. 効率的なプロセス
本発明は、訓練と画像生成のプロセスを効率化することで、時間とリソースの節約を実現します。これは、従来のシステムが持つ非効率性の問題を克服するための重要な改善点です。
4. 多様な画像生成
一つのテキスト入力に対して複数のバリエーションを持つ画像を生成する能力により、ユーザーの多様なニーズに対応します。これにより、さまざまな用途に適した画像生成が可能となります。
5. フィードバックと精緻化
フィードバックエンジンを通じてユーザーからのフィードバックを収集し、モデル精緻化エンジンがそのフィードバックに基づいてモデルを更新・改善します。これにより、継続的なモデルの改善と適応が可能となります。
6. モジュール式アーキテクチャ
本発明は、モジュール式のアーキテクチャを採用しており、異なる機械学習手法やモデルを容易に統合できます。これにより、システムの柔軟性とカスタマイズ性が向上します。
7. 拡散モデルとオートレグレッシブモデル
第1のサブモデルには拡散モデルやオートレグレッシブモデルが含まれ、これらのモデルがテキスト埋め込みやテキスト記述を基に画像埋め込みを生成します。これにより、より多様で高品質な画像生成が可能になります。
8. エッジデバイスとの互換性
本発明のシステムは、エッジデバイスやクラウド環境での実装にも適しており、分散処理や負荷分散を通じて効率的に動作します。
これらのポイントにより、本発明はテキスト入力に基づく画像生成技術において重要な進歩を遂げ、従来のシステムの限界を克服することを目指しています。
未来予想
この特許発明の技術が広く実用化されることで、未来には多くの革新が期待されます。
まず、映画やゲーム、広告、デザインなどのクリエイティブ業界では、テキストを入力するだけで高品質なビジュアルコンテンツを迅速に生成できるようになり、制作時間が短縮され効率が大幅に向上します。また、教育分野でも教材作成に革命をもたらし、教科書や学習資料に視覚的な補完を加えることで学習効果が高まるでしょう。
Eコマースやマーケティングの分野では、商品説明文から即座に商品画像を生成することで、商品の視覚的な訴求力が向上し、購買意欲を高めることができます。これにより、消費者に対してよりパーソナライズされたマーケティング戦略が可能となり、販売促進につながるでしょう。
人工知能の進化に伴い、この技術は他のAIシステムと連携して、より高度な知識生成や意思決定支援システムを構築する基盤となります。自然言語処理と画像生成技術の統合により、AIの理解力と応答性が大幅に向上し、複雑なタスクをより効果的にこなせるようになります。
ユーザーインターフェースにおいても、この技術は大きな変革をもたらします。インタラクティブなアプリケーションやバーチャルアシスタントは、ユーザーのテキスト入力に基づいて即座にビジュアルフィードバックを提供し、より直感的なユーザーエクスペリエンスを実現します。これにより、ユーザーはより自然で効果的な方法でシステムと対話できるようになります。
さらに、ニュース記事やブログ、ソーシャルメディアの投稿などのコンテンツ生成の自動化が進化し、コンテンツクリエーターの負担を軽減し、質の高い情報提供が容易になります。例えば、ニュース記事の要約やブログの補完画像の自動生成などが挙げられます。
このように、この特許発明の技術は、多岐にわたる分野で革新的な変化をもたらし、効率性と創造性を高めるとともに、新たなビジネスモデルやサービスの創出を促進する可能性があります。結果として、社会全体の生産性が向上し、さまざまな業界での技術革新が加速する未来が予想されます。
特許の概要
|
発明の名称 |
Systems and methods for hierarchical text-conditional image generation |
|
出願番号 |
18/193,427 |
|
特許番号 |
US11922550B1 |
|
優先日 |
2023年3月30日 |
|
登録日 |
2024年3月5日 |
|
出願人 |
Open AI Opco LLC |
|
発明者 |
Aditya Ramesh |
| 国際特許分類 |
G06T11/60 |
| 経過情報 |
予測される有効期限:2043年3月30日 |