はじめに
生成AIの急速な進化は、かつて自然言語処理(NLP)の領域にとどまっていたAIの活用を、視覚・音声・動作といったマルチモーダル領域へと拡張している。その最前線に立つのがOpenAIだ。同社は大規模言語モデル(LLM)に画像処理機能を統合し、次世代の知的エージェントの中核となる技術群を急速に開発している。本稿では、OpenAIの公開特許と技術動向を分析し、画像系AIとLLMの融合に向けた戦略、及びその社会的インパクトについて掘り下げる。
特許から見る融合の方向性
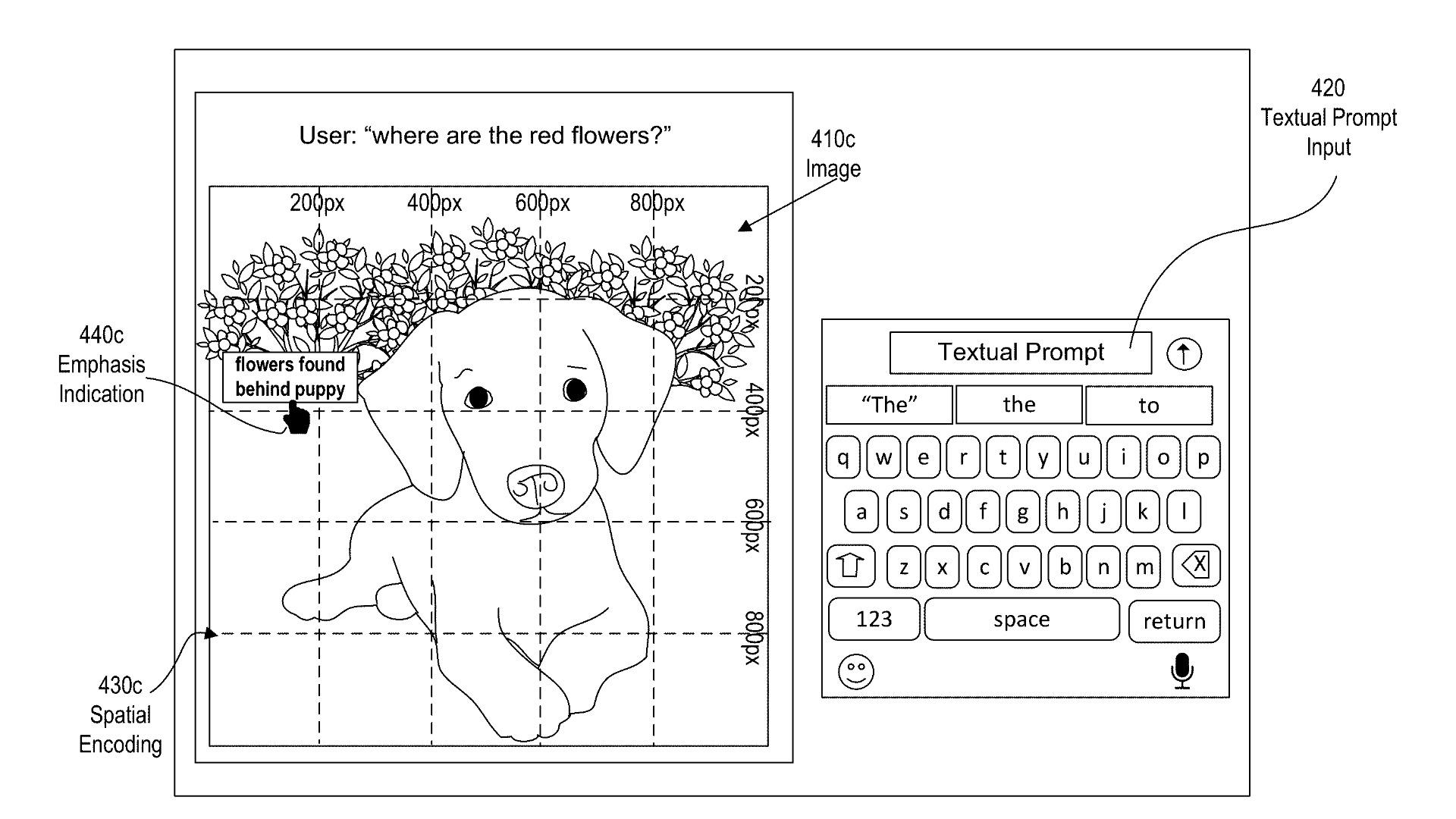
OpenAIが近年出願した複数の特許からは、画像認識、視覚的質問応答(Visual Question Answering: VQA)、画像キャプション生成、マルチモーダル推論といった分野での技術的進展が見て取れる。たとえば、2023年に出願された「画像とテキストのクロスモーダル表現の生成装置」に関する特許では、視覚情報とテキストを同時にエンコードするアーキテクチャが記載されている。これにより、単なる画像認識ではなく、「画像内で何が起こっているか」「なぜそうなっているのか」といった文脈的理解を可能にしている。
この種の融合モデルは、従来の画像分類や物体検出を超え、LLMが持つ言語的常識や論理的推論力を画像理解に持ち込むことを目的としている。つまり、AIが視覚的な情報を単に「見る」のではなく、「解釈し、意味を語る」能力を獲得するのだ。
GPT-4Vとその意味
OpenAIがリリースしたGPT-4V(Vision)は、画像を入力として受け取り、テキストで出力するマルチモーダルモデルの実用的な到達点である。従来のLLMに画像機能を統合するというアプローチの一環で、特許上もこの方向性を補強する仕組みが多く見られる。具体的には、画像特徴量をトークン列に変換し、それをLLMの入力に連結する構成や、注意機構によりテキストと画像を横断的に処理する設計が採用されている。
これにより、例えば以下のような高度なタスクが可能になっている:
-
手書きメモや図を読解してテキスト化・要約
-
医療画像からの異常検出と所見生成
-
商品画像に基づいたECコンテンツの自動生成
-
写真の内容に対する質問応答(例:「この写真の人物は何をしている?」)
こうした進化の裏側には、OpenAIが出願してきた「自己教師あり学習」「画像とテキストの整合性学習」「視覚的注意機構の最適化」などの技術がある。
画像系AIの独自性と課題
画像処理に特化したAIモデル(例:CLIP、DALL·E、Whisper)は、それぞれ音声・視覚・生成といったモダリティの個別領域で高い性能を持つ。一方で、これらを統合する際には次のような課題が浮かび上がる:
-
表現の整合性:画像とテキストの意味構造が一致しない場合、推論が誤るリスクがある。
-
データの不足:特に高品質なマルチモーダルデータの収集は困難であり、教師ありデータの限界がモデル性能に影響する。
-
計算コストの高さ:画像処理は言語処理よりも多くの計算資源を必要とし、モデルのスケーリングに制約を生む。
OpenAIはこれらの課題を回避するため、例えばCLIPのような「コントラスト学習による画像と言語の埋め込み共有」や、自己回帰的デコーダを持つ統一型アーキテクチャ(例:GPT-4系列)などを採用している。
社会実装と未来のユースケース
このような技術はすでに社会に実装され始めている。たとえば、視覚障害者向けのAI補助アプリ、写真を基にレシピやライフスタイルの提案をする家庭用アシスタント、またビジネスにおけるプレゼン資料や会議記録の自動化といった応用が進んでいる。
将来的には、以下のような領域での展開が想定される:
-
教育:図解付き教材の自動生成、視覚的コンテンツに対する双方向学習支援
-
医療:画像診断と問診記録の統合によるAIドクターの高度化
-
セキュリティ:監視カメラ映像の文脈的理解と行動予測
-
クリエイティブ産業:構図やトーンを理解した画像生成AIとの共同制作
これらはいずれも「AIが見るだけでなく、考える」世界観の延長線上にある。
おわりに:融合の本質は「意味の共有」
OpenAIが目指す画像系AIとLLMの融合は、単なる機能の統合ではない。それは「意味の共有」「文脈の理解」という、より人間的な知能の獲得に近づくための重要なステップである。特許情報からも明らかなように、OpenAIはこの融合を技術の中心戦略と位置付けており、今後の展開次第では社会のあらゆる分野にインパクトを与える可能性がある。
画像とテキストが同じ「文脈空間」で語られる世界―そこには、単なる便利さを超えた新たな創造の可能性が広がっている。