月間特許トレンドウォッチ
マクドナルドのAIを活用したCM「#AIポテト」は、その革新的な映像技術で大きな注目を集めました。このCMでは、AIによってポテトが次々と異なる形に変化し、視覚的にユニークな演出が施されています。従来の映像制作では手間がかかるような複雑なビジュアルを、AIがリアルタイムで生成することが可能になっており、この技術の進化が広告業界にも大きな影響を与えています。
AI♡ポテト#月曜からポテトML250円#AIラブポテト
— マクドナルド (@McDonaldsJapan) August 17, 2024
※タップしてご覧ください pic.twitter.com/WFOUmHeJ0c
マクドナルドの「#AIポテト」CMは、AI技術を駆使した動画生成の革新を象徴する例となっていますが、これを実現する背景には、近年急速に発展しているAI動画生成サービスの進化が存在します。特に、Neural Radiance Fields(NeRF)のような高度な技術は、リアルタイムで複雑な3D空間を構築することが可能であり、これが視聴者により没入感のある映像体験を提供しています。この技術は、マクドナルドのCMだけでなく、映画やゲーム、バーチャルリアリティ(VR)の分野でも活用が広がっています。
さらに、他にも有名なAI動画生成サービスとして、Runway MLやSynthesiaなどがあります。Runway MLは、クリエイター向けに簡単にAIを使って映像やアニメーションを生成できるプラットフォームで、映画や広告制作において利用されています。特に、「AI Magic Tools」と呼ばれる一連のツールを使って、ユーザーはわずかな指示で複雑な動画を生成できる点が大きな特徴です。一方で、Synthesiaは、AIによるリアルな人間のアバターを用いて、簡単に動画コンテンツを作成できるサービスで、企業のトレーニングビデオやマーケティング動画に活用されています。
これらのサービスが提供する技術は、従来の動画制作のプロセスを大きく変革しつつあります。特に、低コストでスピーディに動画を生成できる点が企業にとっての魅力となり、AI技術がクリエイティブな分野での新たな可能性を生み出しています。動画生成AIの現状を踏まえると、今後さらに多くの分野での応用が期待され、技術の進化と共にその影響力は拡大していくでしょう。
しかし、このCMが話題を集める一方で、SNS上では一部で炎上が発生しました。AI技術によるポテトの描写に対して「不自然で親しみにくい」という意見が寄せられ、一部の視聴者にはAIによる生成物が受け入れられにくい面も浮き彫りになりました。これは、AI技術の急速な発展に伴い、消費者の感情や受け入れ方にも慎重に配慮する必要があることを示しています。
AIによる動画生成技術は、今後さらに進化し、広告業界のみならず映画やエンターテインメント、教育など幅広い分野で活用される可能性があります。一方で、その技術が持つ影響力をどのように活かし、視聴者との共感を得られる表現を追求するかが、企業にとっての新たな課題となっていくでしょう。今後もAI技術をうまく取り入れつつ、視聴者の心をつかむクリエイティブなコンテンツが求められています。
パテントディスカバリー

動画生成技術が進化する中、エンターテインメントや教育分野だけでなく、医療やヘルスケアにもその波が押し寄せています。本特許が提案する技術は、AIを活用して複数の動画を合成し、ユーザーのニーズに応じた高品質なコンテンツを生成するものです。この技術は、ユーザーに適切なガイドを提供しながら、迅速かつ効率的に動画を作成できることを目指しています。
特に、動画に含まれる人物の表情や動作、カメラの動きまでを自動的に分析し、最適なコンテンツを作成するプロセスは、今後の映像制作やユーザー生成コンテンツ(UGC)の分野に大きな影響を与えるでしょう。本コラムでは、この特許技術がどのようにして革新的な動画生成を可能にし、その応用範囲がどこまで広がるのかを探っていきます。

発明の背景
近年、動画生成技術は急速に進化しており、特にエンターテインメントや広告、ソーシャルメディアの分野において、その重要性が増しています。しかしながら、従来の動画生成手法は、高度な専門知識や高価な設備を必要とするため、多くのユーザーにとって敷居が高いものでした。また、動画制作プロセスには多大な時間と労力がかかり、特に個人や小規模なチームにとっては負担が大きいことが問題となっていました。
従来の手法におけるもう一つの課題は、ユーザーが自分で撮影した動画を他の動画と組み合わせたり編集したりする際、そのプロセスが複雑であり、思い通りの結果を得ることが難しい点です。例えば、複数の動画を合成して一つのコンテンツを作成する場合、シームレスに統合するためには、映像の品質やタイミングの調整など、多くの技術的な調整が必要となります。これらの課題は、特に技術に詳しくないユーザーにとって、動画制作の障壁となっていました。
さらに、動画の品質向上が求められる中で、従来の動画合成技術では、ユーザーが期待する高い品質を提供することが難しいケースがありました。特に、ユーザーが動画内で特定のキャラクターやエフェクトを追加したり、他の動画との連携を行う際、そのプロセスが煩雑であり、結果としてユーザーの満足度が低下する可能性がありました。
このような背景を踏まえ、動画生成技術の革新が求められています。特に、ユーザーが手軽に高品質な動画を作成できるような技術が必要とされています。また、動画合成プロセスにおいても、ユーザーの操作を支援するためのインターフェースや、AI技術を活用した自動化機能が求められています。ユーザーが複雑な操作を行うことなく、簡単にプロフェッショナルな仕上がりの動画を作成できることが大きな課題でした。
どんな発明?
発明の目的
本発明の目的は、ユーザーが複数の動画を効率的かつ高品質に合成し、直感的な操作でプロフェッショナルな仕上がりの動画を生成できるようにすることです。この技術の具体的な目標は、従来の動画生成や編集における煩雑さやコストを軽減し、より多くのユーザーが簡便に動画コンテンツを作成できる環境を提供することにあります。
さらに、この発明は、深層学習やAI技術を活用して、ユーザーが動画撮影時に最適なガイダンスを得られるようにし、ミスを減らしつつ効率的に動画を生成することも目的としています。具体的には、ユーザーが撮影した動画を既存の動画とシームレスに組み合わせ、自然な流れで合成動画を作成できることを目指しています。また、ユーザーの操作を支援するために、ガイドメッセージやリアルタイムの編集機能を提供することで、動画生成プロセス全体を簡便にし、ユーザーエクスペリエンスを向上させることも重要な目的の一つです。
このように、この特許発明の目的は、技術的な障壁を取り除き、ユーザーが創造的なコンテンツを容易に作成できるようにすることにあります。
発明の詳細
【目的】
ユーザーが直感的に高品質な動画を生成できるようにし、撮影コストを削減すること。
【対象】
動画撮影および編集に関わるすべてのユーザー、特に専門知識がないユーザーでも簡単に使用できること。
動画生成方法
• トリガー操作の取得
ユーザーが動画合成オプションを選択すると、カメラが起動して撮影が開始されます。この操作は、ユーザーが直感的に選択できるよう設計されています。
• ガイドメッセージの表示
撮影中に、第一動画(既存の動画)に基づいて撮影ガイドメッセージが表示されます。このガイドは、ユーザーに適切な撮影指示を提供し、撮影ミスを最小限に抑えることを目的としています。提示されるガイドメッセージには、以下のような要素が含まれます。
• カメラの適切な撮影方法
• ユーザーの顔の向きや表情
• 肢体の動きやポーズ
• 第二動画の取得と合成
ユーザーが撮影した新しい動画(第二動画)は、既存の第一動画と組み合わせて処理されます。この合成プロセスでは、第一動画内の特定のキャラクターやシーンを第二動画で置き換えます。具体的な処理の例としては、次のようなものがあります。
• 第一動画内のキャラクターが他のキャラクターと同じシーンに含まれている場合、そのキャラクターの顔をユーザーの顔に置き換える。
• シーンごとの動作や表情を調整し、動画のシームレスな統合を実現する。
動画生成装置
• 第一処理モジュール
動画合成オプションを選択し、カメラを起動する機能を提供します。これはユーザー操作の初期段階でのインターフェースを担当します。
• 取得モジュール
第一動画を元に、適切な撮影ガイドを生成するためのデータを取得します。このモジュールは、AIや機械学習を活用し、ユーザーに最適な撮影指示をリアルタイムで提供します。
• 第一表示モジュール
撮影中に、画面上にガイドメッセージを表示する役割を担います。このモジュールは、ユーザーに対して視覚的なフィードバックを提供し、撮影プロセスをサポートします。
• 第二処理モジュール
新しく撮影された第二動画を処理し、既存の第一動画と統合します。この際、ユーザーが選択したキャラクターやシーンを分析し、シームレスに合成するための処理が行われます。例えば、第一動画内でキャラクターが複数登場する場合、その中からユーザーが選択したキャラクターのシーンを抽出し、置き換えます。
AIおよび機械学習の活用
• 人体姿勢検出ネットワーク
動画内のキャラクターの動きや表情を解析するために、AI技術を活用します。具体的には、以下のような処理が行われます。
• 顔の構造モデルの生成
キャラクターの顔の位置関係を解析し、顔の動きや表情をモデル化します。これにより、キャラクターの顔をユーザーの顔に自然に置き換えることが可能になります。
• 肢体の動作解析
キャラクターの肢体の動きを解析し、それに基づいてシーンの動作を調整します。
ユーザーインターフェースの工夫
• 複数のキャラクターオプション
ユーザーが撮影前に選択できるキャラクターオプションを表示し、選択したキャラクターに基づいて動画を合成します。
• プレビュー機能
合成された動画のプレビューを表示し、ユーザーが結果を確認し、必要に応じて修正できるようにします。
• リアルタイムの修正機能
動画生成後でも、ユーザーが簡単に動画を修正できるよう、インターフェースに修正オプションを提供します。
【技術的詳細と有益な効果】
・動画撮影の効率化と品質向上
ユーザーが動画合拍オプションを選択すると、カメラが自動的に起動し、動画撮影が開始されます。撮影中には、第一動画(既存の動画)に基づいて生成されたガイドメッセージが表示され、ユーザーはその指示に従って撮影を進めることができます。これにより、撮影のスピードが向上し、高い撮影品質が実現されます。
・ガイドメッセージの利用
撮影中のガイドメッセージは、ユーザーに対して適切な撮影方法や表現方法を示し、迅速かつ高品質な動画撮影を支援します。たとえば、カメラのアングルや被写体の動きについての具体的なアドバイスが含まれます。これにより、動画の内容が一貫性を持ち、ユーザーの意図に沿った結果が得られます。
・動画の合成処理
撮影が完了すると、システムは第二動画(新しく撮影された動画)を第一動画と組み合わせて合成します。このプロセスでは、ユーザーが選択したキャラクターやシーンが自然に統合され、最終的な合成動画が生成されます。この合成プロセスにより、ユーザーは動画の内容に深く関与し、より個性的な動画を作成することが可能になります。
・AIと機械学習の活用
この技術では、AI技術や機械学習を用いて、動画内のキャラクターの動きや表情を解析します。例えば、人体の姿勢や表情を検出するためのアルゴリズムが導入されており、それに基づいて最適な撮影ガイドを提供します。この結果、よりリアルで自然な動画が生成されます。
・クラウド技術の利用
このシステムは、クラウド技術を活用して、撮影データの処理やストレージを効率化しています。クラウドサーバーを利用することで、ユーザーは高い処理能力を必要とせず、手軽に高品質な動画を生成できます。また、複数の端末からのアクセスやデータ共有も容易になります。
以下では主要な図面を参照しながら、さらに深堀りしていきます。
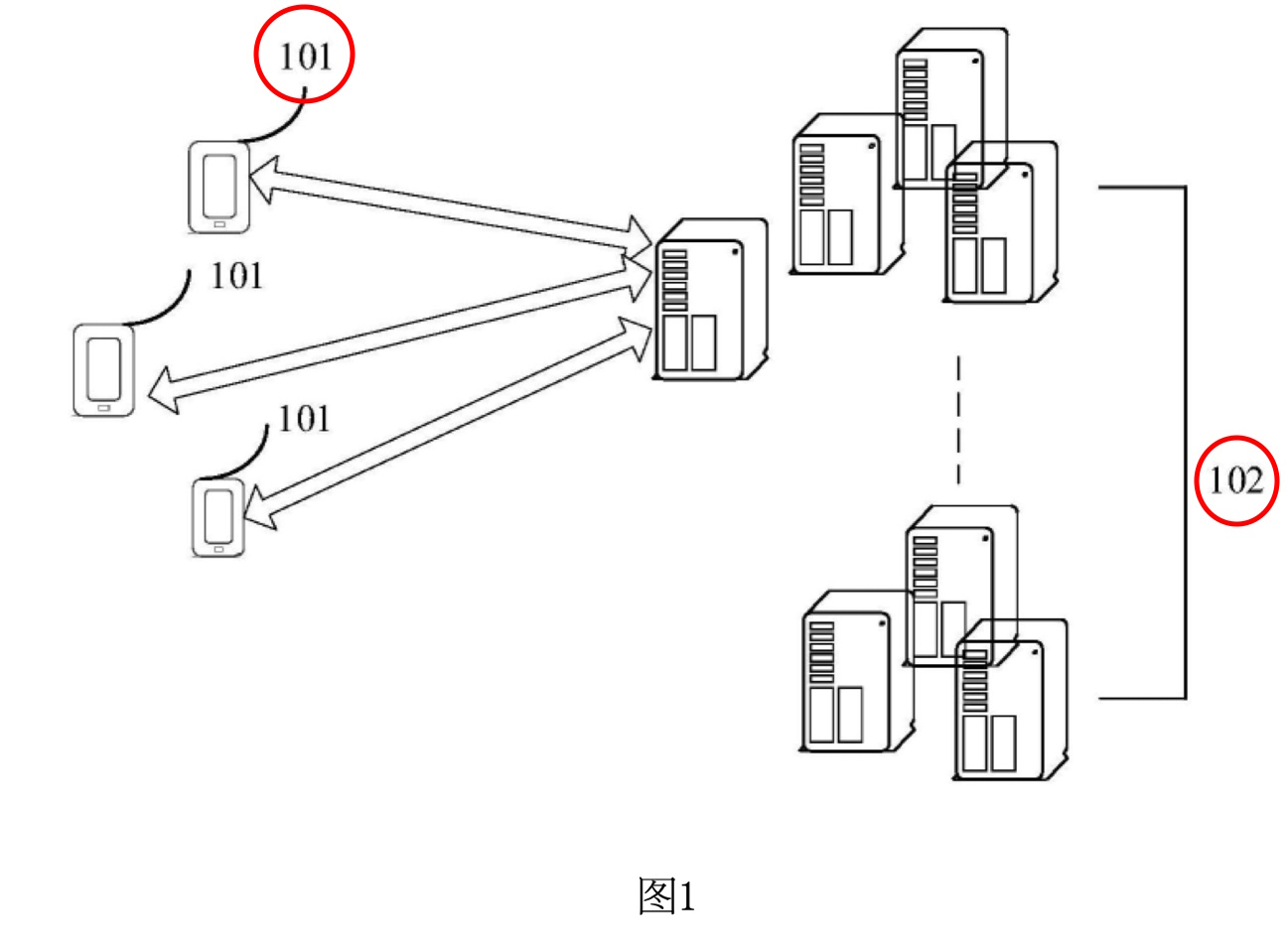
図1は、この特許発明における動画生成方法の実施環境を示しています。この図では、主要な構成要素として、端末101とサーバ102が含まれています。
•端末101: これは主にユーザーが使用するデバイスで、スマートフォン、タブレット、ノートパソコン、電子書籍リーダー、MP3プレーヤー、MP4プレーヤーなど、さまざまなモバイルデバイスを指します。この端末は、動画を撮影し、サーバ102との通信を行います。端末101は、動画生成方法の実行において重要な役割を果たし、ユーザーインターフェースを通じて動画の編集や合成などの操作を実行します。
•サーバ102: サーバ102は、クラウド技術に基づくシステムであり、独立した物理サーバ、サーバクラスター、または分散システムで構成されます。このサーバは、クラウドサービスやクラウドデータベース、クラウドコンピューティング機能を提供し、端末101と連携して動作します。具体的には、サーバ102は動画の保存、処理、分析を行い、端末101に対してリアルタイムなフィードバックやガイドを提供します。
この実施環境において、端末101とサーバ102は、有線または無線通信によって接続されており、ユーザーが撮影した動画の処理を効率的に行います。また、動画生成方法は、端末101とサーバ102が連携して動作する形態だけでなく、端末101単独で実行することも可能です。特に端末101が強力な計算処理能力を持つ場合には、サーバを介さずに動画処理を行うことができます。
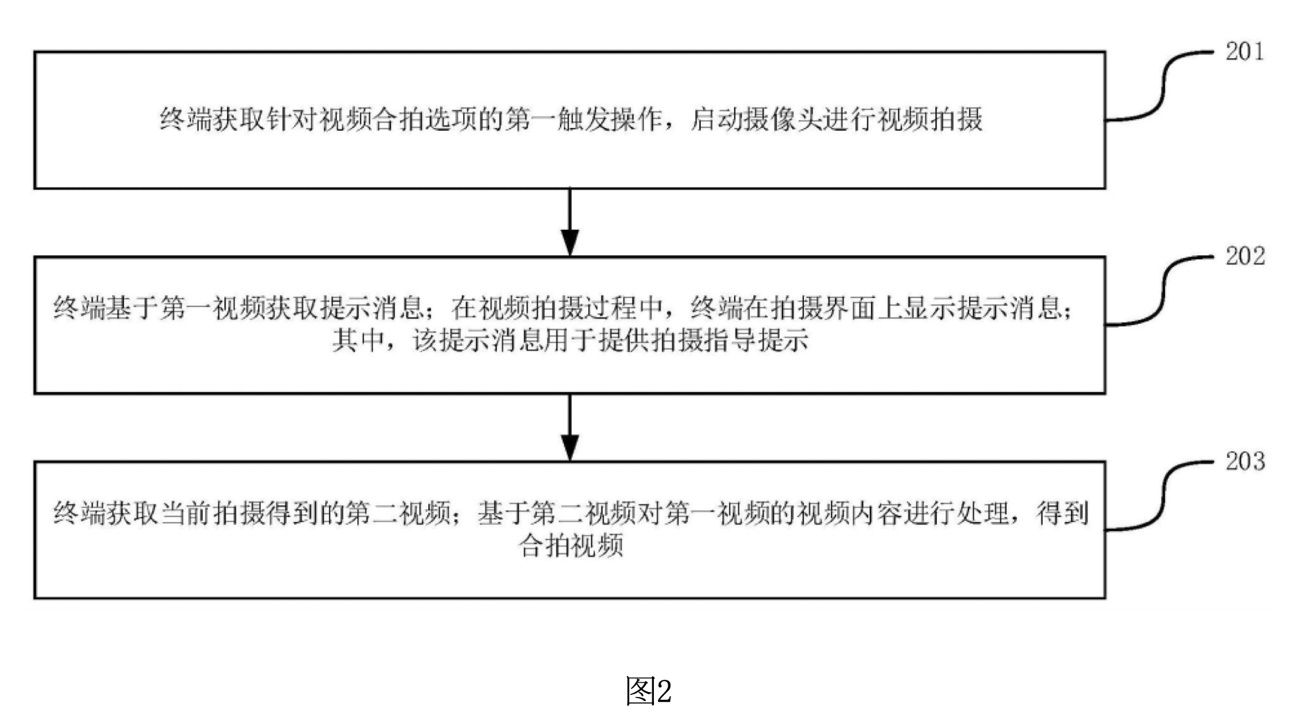
図2は、この特許発明の動画生成方法に関するフローチャートです。この図では、動画生成方法の主要なステップが示されています。
1. ステップ201:
第一トリガ操作の取得とカメラの起動: このステップでは、端末が動画合拍オプションに対するユーザーの第一トリガ操作(例えば、画面上の「動画撮影を開始」ボタンを押す操作)を取得します。トリガ操作を受けると、端末は自動的にカメラを起動し、動画撮影を開始します。これは、ユーザーが手軽に撮影を開始できるように設計されています。
2. ステップ202:
ガイドメッセージの取得と表示: 撮影が進行中の間、端末は第一動画(既存の動画)の内容に基づいてガイドメッセージを取得し、それを撮影インターフェースに表示します。これにより、ユーザーは提示された指示に従い、適切な撮影を行うことができます。提示されるガイドメッセージには、カメラの撮影モード、キャラクターの位置や動作に関する指示が含まれます。
3. ステップ203:
第二動画の取得と合成: 現在撮影された動画(第二動画)が取得され、その後、第一動画(既存の動画)の内容に基づいて合成処理が行われます。最終的に、合成された合拍動画が生成されます。この合成プロセスでは、ユーザーが選択したキャラクターやシーンが自然に統合され、シームレスな動画が作成されます。
このフローチャートでは、ユーザーが操作するプロセスの流れが明確に示されており、どのようにして最初の動画から新しい動画が生成されるのかを理解するための助けとなります。各ステップは、ユーザーが直感的に操作できるように設計されており、撮影から編集、合成までのプロセスを効率化します。
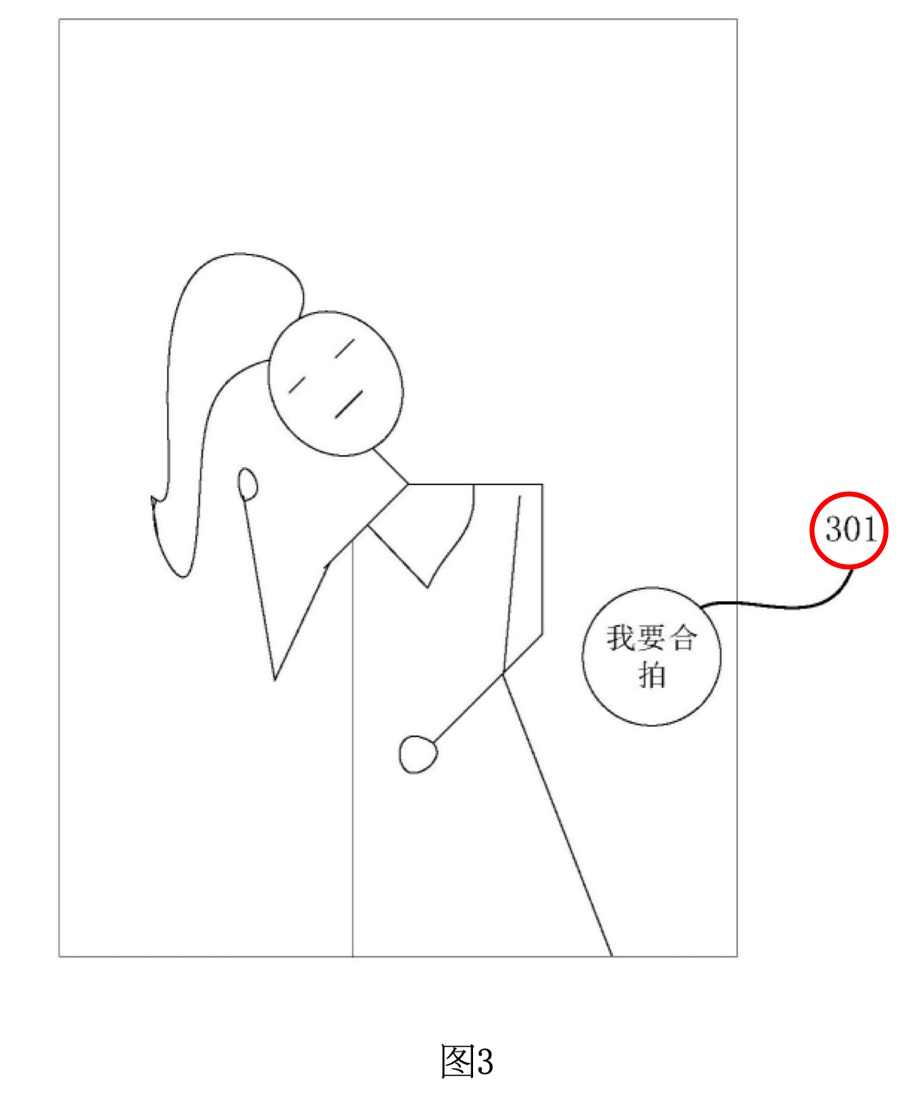
図3は、ユーザーが動画を再生する際のインターフェースを示しています。この図では、再生中の動画上に「動画合拍オプション301」が表示されています。
(筆者注) 「合拍(ごうはく)」は、特に中国語でよく使われる表現で、文字通りには「一緒に撮影する」や「共演する」という意味を持ちます。この文脈では、既存の動画や映像に対して、新たに追加された撮影部分を組み合わせることを指します。日本語ではこれに対応する一般的な用語が存在しないため、「共同撮影」や「共演動画作成」などと訳すことができます。
動画合拍オプション301: これは、ユーザーが動画の一部を自分で撮影したい場合に選択するオプションです。このオプションを選択することで、ユーザーは既存の動画に対して自分自身の撮影動画を追加することができます。このオプションは、動画の再生中に表示され、ユーザーに対して「この動画に参加して撮影することができる」というインタラクションの機会を提供します。
配置と表示: 動画合拍オプション301は、再生インターフェースの端、たとえば右側や下部に配置されることが一般的です。これにより、動画の再生画面を過度に覆うことなく、ユーザーがオプションを簡単に選択できるようにしています。図3では、オプション301は再生インターフェースの右下に表示されています。
ユーザーインタラクション: ユーザーが動画合拍オプション301をクリックすることで、動画撮影の準備が開始されます。この操作は、次のステップで動画撮影に移行するためのトリガとして機能します。
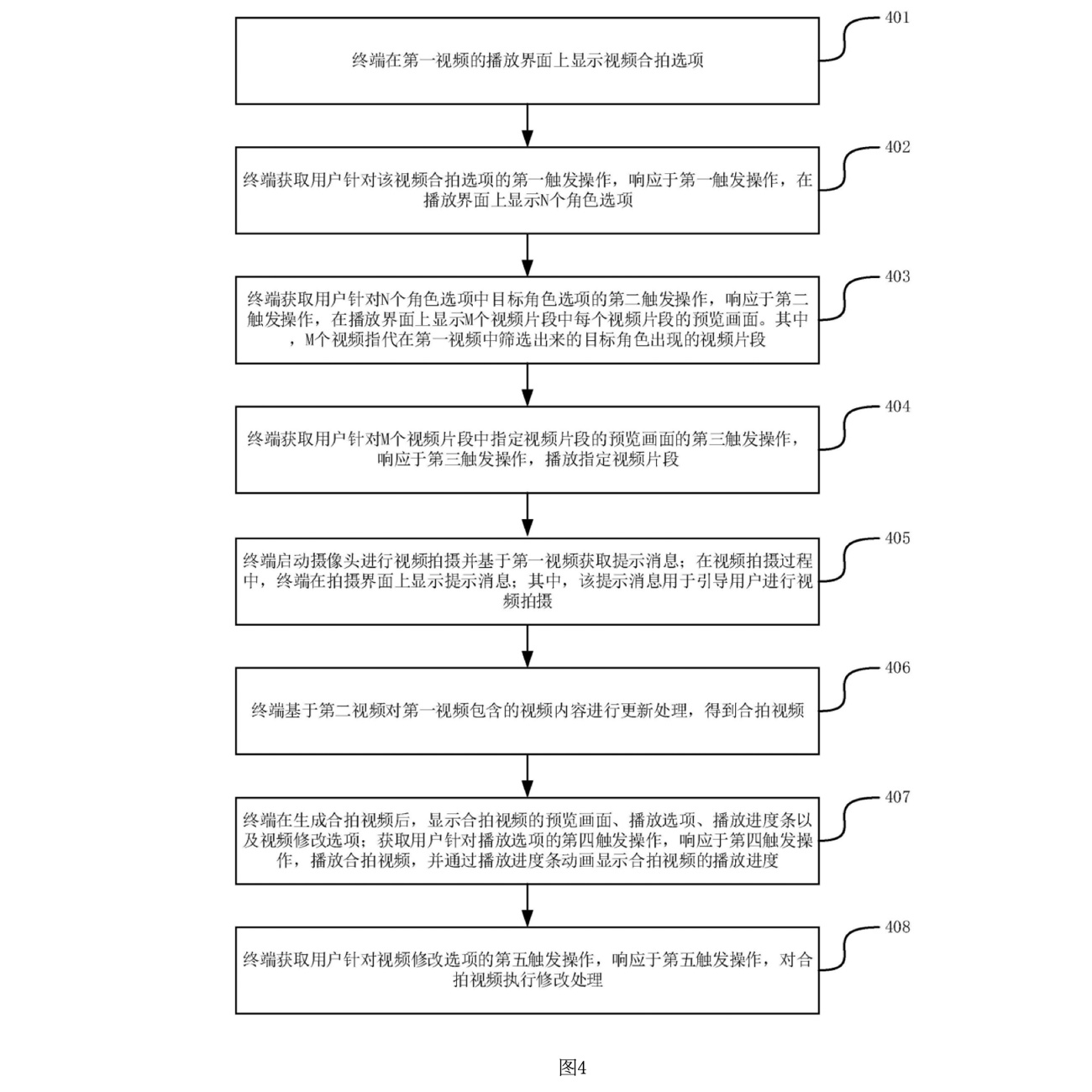
図4は、複数のキャラクターオプションが含まれる動画生成方法のフローチャートを示しています。ここでは、ユーザーが既存の動画に含まれる複数のキャラクターから選択し、特定のキャラクターを基にした動画撮影を行うプロセスが示されています。
1. ステップ401:
動画合拍オプションの表示: このステップでは、ユーザーが動画を再生している際に、再生インターフェース上に動画合拍オプションが表示されます。このステップは、図3に対応しており、ユーザーが既存の動画に対して自分の動画を追加するための初期インタラクションを提供します。
2. ステップ402:
第一トリガ操作の取得とキャラクターオプションの表示: ユーザーが動画合拍オプションをクリックすると、端末は第一トリガ操作を取得し、N個のキャラクターオプションを再生インターフェースに表示します。Nは2以上の正の整数であり、ユーザーはこれらのオプションから任意のキャラクターを選択できます。これにより、ユーザーは自分が参加したいキャラクターを選択し、そのキャラクターに関連するシーンを再現することができます。
3. ステップ403:
第二トリガ操作とM動画クリップのプレビュー表示: ユーザーがキャラクターオプションの中から特定のキャラクターを選択すると(第二トリガ操作)、端末はそのキャラクターに関連するM個の動画クリップのプレビューを再生インターフェースに表示します。Mは1以上の正の整数であり、これによりユーザーは選択したキャラクターの特定のシーンやクリップを視覚的に確認できます。
4. ステップ404:
第三トリガ操作と指定クリップの再生: ユーザーがプレビューされたクリップのいずれかを選択(第三トリガ操作)すると、その特定の動画クリップが再生されます。このステップでは、ユーザーがどのクリップを再現するかを決定し、そのクリップに基づいた動画撮影が行われます。
図4のフローチャートは、ユーザーが複数のキャラクターやシーンから選択し、特定のキャラクターに基づいた動画撮影を進めるプロセスを詳細に示しています。これにより、ユーザーは自分の好みに合わせて動画をカスタマイズし、既存の動画と自然に融合させることが可能になります。
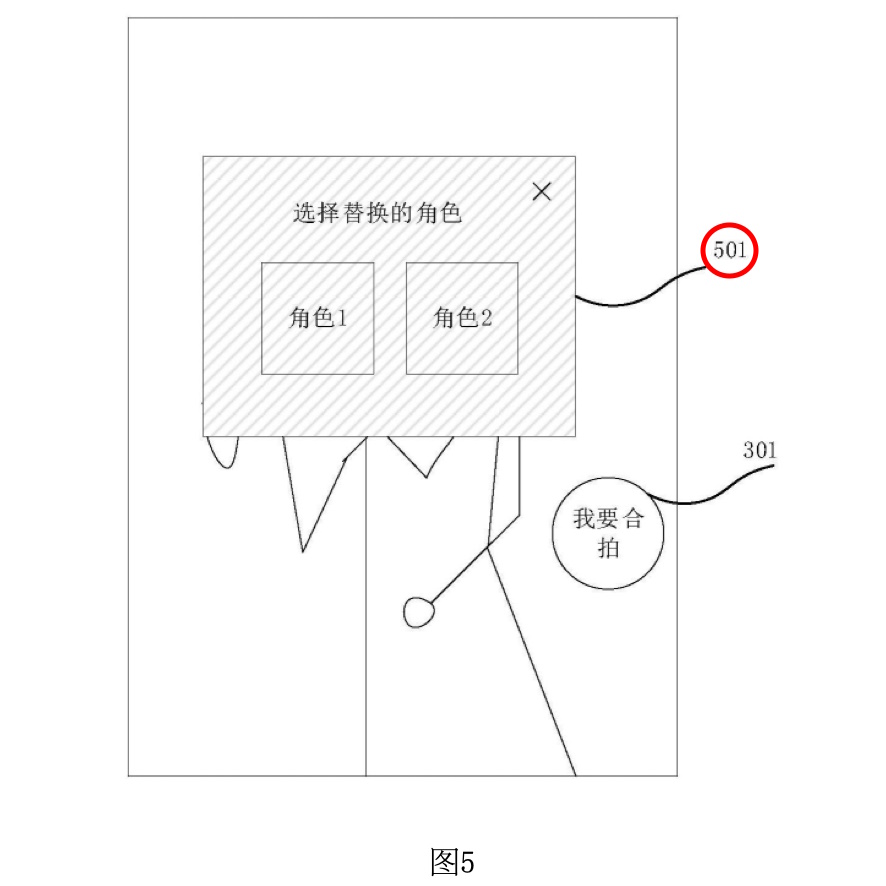
図5は、ユーザーが「合拍」オプションを選択した後に表示されるキャラクターオプションを示しています。この図では、既存の動画に含まれるキャラクター(角色)がユーザーに提示され、どのキャラクターに基づいて自分の動画を撮影するかを選択できるインターフェースが示されています。
キャラクターオプション501: 図5では、「キャラクター1」と「キャラクター2」の2つのオプションが再生インターフェースに表示されています。これらのキャラクターは、既存の動画に登場するキャラクターであり、ユーザーがこの中から1つを選択して、そのキャラクターとして動画に参加することができます。例えば、キャラクター1を選択すると、そのキャラクターの役割をユーザーが再現する形で撮影が進行します。
キャラクターオプションの選択: ユーザーがキャラクターオプションのいずれかをクリックすると、選択したキャラクターに関連するシーンやクリップが次のステップで表示されます。キャラクターオプションには、各キャラクターの画像やアイコンが表示されることが一般的で、ユーザーは視覚的にどのキャラクターを選択するかを判断できます。
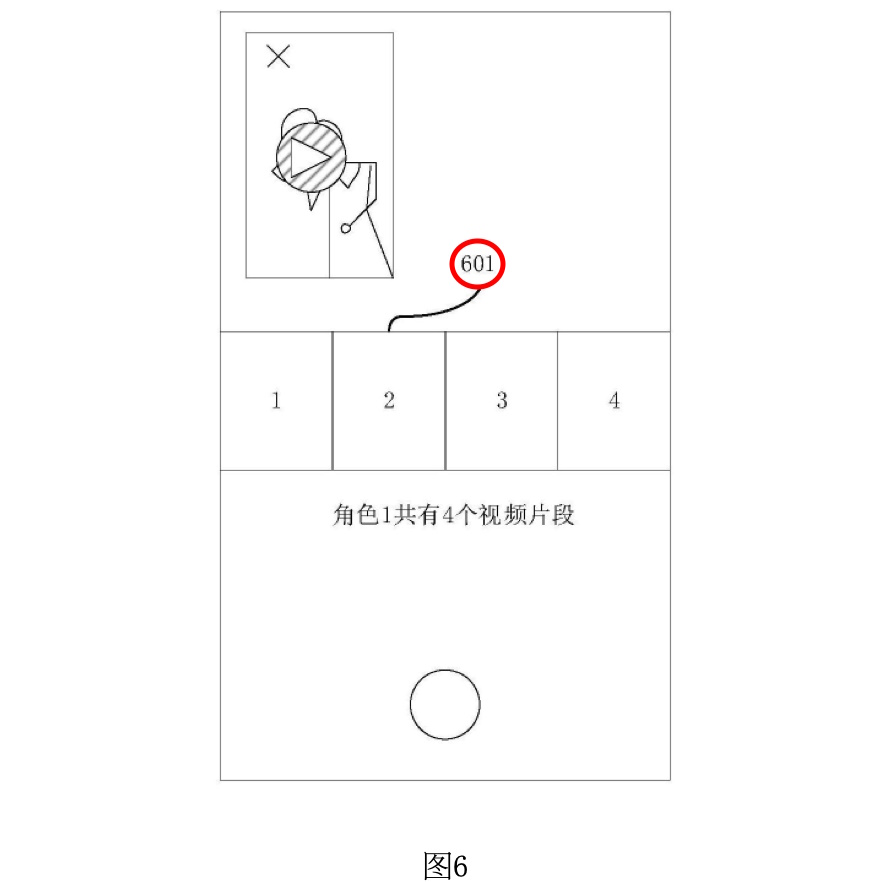
図6は、ユーザーがキャラクターオプションを選択した後に表示される、関連する動画クリップのプレビューを示しています。この図では、選択されたキャラクターに関連する複数の動画クリップが再生インターフェースに表示されます。
プレビュー画面601: 図6では、キャラクター1に関連する4つの動画クリップがプレビュー形式で表示されています。各プレビュー画面は、タイル形式やリスト形式で並べられており、ユーザーがどのクリップを再現したいかを視覚的に選択できるようになっています。各クリップのプレビューは、クリップの最初のフレームやキーとなるフレーム、またはランダムに選ばれたフレームが表示されており、ユーザーが簡単に内容を把握できるようになっています。
クリップの選択: ユーザーはプレビュー画面をクリックすることで、特定のクリップを選択し、そのクリップに基づいて自分の撮影を進めることができます。この選択プロセスは、ユーザーが自分の好みに合わせて撮影内容をカスタマイズできるようにするために重要です。
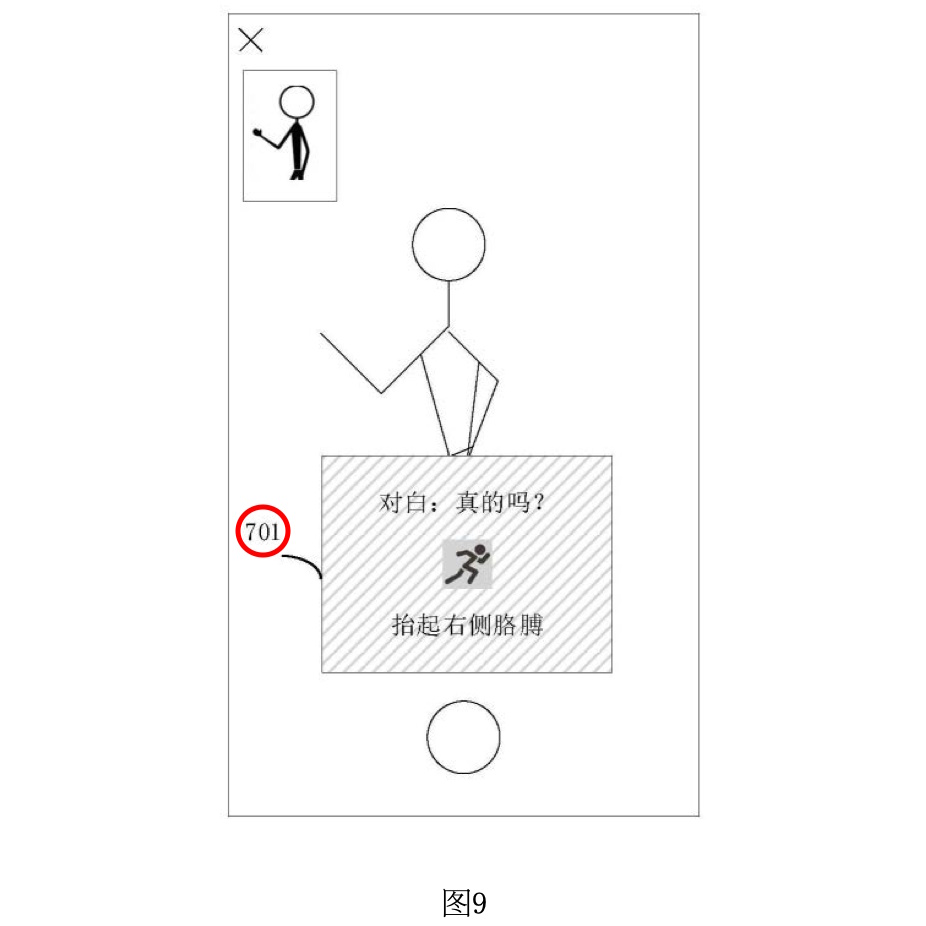
図9は、ユーザーが動画撮影を行う際に、肢体動作に関するガイドメッセージが表示される例を示しています。この図では、撮影中にユーザーが特定の肢体動作を行う必要がある場合の指示が表示されています。
ガイドメッセージ701: 図9では、ユーザーが「右腕を上げる」という動作を行う必要があることを示す指示が表示されています。これは、動画の内容を解析した結果、特定のシーンでキャラクターが右腕を上げる動作をしているため、それに合わせてユーザーも同じ動作を行う必要がある場合に提供される指示です。ガイドメッセージは、小さな人のアイコン(「動いている小さな人」)とテキスト(「右腕を上げる」)で構成されており、視覚的かつ直感的に指示が伝えられます。
台詞の表示: また、この場面では、ユーザーが同時に読み上げる必要がある台詞も表示されています。図9では、「本当にやるのか?」という台詞が表示されており、ユーザーが動作とともに台詞を正確に再現できるようにガイドされています。
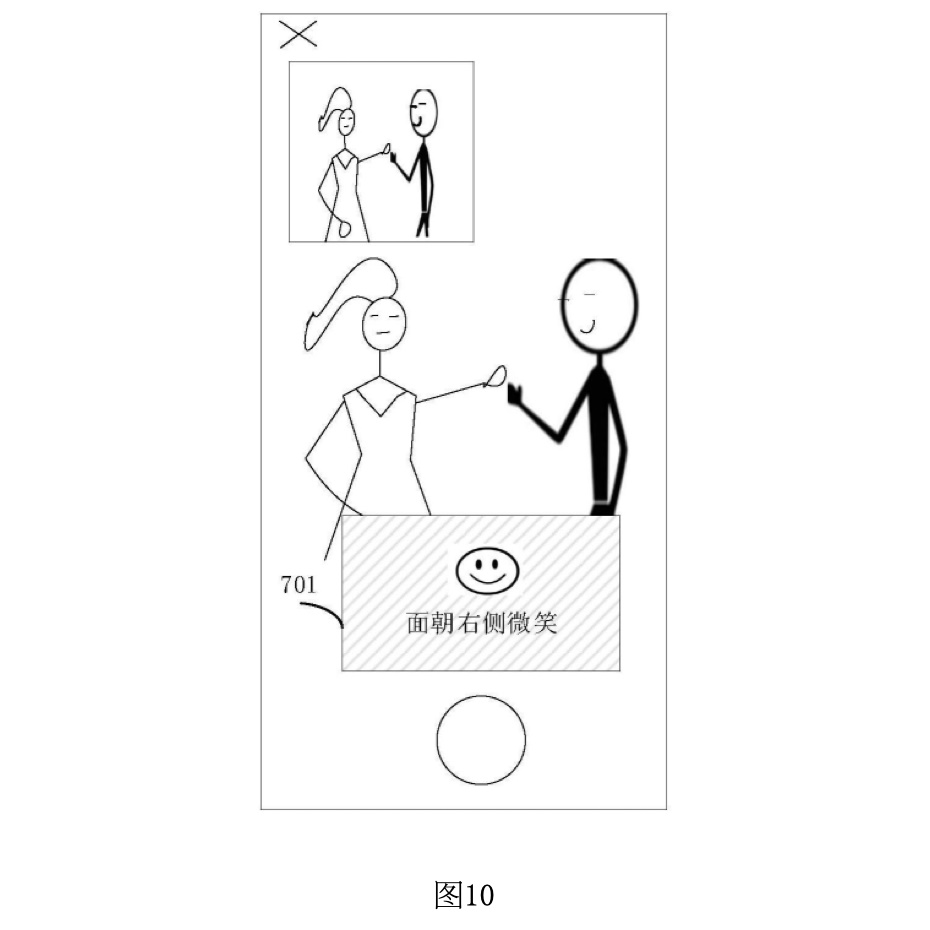
図10は、ユーザーが動画撮影を行う際に、表情に関するガイドメッセージが表示される例を示しています。この図では、特定の表情を再現する必要がある場合の指示が提供されます。
ガイドメッセージ701: 図10では、ユーザーが「右側に笑顔を向ける」という表情をする必要があることを示す指示が表示されています。これは、動画内のキャラクターが右側に笑顔を向けているため、ユーザーも同様の表情を再現する必要がある場合に提供される指示です。このガイドメッセージは、笑顔のアイコン(「笑顔」)とテキスト(「右側に笑顔を向ける」)で構成されており、ユーザーがどのような表情をすべきかを明確に伝えています。
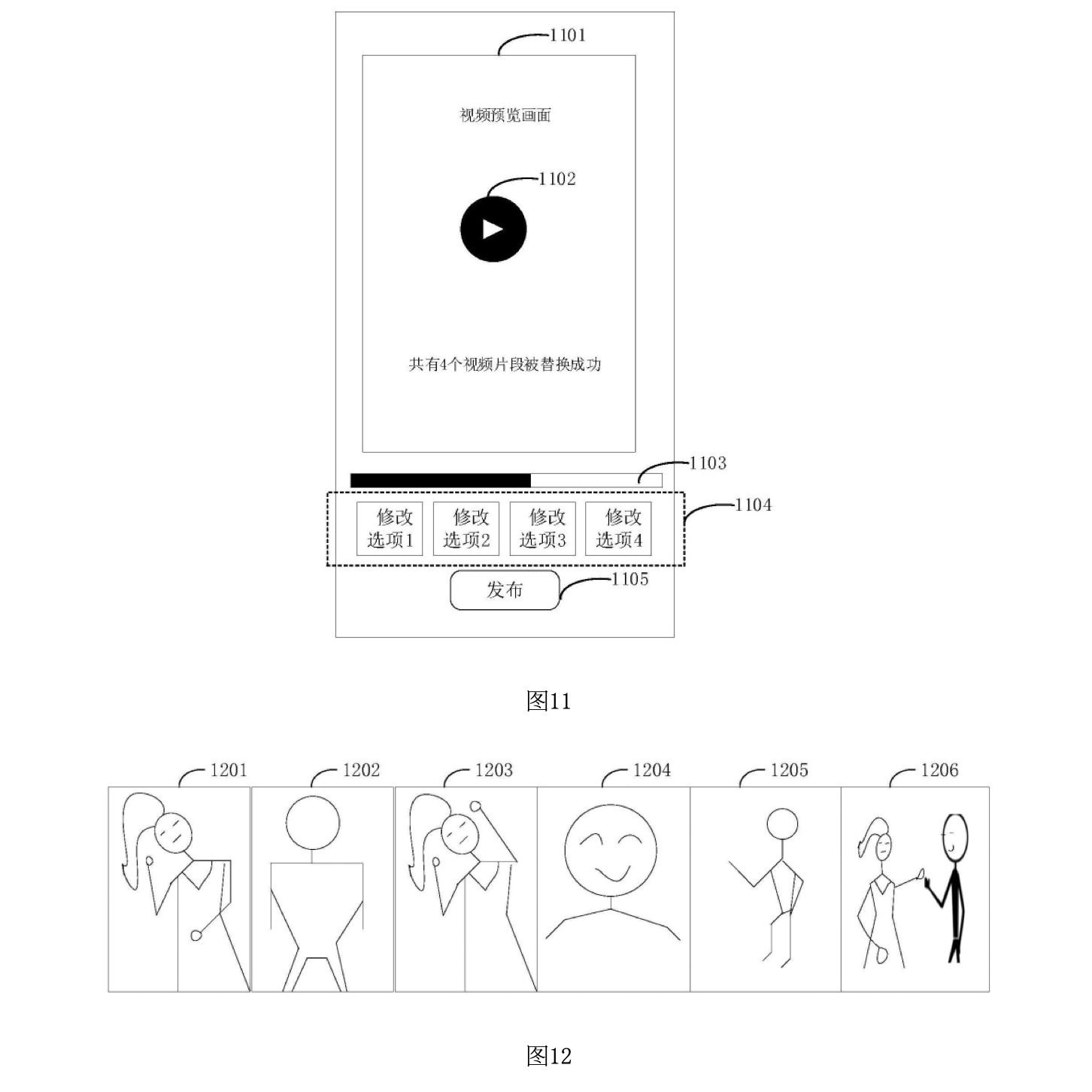
図11は、ユーザーが合拍動画を生成した後に表示されるプレビュー画面と、再生や編集などの操作オプションを示しています。この図では、生成された動画を確認し、必要に応じて編集や再生を行うためのインターフェースが提供されます。
プレビュー画面1101: 図11では、生成された合拍動画のプレビュー画面が表示されています。この画面は、合拍動画の最初のフレーム、キーとなるフレーム、またはランダムに選ばれたフレームが表示され、ユーザーが生成された動画を視覚的に確認できるようになっています。
再生オプション1102: プレビュー画面の下には、再生オプションが表示されています。ユーザーは、このオプションをクリックして、合拍動画を再生し、内容を確認することができます。
再生進捗バー1103: 再生オプションの横には、再生進捗バーが表示されています。再生中、進捗バーのアニメーションが表示され、ユーザーは再生の進行状況を視覚的に確認できます。これにより、動画のどの部分が再生されているかを把握しやすくなります。
動画編集オプション1104: 図11には、複数の編集オプションも表示されています。例として、4つの編集オプションが表示されており、ユーザーは合拍動画に対して素材の調整、テキストの追加、ステッカーの追加、フィルターの適用、顔の美化などを行うことができます。このように、ユーザーは生成された動画をさらにカスタマイズして、自分の好みに合わせた仕上がりに調整できます。
公開オプション1105: また、プレビュー画面の下部には、公開オプションが表示されています。このオプションを選択することで、ユーザーは生成された合拍動画をビデオ共有プラットフォームや自分の個人ページに公開することができます。公開する前に最終確認を行うために便利な機能です。
図12は、生成された合拍動画が時間順にどのように構成されるかを示す例です。この図では、元の動画とユーザーが撮影した動画がどのように交互に表示されるかを視覚的に表現しています。
ビデオフレーム1201, 1203, 1205: 図12では、時間の経過に沿って並べられたビデオフレームが表示されており、1201、1203、1205が元の動画からのフレームを表しています。これらのフレームは、元の映像の特定のシーンを表しており、合拍動画の中で交互に再生される部分です。
ビデオフレーム1202, 1204, 1206: 対して、1202、1204、1206はユーザーが撮影した動画からのフレームを示しています。これらのフレームは、元の動画に対してユーザーが追加した部分を表しており、元の映像と組み合わされて合拍動画として再生されます。
フェイススワップフレーム1206: 特に1206のフレームは、元の映像に含まれているキャラクターの顔を、ユーザーの顔に置き換えたフェイススワップの例を示しています。元の映像とユーザーの映像がシームレスに統合されるため、合拍動画は自然で一貫性のあるものになります。
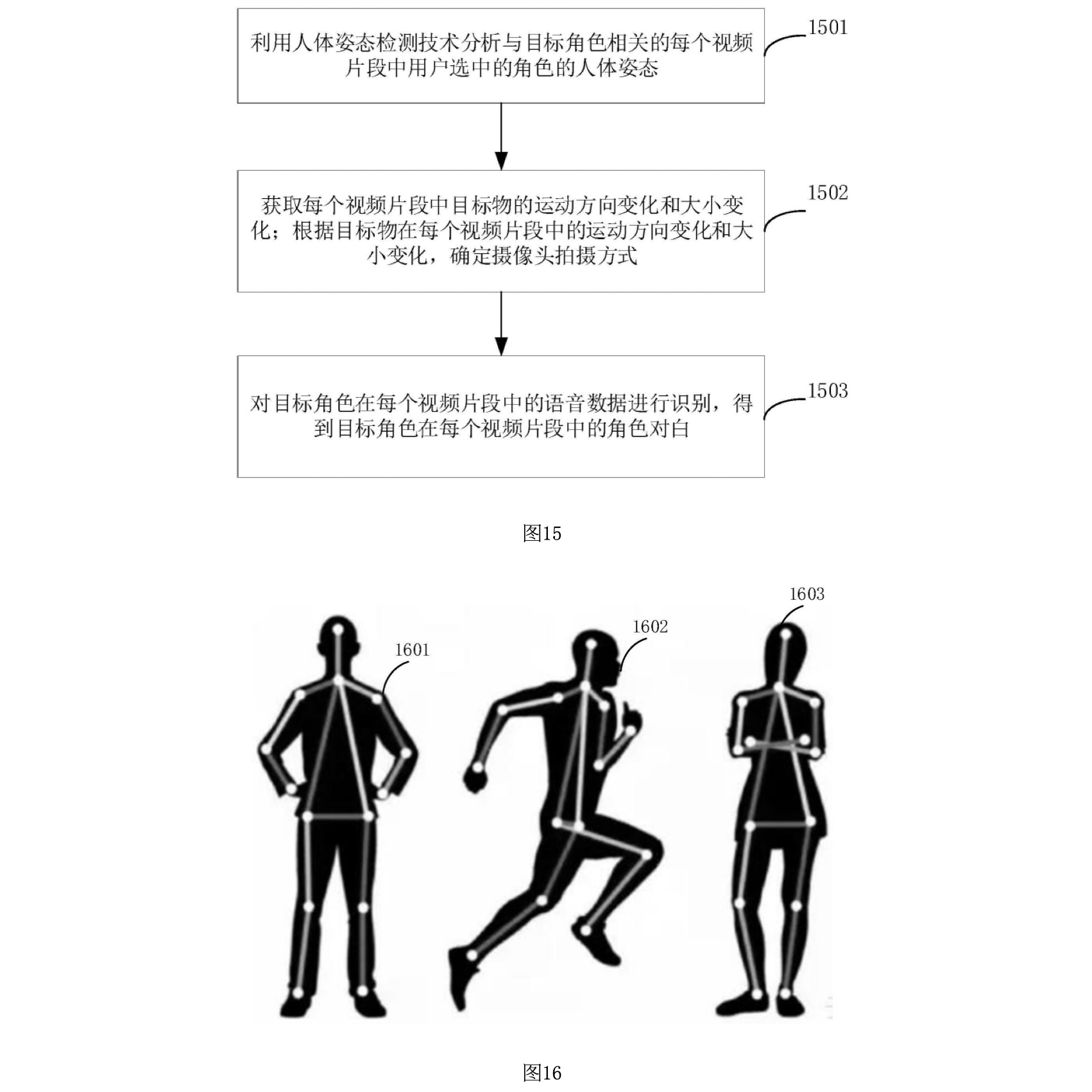
図15は、ターゲットキャラクターに関連する動画クリップの画面内容を解析するフローを示しています。このフローでは、各動画クリップの内容がどのように解析され、ユーザーにガイドメッセージとして表示されるかが説明されています。
1501: キャラクターの身体姿勢解析
動画クリップに含まれるターゲットキャラクターの身体姿勢が解析されます。この解析には、人体のキーポイント検出ネットワークを使用し、キャラクターの表情や姿勢、肢体の動作などを特定します。解析された結果は、ユーザーが撮影時に参照するガイドメッセージとして使用されます。
1502: オブジェクトの動き方向とサイズ変化の解析
動画クリップ内のオブジェクト(人物など)の動きの方向やサイズの変化が解析されます。この解析結果を基に、カメラの撮影モード(例えば、パンやズームなど)が特定され、ユーザーが撮影する際のガイドメッセージとして表示されます。
1503: キャラクターの声データの識別
動画クリップ内のターゲットキャラクターの声データが識別され、キャラクターの台詞が特定されます。この台詞は、ユーザーが撮影時に再現するために、ガイドメッセージとしてユーザーに提供されます。
図16は、人体キーポイントを接続することで生成される姿勢モデルを示しています。この図では、キャラクターの身体姿勢を解析するために使用されるフレームワークを説明しています。
姿勢モデル1601, 1602, 1603
図16には、異なる3つの姿勢モデルが示されています。これらはそれぞれ、「両手を腰に置いた立ち姿勢1601」、「走っている姿勢1602」、「両手を胸の前で組んだ立ち姿勢1603」を表しています。これらの姿勢モデルは、動画内のキャラクターの姿勢を分析し、ユーザーが同じ姿勢を再現できるようにするために使用されます。
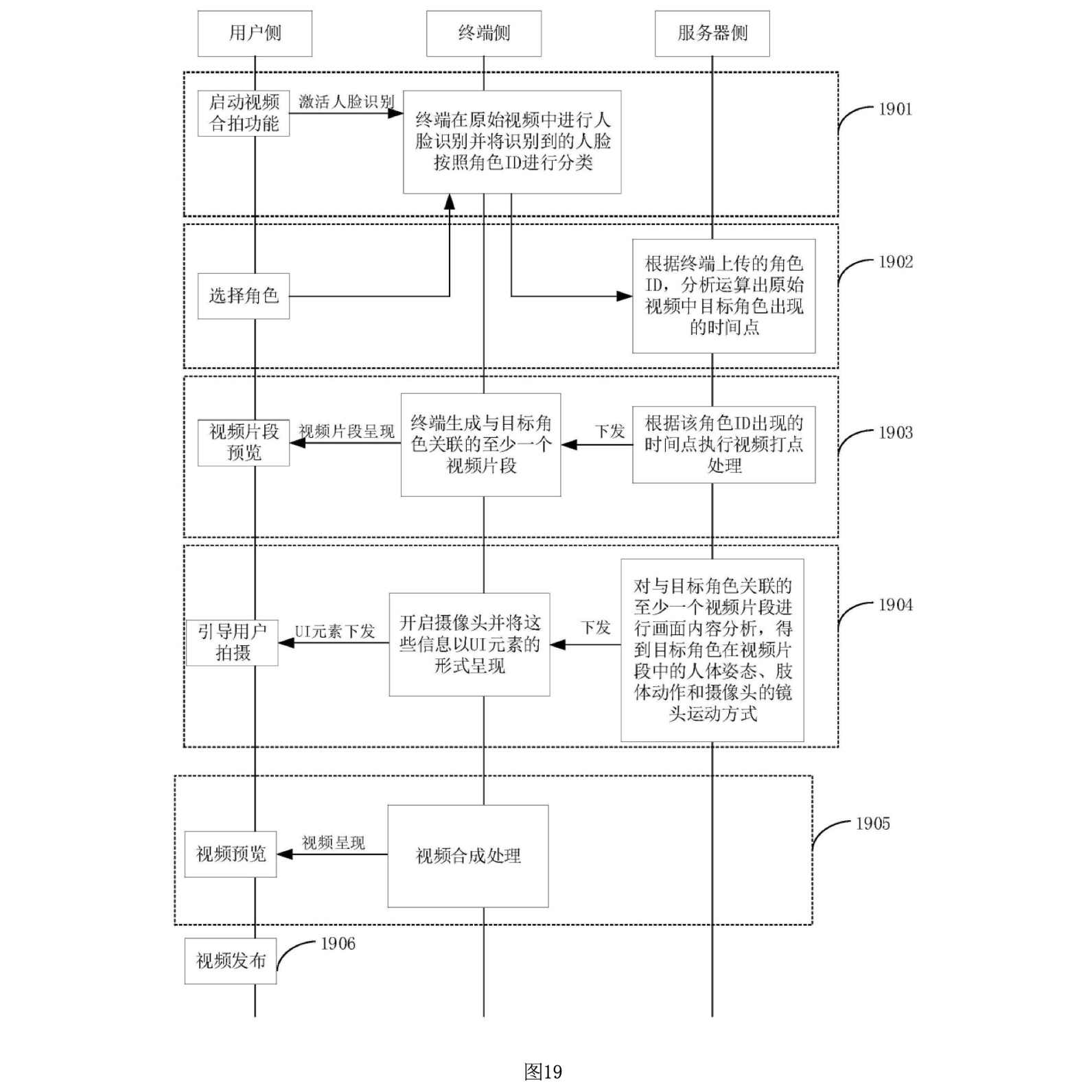
図19は、動画生成方法における全体の実行フローを示しています。このフローは、ユーザーが動画生成プロセスにどのように関与し、端末とサーバがどのように連携して処理を進めるかを説明しています。以下に、各ステップについて詳細に説明します。
1901: ユーザーによる動画撮影機能の開始と顔認識の実行
ユーザーが端末でトリガー操作を行うことで、動画撮影機能が開始されます。この操作により、端末は元の動画に対して顔認識を実行します。この顔認識プロセスにより、動画内のキャラクターの顔が特定され、これに基づいてキャラクターIDが生成されます。端末はこれらのキャラクターIDをユーザーに提示し、ユーザーが撮影に使用するキャラクターを選択できるようにします。
1902: ユーザーによるキャラクターの選択とサーバへの役割IDのアップロード
ユーザーが提示されたキャラクターIDの中からターゲットキャラクターを選択すると、そのキャラクターに対応する役割IDがサーバに送信されます。サーバは、この役割IDを基に、元の動画内でそのキャラクターが登場するシーンを解析します。
1903: サーバによるキャラクターの登場時間点の解析と動画クリップの生成
サーバは、受信した役割IDを基に、元の動画内でターゲットキャラクターが登場する時間点を解析します。その後、これらの時間点に基づいて動画クリップが生成されます。この動画クリップは、ターゲットキャラクターに関連するシーンを含んでおり、ユーザーがプレビューや再撮影に使用するためのものです。
1904: サーバによる動画クリップの内容解析と撮影ガイドの提供
サーバは、生成された動画クリップの内容を解析し、ターゲットキャラクターの身体姿勢、肢体の動作、カメラの撮影モードなどの情報を抽出します。この情報は、ユーザーが撮影を行う際のガイドメッセージとして、端末のインターフェース上に表示されます。これにより、ユーザーは元の動画と一致するような映像を撮影することができます。
1905: 元の動画とユーザーが撮影した動画の内容更新処理
ユーザーが撮影を完了すると、端末は元の動画と新しく撮影された動画を組み合わせて、1つの合成動画(合拍動画)を生成します。この動画は、元の動画とユーザーが撮影した動画の内容を融合させたものであり、ユーザーが深く関与した個別化された映像となります。端末は、この合成動画のプレビュー画面を生成し、ユーザーが結果を確認できるようにします。
1906: 動画のプレビューと公開
ユーザーは、生成された合成動画をプレビューし、必要に応じて動画の編集や修正を行うことができます。プレビューが完了した後、ユーザーは動画を公開するかどうかを選択できます。公開された動画は、動画共有プラットフォームや個人のホームページで他のユーザーが視聴できるようになります。
図20から図28は、動画生成方法の実際のユーザーインターフェース(UI)とその操作手順を詳細に示しています。これらの図は、ユーザーが動画撮影を行い、生成された動画をプレビューし、編集するまでの一連のプロセスを視覚的に表現しています。
図20: 元の動画の再生インターフェース
図20では、元の動画が再生されているインターフェースが示されています。この再生インターフェース上には、「私も撮る」などの動画撮影オプションが表示されています。ユーザーがこの撮影オプションを選択すると、動画撮影機能が起動され、キャラクターの選択画面に移行します。
図21: キャラクター選択インターフェース
図21では、ユーザーが選択できる2つのキャラクター(キャラクターAとキャラクターB)が表示されています。ユーザーはこれらのキャラクターの中から1つを選択し、そのキャラクターに対して撮影を行います。このインターフェースは、ユーザーがどのキャラクターをターゲットにするかを決定するための画面です。
図22: キャラクターの選択後のインターフェース
図22では、ユーザーがキャラクターを選択した後のインターフェースが示されています。この画面では、選択されたキャラクターに関連する動画クリップが一覧表示され、ユーザーはこれらのクリップを確認したり、選択したりすることができます。
図23: 動画クリップのプレビューインターフェース
図23では、選択されたキャラクターに関連する動画クリップのプレビュー画面が示されています。これらのクリップは、元の動画から選別されたもので、ユーザーが模倣するためのターゲットシーンとなります。プレビュー画面はタイル状またはリスト状に表示され、ユーザーは任意のクリップを選択して再生できます。
図24: 撮影時のガイドメッセージ(カメラモード)
図24では、撮影時にユーザーに提示されるガイドメッセージが表示されています。ここでは、カメラの撮影モードに関するガイドが表示され、ユーザーがどのようにカメラを操作すべきかが指示されています。たとえば、画面プッシュ(ズームイン)の操作が示されています。
図25: 撮影時のガイドメッセージ(肢体動作)
図25では、ユーザーに提示される肢体動作に関するガイドメッセージが示されています。元の動画内でキャラクターが行っている動作を模倣するよう、ユーザーに指示が出されます。たとえば、左腕を上げる動作が示されています。
図26: 撮影時のガイドメッセージ(表情)
図26では、表情に関するガイドメッセージが表示されています。ユーザーがキャラクターの表情を再現するために、笑顔や顔の向きに関する指示が出されています。これにより、ユーザーが元の動画に忠実な演技を行うことができます。
図27: 合成動画のプレビューと編集オプション
図27では、生成された合成動画のプレビュー画面と編集オプションが表示されています。ここでは、プレビュー画面、再生オプション、再生進行バー、そして編集オプションが示されています。ユーザーは、素材の調整やテキストの追加、ステッカーの貼り付け、フィルターの適用などを行うことができます。
図28: 合成動画の時間順再生
図28では、元の動画とユーザーが撮影した動画が時間順に交互に再生される様子が示されています。この図では、動画フレームが時間の経過に沿って順番に表示され、元の動画と撮影された動画が交互に再生されることで、シームレスな合成が実現されています。








図20から図28にわたる一連の図は、ユーザーが元の動画に対してどのように合成動画を作成し、それを編集・公開するまでの詳細なプロセスを視覚的に示しています。これにより、ユーザーがガイドに従って動画を撮影し、編集し、最終的な動画をプレビューして公開するまでの一連の操作が、直感的に理解できるようになっています。このフローは、ユーザーが簡単に高品質な合成動画を作成できるように設計されています。
ここがポイント!
この特許発明のポイントは広範にわたりますが、まとめると以下のとおりです。
1. 動画生成方法と装置の概要
本発明は、AI技術とクラウド技術を利用した動画生成方法、装置、記憶媒体、およびコンピュータ装置に関するものです。
特に、ユーザーが既存の動画に対して追加で動画を撮影し、その撮影動画を元の動画と合成するプロセスを簡素化し、より高品質な合成動画を生成できるように設計されています。
この方法と装置は、短期間で効率的に動画撮影と合成が可能なため、撮影コストの削減と高品質な動画生成を実現します。
2. 動画撮影のガイド機能
システムは、元の動画(第一動画)を解析し、その内容に基づいてユーザーに対する撮影ガイドメッセージを提供します。これにより、ユーザーが撮影中にどのようなアクションを取るべきか(例:顔の向き、表情、肢体動作、カメラの動作方法など)が明確に提示されます。
撮影ガイドには、アイコンやテキストの形式で指示が表示され、ユーザーはそれに従って動画を撮影します。例えば、カメラの撮影モード、キャラクターの動作、表情などの提示が含まれます。
3. 動画の合成プロセス
システムは、ユーザーが撮影した動画(第二動画)を取得し、それを元の動画と合成します。この合成プロセスは、ユーザーが撮影した動画を、元の動画の一部としてシームレスに融合させることを目的としています。
合成プロセスでは、元の動画の内容とユーザーの動画の内容を比較し、一致する部分や置換が必要な部分を自動的に処理します。たとえば、元の動画内で特定のキャラクターが登場するシーンをユーザーが再現した場合、システムはそのキャラクターの顔をユーザーの顔と置き換える処理を行います。
4. カメラ操作とシーンの融合
システムは、元の動画におけるカメラの動きやシーンの変化を解析し、ユーザーが撮影時に同じようなカメラ操作を行えるようにガイドします。これにより、元の動画とユーザーの動画が統合された際に、自然な流れで映像が進行するようになります。
カメラの動きとしては、ズームイン、パン、ティルト、フォローショットなどが含まれ、それらの操作がユーザーに対して提示されます。
5. ディープフェイク技術の応用
合成プロセスの一部として、ディープフェイク技術が用いられています。この技術により、元の動画のキャラクターの顔をユーザーの顔に置き換えることが可能となり、シーンの一体感を高めます。
ディープフェイク技術は、エンコーダーとデコーダーのアーキテクチャに基づいており、元の顔の特徴を保持しつつ、ユーザーの顔と自然に融合させることができます。
6. ユーザーインターフェースの設計
ユーザーインターフェース(UI)は、直感的でわかりやすいデザインが施されており、ユーザーが操作しやすいように工夫されています。撮影時のガイドメッセージや、編集オプション、プレビュー機能などが、明確に表示されます。
撮影後の編集では、素材の調整、テキストやステッカーの追加、フィルターの適用など、多様な編集機能が提供されており、ユーザーが自分好みにカスタマイズできます。
7. クラウド技術との連携
クラウド技術が本発明の重要な要素として組み込まれています。動画の処理や保存、さらにはAIによる解析機能がクラウド上で実行されることで、端末の性能に依存せずに高い処理能力を発揮します。
ユーザーが撮影した動画はクラウドにアップロードされ、サーバー側での解析と処理が行われた後、結果がユーザーに提供されます。
8. 応用範囲と利便性
この技術は、短い動画だけでなく、映画やテレビエピソードのシーンに対する動画撮影にも適用可能です。多様なシーンにおいて、ユーザーは元の動画と自分の動画を融合させることができます。
簡便な操作で高度な動画編集が可能であり、一般ユーザーからプロフェッショナルまで幅広い層に利用が期待されます。
未来予想
今回紹介したテンセントの特許技術は、特にユーザーが動画を生成・編集するためのプラットフォームやアプリケーションで広く利用されていく可能性があります。具体的には、以下のようなサービスでの応用が予想できるでしょう。
1. TikTokやInstagram Reelsなどの短編動画プラットフォーム
これらのプラットフォームでは、ユーザーが既存の動画に合わせて自身の動画を撮影し、合成する機能が提供されています。この特許技術は、動画合成を効率的に行うためのガイド機能やディープフェイク技術を活用し、ユーザーが簡単に高品質な合成動画を作成できるようにします。
2. Snapchatのレンズ機能
Snapchatのレンズ機能では、ユーザーの顔を他のキャラクターやシーンに組み込むことができます。この特許技術のディープフェイク技術や、カメラ操作ガイドがSnapchatのようなサービスで活用されていると考えられます。
3. YouTubeのショート動画やライブ配信サービス
YouTubeのショート動画機能やライブ配信中に、視聴者とのリアルタイムなインタラクションを行いながら、動画合成を可能にする技術が導入されている場合、この特許技術の要素が活用されている可能性があります。
4. 映画やドラマのプロモーションアプリ
映画やドラマのプロモーション用に、ファンが自分自身を登場人物として動画に組み込むことができるアプリがあります。このようなアプリでも、特許技術が活用され、ユーザーが簡単に合成動画を作成できるようになっています。
この特許技術がさらに広く応用されることにより、次のような社会変革をもたらすことも考えられます。
1. コンテンツ生成の民主化
この技術は、動画編集のハードルを大幅に下げ、誰でも簡単に高品質なコンテンツを作成できる時代を到来させます。これにより、プロフェッショナルだけでなく、一般のユーザーもクリエイティブな活動を手軽に楽しめるようになります。コンテンツの生成と共有がますます活発になり、個々人が発信するメディアがより多様化するでしょう。
2. 没入型エンターテインメントの拡大
この技術を活用した没入型エンターテインメントが普及することで、ユーザーは単なる視聴者から「体験者」へと変わっていきます。例えば、VRやAR技術と組み合わせて、ユーザー自身が映画やゲームの中に登場するような体験が一般化し、エンターテインメント業界に新たなビジネスチャンスが生まれる可能性があります。
3. バーチャルインフルエンサーの登場と進化
ディープフェイク技術と高度な合成技術により、バーチャルインフルエンサーの活動がさらに活発化するでしょう。現実の人物とほとんど見分けがつかないバーチャルキャラクターが、SNSや広告業界で活躍し、企業はこれらのキャラクターを使ったマーケティング戦略を採用することが増えると予想されます。
4. 教育やトレーニング分野での応用
この技術は、教育やトレーニングの分野でも大きな変革をもたらします。例えば、リモート教育において、教師やトレーナーが遠隔地にいる学生や受講者に対して、リアルタイムで合成されたシミュレーション動画を使って授業を行うことが可能になります。これにより、教育の質が向上し、学習者の理解度も向上するでしょう。
5. ソーシャルインタラクションの変革
SNSやメッセージングアプリで、ユーザー同士が合成動画を介してコミュニケーションを取ることが一般的になると考えられます。例えば、友人と一緒に映画の一部を再現したり、仮想のキャラクターとしてチャットしたりすることが、日常的なコミュニケーション手段として定着する可能性があります。
6. プライバシーとセキュリティの課題
ディープフェイク技術の普及に伴い、プライバシーやセキュリティに関する課題も深刻化する可能性があります。偽造動画や詐欺的なコンテンツが増えるリスクがあるため、法的規制や技術的対策が求められるでしょう。このような課題に対応するため、ディープフェイク検出技術や、プライバシー保護のための新たな標準が導入されると予想されます。
このように、特許技術は幅広い分野で応用が期待され、コンテンツ生成やエンターテインメント、教育、そしてソーシャルインタラクションに革命をもたらす可能性を秘めています。しかし、その一方で、技術の進展に伴う倫理的・法的課題にも対応していく必要があります。
特許の概要
|
発明の名称 |
视频生成方法、装置、存储介质及计算机设备 |
|
出願番号 |
CN202010636852 |
|
公開番号 |
CN111726536A |
|
特許番号 |
CN111726536B |
|
優先日 |
2020年7月3日 |
|
公開日 |
2020年9月29日 |
|
登録日 |
2024年1月5日 |
|
出願人 |
Tencent Technology Shenzhen Co Ltd |
|
発明者 |
张新磊 |
| 国際特許分類 |
H04N23/632 Graphical user interfaces [GUI] specially adapted for controlling image capture or setting capture parameters for displaying or modifying preview images prior to image capturing, e.g. variety of image resolutions or capturing parameters |
| 経過情報 |
米国での出願公開公報:US2023/0066716A1 |