INTRODUCTION
さてさてやって参りました「編集局が選ぶ!ベストパテント大賞2023」!
今年も昨年に続きて、2023年最後を締めくくりとして、+VISION編集部が厳選した、2023年度ベストパテント大賞を発表します!
ちなみに、昨年の第1位は、avatarin株式会社の遠隔操作ロボットの操作性向上、第2位がアップル社のCGリアリティ環境に出入りする際のエフェクトの指定、第3位がディズニー社の仮想世界シミュレーターに搭載予定の驚くべき新技術でした。今年の第1位はどのような特許でしょうか!?それでは、2023年ベストパテント大賞を御覧ください!
プレゼンテーションをAIが自動提供

会社勤務をしている方の中には、仕事中はずっとPCに向かって様々な資料を作り続けることを業務としている方も多いのではないでしょうか。基本的に資料作成はユーザーが文書の内容を手入力することが当然でしたが、今後はその常識が変わっていくかもしれません。
今回紹介する特許は、ユーザが手動でコンテンツを作成する労力を軽減させるものです。ユーザは短いテキスト入力をするだけで、質の高い資料を生成させることができます。また、ユーザは生成された資料を保持、編集、破棄することができるため、自分のニーズに合わせてカスタマイズすることが可能です。
この特許は、プレゼンテーションの作成や資料作成にかかる時間や労力を削減するのに役立ち、特に、短い納期や制作に追われている場合には大きな助けとなるでしょう。
発明の背景
従来、ユーザはプレゼンテーション作成アプリケーション、ワードプロセッシングアプリケーションなどのコンテンツ開発ツールを使用してコンテンツを作成していました。ここで用いられるコンテンツや素材のデザインは、ユーザ自身によって作成・用意されます。一部のツールではデザインやレイアウトのテンプレートなどの提案を提供しますが、テキストのコンテンツはユーザが作成し、提案はユーザのテキスト入力に依存しています。
どんな発明?
発明の目的
本発明は、応答コンテンツの一部を、コンテンツ生成アプリケーションと互換性のあるコンテンツドキュメントに更新することを目的としています。また、ユーザクエリに基づいてバイアスの可能性を検出し、ヒントを生成して表示すること、さらに、複数のユーザクエリやユーザの選好履歴などを考慮して、プロンプトやヒントを生成することも目的としています。
本発明により、ユーザのテキスト入力への依存を削減し、ユーザのわずかな入力に基づいて完全なテキストを生成する方法を提供します。開示されるシステムは、どのようなコンテンツ開発アプリケーションでも実装することができます。このソリューションは、完全な自然言語生成モデルを使用して、ユーザが少ないテキスト入力で反復的にコンテンツを生成することを可能にします。
ユーザは短い問題や質問を提供する機会を与えられることがあります。システムはユーザの入力を使用してプロンプトを生成し、自然言語生成モデルにプロンプトを提供し、自然言語生成モデルから出力を取得し、出力に基づいてユーザにコンテンツドキュメントで使用する完全なコンテンツを提案することができます。このプロセスは反復的に行われます。
ユーザは編集や追加コンテンツの要求、明確化、デザイン支援などを必要な回数だけ行い、最初に作成されたコンテンツがユーザの最小限の追加入力に基づいて更新・修正され、ユーザが提案された結果を選択して最終化するまでの間、修正を行うことができます。これにより、ユーザは完全で正確なコンテンツドキュメントを生成するためにかかる時間を大幅に短縮することができます。
発明の詳細
では、本発明の詳細を説明していきます。
本発明のシステムは、機械的構成として、ソフトウェア、ファームウェア、ハードウェア、またはそれらの組み合わせがシステムにインストールされていることにより、特定の操作やアクションを実行するように構成することができます。1つまたは複数のコンピュータプログラムは、データ処理装置によって実行されると、その処理によって装置がアクションを実行するようにする命令を含むことにより、特定の操作やアクションを実行するように構成することができます。1つの一般的な側面は、自動的にインテリジェントなコンテンツを生成するためのコンピュータ実装方法を含みます。この方法は、ユーザのクエリを受け取り、ユーザクエリの意図からアクションを決定することを含みます。この方法は、アクションに基づいてプロンプトを生成し、そのプロンプトを自然言語生成モデルに提供することを含みます。
プロンプトに対して、自然言語生成モデルからの出力を受け取ります。この方法は、出力に基づいて、コンテンツ生成アプリケーションと互換性のある形式で応答コンテンツを生成することを含みます。さらに、この方法は、少なくとも一部の応答コンテンツを表示することを含みます。この側面の他の実施例には、それぞれが前記方法のアクションを実行するように構成された対応するコンピュータシステム、装置、および1つ以上のコンピュータ記憶装置に記録されたコンピュータプログラムが含まれます。

上図は、自動インテリジェントコンテンツ生成のための例示的なシステム100を示したものです。システム100は、ユーザシステム105、アプリケーション/サービスコンポーネント110、プロンプト設計コンポーネント115、知識リポジトリ120、および自然言語生成モデリングコンポーネント125を含むものです。
ユーザーシステム105は、プロセッサによって実行される命令を格納するためのメモリを含みます。メモリには、コンテンツ生成アプリケーション130およびユーザーシステムの設計コンポーネント135が含まれます。コンテンツ生成アプリケーション130は、ワードプロセッシングアプリケーション(例:MICROSOFT WORD®)、プレゼンテーション作成アプリケーション(例:MICROSOFT POWERPOINT®)、またはその他のコンテンツ生成アプリケーション(例:MICROSOFT EXCEL®、MICROSOFT ONENOTE®、MICROSOFT OUTLOOK®、MICROSOFT PUBLISHER®、MICROSOFT PROJECT®など)である場合があります。ユーザーシステムの設計コンポーネント135は、図に示されるようにユーザーシステム105に含まれます。ユーザーシステムの設計コンポーネント135はクラウドベースでもよく、ユーザーシステム105上のユーザーインターフェースを介してアクセスされる場合があります。ユーザーシステムの設計コンポーネント135は、ローカルでの使用のためにユーザーシステム105上に複製されてもよく、クラウドコンポーネントによる使用のためにクラウド環境にも存在する場合もあります。
クエリ理解コンポーネント140は、ユーザのクエリを処理し、ユーザの要求について判断するために使用されます。クエリ理解コンポーネント140は、ユーザが入力したテキストクエリ(つまり、ユーザクエリ)を受け取り、ユーザの意図を理解しようとします。クエリ理解コンポーネント140は、ユーザの意図を2つのアクションタイプのいずれかに分類します。最初のタイプは、自然言語生成モデルを使用する自然言語アクションです。2番目のタイプは、デザインリクエストや変更などの自然言語以外のアクションであり、自然言語生成モデルは使用されません。
バイアス検出コンポーネント145は、ユーザクエリを評価し、クエリがバイアスのある、有害な、または関連性のないコンテンツを生成する可能性があるかどうかを判断するために呼び出されることがあります。バイアス検出コンポーネント145は、また、自然言語生成モデルからの出力を評価して、コンテンツがバイアスのある、有害な、または関連性のないものであるかどうかを判断するために使用されることがあります。バイアスのある、有害な、または関連性のない出力は、自然言語生成モデルのトレーニングによるものである場合があります。たとえば、システム100で使用される自然言語生成モデルとしては、Generative Pre-trained Transformer 3("GPT-3")が挙げられます。これは、ディープラーニングを利用する自己回帰言語モデルです。GPT-3は、人間らしいテキストを生成する強力な自然言語生成モデルです。
ただし、そのトレーニングは、フィルタリングされていない、クリーン化されていない、および潜在的にバイアスのあるコンテンツを使用して行われます。そのため、出力はバイアスのある、有害な、または関連性のないものである可能性があります。このような出力は、バイアス検出コンポーネント145を使用してフィルタリングすることがあります。さらに、特定の入力は、そのような望ましくない出力を生成する可能性が高いです。バイアス検出コンポーネント145は、そのような入力を望ましくない結果を生成する可能性があると識別し、結果を回避するために入力をフィルタリングすることがあります。例えば、入力テキストが「Donald Trumpに関するプレゼンテーション」という場合、この入力はバイアス検出コンポーネント145によってフラグ付けされないかもしれませんが、出力には「Donald Trumpは史上最悪の米国大統領である」というバイアスのある文言、「Donald Trumpは最高のテレビパーソナリティであり実業家である」というバイアスのある文言、「Donald Trumpは実業家であり第45代米国大統領である」という中立的/事実的な文言などが含まれる可能性があります。
さらに、結果には不適切な言語(有害なもの)や関連性のないコンテンツも含まれる場合があります。バイアス検出コンポーネント145は、そのような望ましくない結果をフィルタリングおよび/またはフラグ付けすることがあります。さらに、バイアス検出コンポーネント145は、時間の経過とともに学習する機械学習アルゴリズムなどの人工知能(AI)コンポーネントである場合があります。このため、入力はフラグ付けされるか、バイアスの可能性が割り当てられる場合があります。バイアス検出コンポーネント145が入力が望ましくない結果を提供する可能性があるか、出力が有害な、バイアスのある、または関連性のないものであるか(バイアスの可能性が存在するか、または閾値を超えるかどうか)を判断すると、ヒントコンポーネント150を使用してより関連性の高いまたは望ましい結果を得るためのヒントが提供されることがあります。バイアス検出コンポーネント145は、処理されない可能性のある有害なテキストを検出するブロックリストを含んでいる場合があります。そのような場合には、バイアス検出コンポーネント145は、閾値を超えるバイアスの可能性を割り当てることがあります。一部の実施例では、自然言語生成モデルからの結果が有害であるか、またはユーザからのフィードバックで結果が有害または悪いと報告された場合、バイアス検出コンポーネント145は学習し、ブロックリストに新しい用語を追加することがあります。一部の実施例では、これらの結果とフィードバックを使用して、ブロックリストを拡張することができます。
ヒントコンポーネント150は、望ましくない結果を回避するためのヒントを生成するAIコンポーネントです。たとえば、ヒントコンポーネント150は、「Donald Trumpに関するプレゼンテーション」というプロンプトを受け取り、より具体的な要求が望ましくない結果を生成する可能性が低いと判断する場合があります。例えば、ヒントコンポーネント150は、「Donald Trumpのビジネスに関するプレゼンテーション」、「Donald Trumpの大統領の業績に関するプレゼンテーション」などのヒントを生成することがあります。ヒントコンポーネント150は、これらの結果をユーザに表示するために出力します。
ユーザシステムデザインコンポーネント135がユーザのクエリを処理し、ユーザが要求しているアクションを判断した後、そのアクションまたはユーザクエリはクラウドベースのアプリケーション/サービスコンポーネント110に送信されます。アプリケーション/サービスコンポーネント110は、ユーザクエリまたはアクションをプロンプト設計コンポーネント115に送信することがあります。プロンプト設計コンポーネント115は、自然言語生成モデル125への入力に適したプロンプトを生成するために使用されます。プロンプト設計コンポーネント115は、機械学習アルゴリズムやニューラルネットワークを使用して、時間の経過とともにより良いプロンプトを開発するAIコンポーネントです。プロンプト設計コンポーネント115は、ユーザの好みデータ、プロンプトライブラリ、およびプロンプトの例などを含むナレッジリポジトリ120にアクセスして、プロンプトを生成し、それをアプリケーション/サービスコンポーネント110に返します。
アプリケーション/サービスコンポーネント110は、プロンプトを自然言語生成モデル125に提供し、応答コンテンツを取得します。応答コンテンツはユーザシステム105に送信され、提案生成コンポーネント155によって処理されます。提案生成コンポーネント155は、ユーザインターフェースやコンテンツ生成アプリケーション内でのコンテンツの表示のために1つ以上の提案を生成する場合があります。一部の実施例では、提案生成コンポーネント155はコンテンツ生成アプリケーション130の一部であり、応答コンテンツの表示のためにデザインの提案ツールを利用することがあります。提案の例は、図4〜9に示されるようなユーザインターフェースに提供されます。選択された提案は、コンテンツ文書に組み込まれ、コンテンツ生成アプリケーション130によって表示されます。
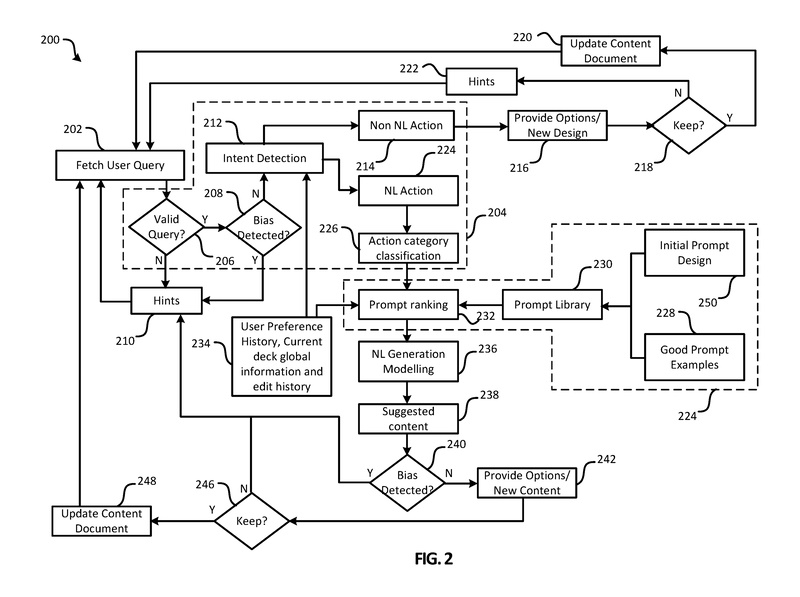
図2は、システム100によって実行されるアクションのフローチャート200を示しています。ステップには、ユーザシステムデザインコンポーネント135、コンテンツ生成アプリケーション130、アプリケーション/サービスコンポーネント110、プロンプト設計コンポーネント115、および自然言語モデリングコンポーネント125によって実行されるアクションが含まれています。フローチャート200でのアクションの実行には、ニューラルネットワーク、機械学習、AIモデリングなどの人工知能が使用される場合があります。
ステップ202では、ユーザクエリが取得されます。ユーザクエリは、ユーザシステムデザインコンポーネント135固有のユーザインターフェースを使用するか、コンテンツ生成アプリケーション130のユーザインターフェースを使用して取得される場合があります。
ステップ206では、クエリ理解コンポーネント140がクエリが有効かどうかを判断します。例えば、クエリが理解不能な場合は無効と見なされることがあります。ヒントコンポーネント150は、入力クエリに基づいてユーザにヒントを提供するために使用されます。システムのコンポーネントがユーザが望む結果を得られないと判断した場合、ヒントコンポーネント150がユーザにヒントを提供することがあります。例えば、ユーザの入力がバイアスがかかっていたり、有害であったり、理解不能であったりする場合、自然言語生成モデルの出力が有害であるかバイアスがかかっている場合、またはここで説明されている他のシナリオの場合、ヒントコンポーネント150がトリガーされる可能性があります。関連するヒントが特定できない場合は、一般的なガイドや指示がユーザに提供されることがあります。ヒントコンポーネント150は、ヒントコンポーネント150のトリガーの理由と、ヒントコンポーネント150のトリガーを引き起こしたデータの問題に関する情報をログに記録することがあります。記録された情報は、プロンプト設計コンポーネント115やクエリ理解コンポーネント140などのシステムの他のコンポーネントの改善に使用される場合があります。
ユーザからのクエリが有効である場合、ステップ208ではバイアス検出コンポーネント145が使用され、ユーザクエリにバイアスの可能性があるかどうかが判断されます。つまり、バイアス検出コンポーネント145は、ユーザクエリがバイアス、有害、関連性のない、またはその他の望ましくない出力を生む可能性があるかどうかを判断します。バイアス検出コンポーネント145は、ステップ208の判断のためにバイナリ(バイアス/バイアスでない)の出力を提供する場合があります。バイアス検出コンポーネント145はテキスト(例えば、ユーザクエリまたはモデルからの出力)にスコアを割り当て、そのスコアが閾値を超えることに基づいてステップ208での判断を行う場合があります。バイアス検出コンポーネント145が閾値を超えるバイアスの可能性を判断する場合、例えば、ステップ210で再びヒントコンポーネント150が使用され、より良いユーザクエリの提案やヒントが提供されます。バイアス検出コンポーネント145は、自然言語生成モデルの学習方法に基づいて重要な役割を果たします。前述のように、GPT-3はクリーニングやデバイアス処理がほとんど行われていないフィルタリングされていないテキストデータから学習します。ソースデータのバイアス、有害性、その他の問題は、モデルに引き継がれます。したがって、バイアス検出コンポーネント145は、攻撃的でバイアスのかかった、有害な、またはその他の望ましくない出力を防ぐのに役立ちます。バイアスの可能性が十分に低い場合、クエリ理解コンポーネント140はステップ212で意図検出を実行します。
意図検出には、ユーザクエリの意図を特定することが含まれます。意図検出のステップ212では、データ234からユーザの好みの履歴、現在のデッキのグローバル情報、および/または現在のデッキの編集履歴を使用して意図を特定します。意図検出は、ユーザクエリを自然言語モデリングを使用しないアクション(例:デザインリクエスト)または自然言語モデリングを使用するアクション(例:コンテンツリクエスト)のいずれかに分類します。したがって、クエリ理解コンポーネント140は、ユーザが非自然言語アクション(例:デザインの提案)または自然言語アクション(例:コンテンツの提案)を要求しているかどうかを判断します。ユーザが非自然言語アクションを要求している場合、ステップ214で非自然言語アクションが特定されます。これらのアクションは、コンテンツドキュメントの更新や提案の提供に直接使用することができます。例えば、コンテンツ生成アプリケーション130からのデザインや他のツールを使用して、ステップ216でオプションや新しいデザインやレイアウトを提供することができます。例えば、ユーザクエリが「背景を紫にする」というものである場合、デザインツールはいくつかの紫色の背景オプションを提供する可能性があります。ユーザは、どのオプションを選択するか、またはどのオプションを保持するかを決定ブロック218で選択することができます。ユーザが1つ以上のオプションを保持する場合、ステップ220でコンテンツドキュメントが更新され、システムはステップ202で新しいユーザクエリを待機する状態に戻ります。ユーザがオプションを保持しない場合、ステップ222でヒントコンポーネント150が使用され、ユーザが望む提案を得るためのヒントが提供されます。
図3は、たとえばシステム100を使用してインテリジェントなコンテンツを自動生成するための方法300を示しています。
ステップ305では、ユーザクエリが受信されます。たとえば、ユーザシステムデザインコンポーネントのユーザインターフェースを使用してユーザからクエリを取得することがあります。一部の実施例では、コンテンツデザインアプリケーション130のユーザインターフェースを使用してユーザからクエリを取得することがあります。ユーザクエリは、デザインの提案を要求する、コンテンツの提案を要求する、デザインとコンテンツの提案の組み合わせを要求する、またはその他の要求を含む、任意のリクエストまたはクエリです。クエリ理解コンポーネント(たとえば、クエリ理解コンポーネント140)は、不適切なユーザクエリを除外したり、コンテンツではないか、自然言語アクションを使用するクエリを適切なコンポーネントにルーティングしたりします。自然言語アクションを使用するユーザクエリは、クエリ理解コンポーネントによって特定され、ステップ310でユーザクエリの意図から自然言語アクションが決定されます。アクションのカテゴリが分類され、ユーザクエリ、アクション、および/またはアクションのカテゴリがプロンプトデザインコンポーネント(たとえば、プロンプトデザインコンポーネント115)に提供されます。プロンプトデザインコンポーネントは、決定されたアクションに基づいてステップ315でプロンプトを生成します。
ステップ320では、プロンプトが自然言語生成モデル(たとえば、自然言語生成モデル125)に提供されます(例:GPT-3など)。自然言語生成モデルはモデリングを行い、ステップ325ではモデルからの出力が受信されます。ステップ330では、出力を使用して応答コンテンツがコンテンツ生成アプリケーション(たとえば、ワープロアプリケーション、プレゼンテーション作成アプリケーションなど)と互換性のある形式で生成されます。応答コンテンツは、ユーザが選択するために1つ以上のオプションで提供される提案コンテンツです。ステップ335で応答コンテンツが表示されます。一部の実施例では、ユーザが選択した応答コンテンツでコンテンツドキュメントが更新され、コンテンツ生成アプリケーション130を介して表示されることがあります。
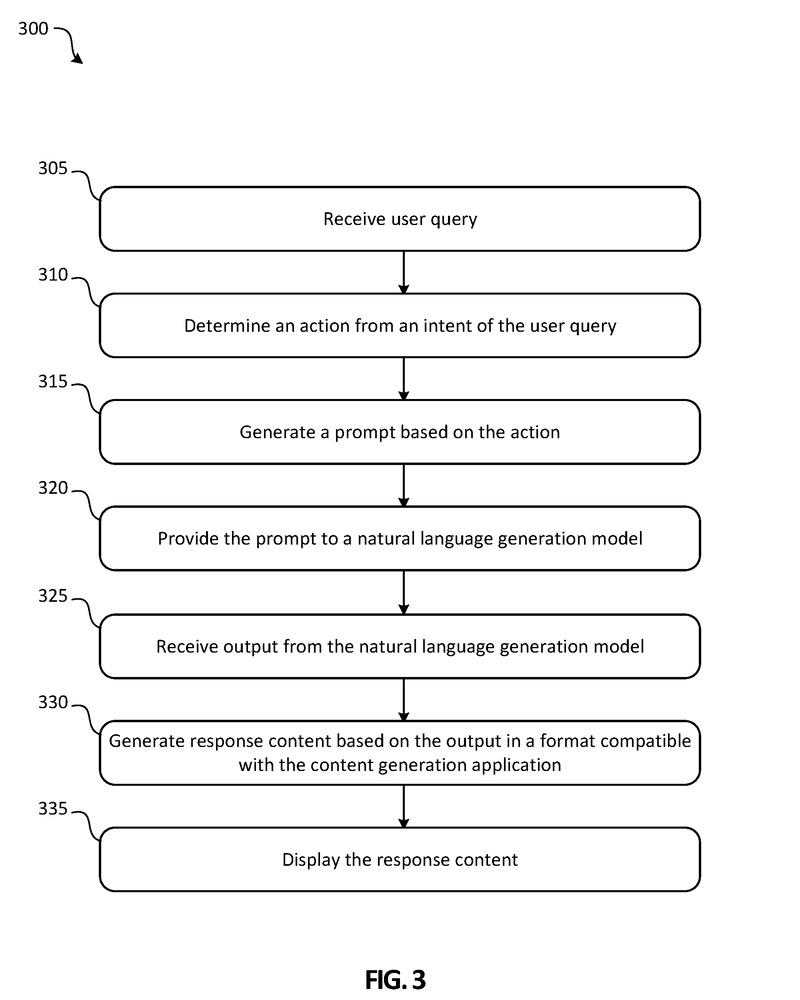
図4は、自動インテリジェントコンテンツ作成システム(たとえば、ユーザシステムデザインコンポーネント135、アプリケーション/サービスコンポーネント110)とのインタフェースに使用される、例示的なユーザインターフェース400を示しています。
ユーザインターフェース400は、ユーザにコンテンツの生成を行うために提供されます。
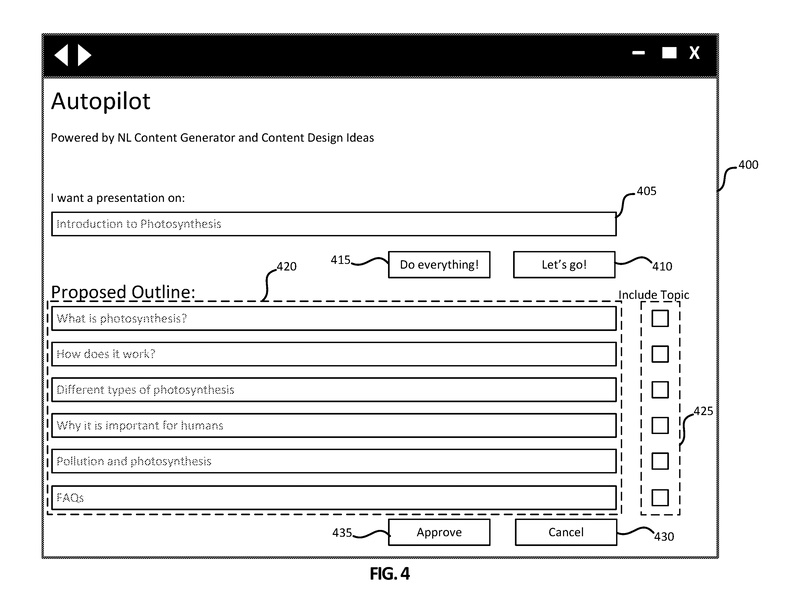
図4-9は、プレゼンテーションを生成するための例示的なユーザインターフェースを示していますが、トピック、オプションの数、レイアウト、デザインなどはすべて例示であり、変更が許容されることが本開示の範囲内で理解されるでしょう。
初期のユーザインターフェース400には、クエリボックス405、すべての操作を行うボタン415、Let’s goボタン410が含まれています。この特定のユーザインターフェース400は、ユーザが「光合成の紹介」としてクエリボックス405に表示されるタイトルに示されるように、MICROSOFT POWERPOINT®などのプレゼンテーション作成アプリケーションと共に使用されることがあります。
ユーザは、クエリボックス405に示されるように「光合成の紹介」と入力し、光合成の紹介を提供するプレゼンテーションを希望することを示します。ユーザがすべての操作を行うボタン415を選択すると、システムはプレゼンテーションを生成してユーザに提供することがあります。図示された例では、ユーザがLet’s goボタン410を選択し、提案された概要が提案セクション420に表示されます。
図5は、図4に示されるように、ユーザが提案された概要トピックと承認ボタン435を選択した後に生成される、例示的なグラフィカルユーザインターフェース500を示しています。
ユーザインターフェース500には、クエリボックス505とそれに関連する送信ボタン510が含まれています。提案オプションセクション525では、ユーザが選択するためにいくつかのタイトルスライドが提示されます。
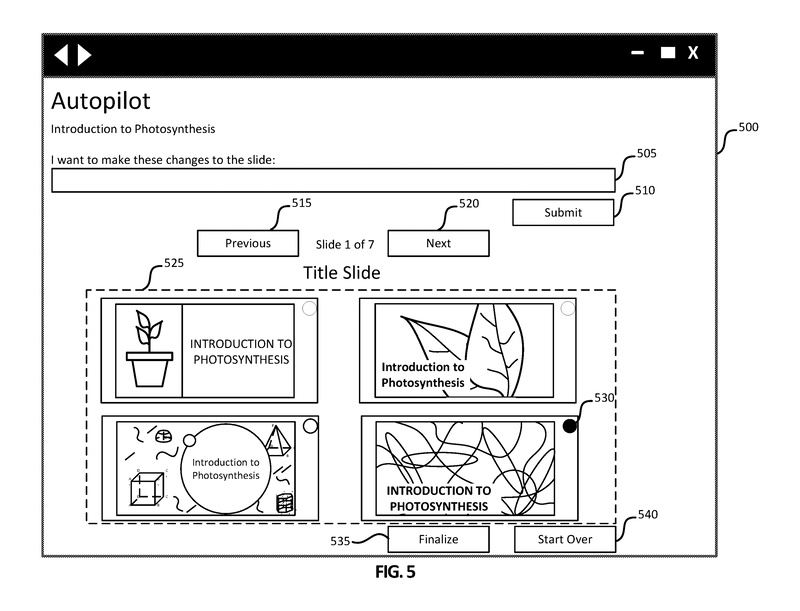
ユーザは、各選択肢の左上隅にあるラジオボタン(ラジオボタン530など)を使用して選択することができます。ユーザが選択したスライドに変更を要求する場合、ユーザはクエリボックス505にリクエストを入力し、送信ボタン510を選択します。クエリボックス505は、ユーザが提案されたオプションのコンテンツやデザインを反復的に更新する手段を提供し、ユーザが少なくとも1つのオプションに十分に満足するまで更新を行うことができます。
ユーザは、前のボタン515と次のボタン520を使用して、各トピックの提案されたオプションをスクロールして閲覧することができます。ユーザインターフェース500に示されているように、ユーザは7つのスライドのうち最初のスライドの提案オプションセクション525を表示しています。ユーザはユーザインターフェース400からすべての6つのトピックを選択しており、ユーザインターフェース500では7番目のスライドがタイトルスライドとして表示されています。ユーザは、ラジオボタン530で選択された右下のコーナーに表示されているスライドなどのオプションを選択し、次のボタン520を選択してオプションを進めることができます。ユーザは、選択済みの選択肢でプレゼンテーションを完成させるために、最終決定ボタン535をクリックすることができます。ユーザは、スタートオーバーボタン540を選択することで、プロセス全体を最初からやり直すことができます。この例では、ユーザはラジオボタン530に関連するスライドを選択し、次のボタン520を選択して続行しています。
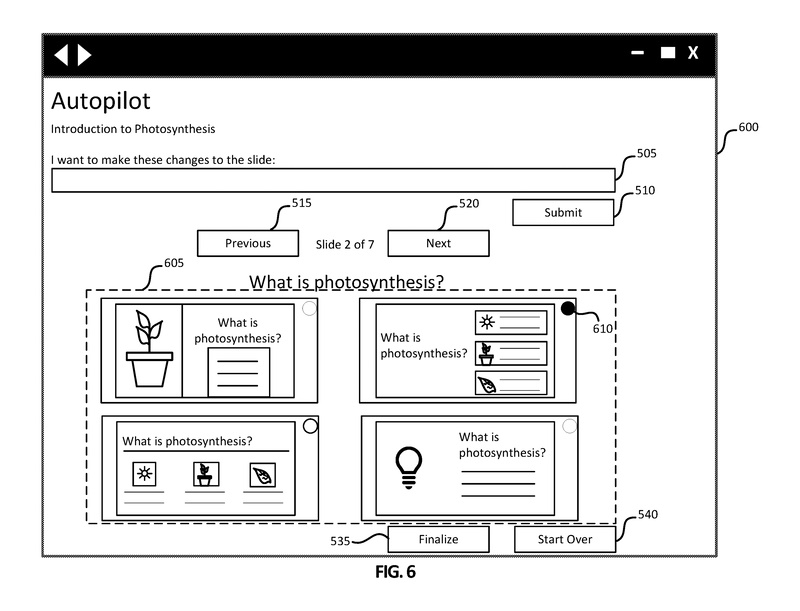
図6は、図5と同様の選択オプションを持つ、別の例示的なグラフィカルユーザインターフェース600を示しています。ユーザインターフェース600には、クエリボックス505、送信ボタン510、戻るボタン515、Nextボタン520、最終決定ボタン535、およびスタートオーバーボタン540が含まれています。
提案セクション605では、ユーザインターフェース500の提案セクション525とは異なる選択肢が提供されます。
図6に示されているように、7つのスライドのうち2番目のスライドのオプションが提案セクション605で選択可能です。さらに、提案されるオプションはスライド間で相関する場合があります。例えば、提案セクション605の左上隅の提案は、図5に示される提案セクション525の左上隅の提案と同様のデザイン、色、レイアウトなどを持つ場合があります。ユーザが各スライドのオプションをナビゲートするときに、一貫したデザインとレイアウトのオプションはユーザの利便性のために同じ順序で表示される可能性があります。この例では、ユーザはラジオボタン610に関連付けられたスライドの提案を選択し、次のボタン520を選択して3番目のスライドのオプションを表示します。
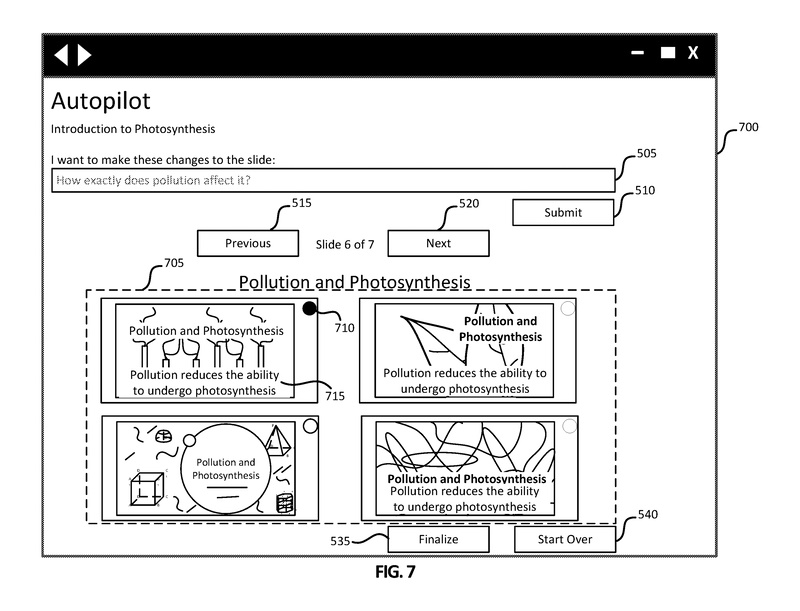
図7は、ユーザが7つのスライドのうち6番目のスライド(汚染と光合成のトピックを持つ)のオプションを表示している、別の例示的なグラフィカルユーザインターフェース700を示しています。提案セクション705には、6番目のスライドのオプションの提案が含まれています。描かれているように、汚染と光合成のオプションには4つのスライドオプションがあり、それぞれに対応するラジオボタンがあります。ラジオボタン710に関連付けられた選択されたスライドのテキストは、テキスト715に示されているように、「汚染は光合成を行う能力を低下させます」と述べています。この例では、ユーザはこのテキスト715が具体的ではないと考え、そのためクエリボックス505を使用して「汚染は具体的にどのように影響を与えるのですか?」と尋ねることができます。
ユーザは次に、クエリボックス505のクエリを提出するために送信ボタン510をクリックすることができます。ユーザの履歴、現在のスライドデッキなどの文脈を使用して、クエリ理解コンポーネントはクエリを処理して自然言語アクションを生成することができます。自然言語アクションは、現在のスライドデッキとユーザの履歴の文脈と共に使用され、プロンプトを設計して自然言語生成モデルに提出します。
出力は、応答コンテンツを生成するために使用され、ユーザインターフェース700は図8に示されるユーザインターフェース800を表示するために更新される場合があります。

図8は、ユーザがクエリボックス505に入力したリクエストの結果を反映させた後、7つのスライドのうち6番目のスライドの更新されたオプションを表示している例示的なグラフィカルユーザインターフェース800を示しています。
ユーザインターフェース800では、テキスト715がテキスト815に更新されて表示されています。「汚染は植物がクロロフィルをより少なく生成する原因です」というテキスト815が表示されています。提案セクション805の各オプションもテキスト815で更新されていますが、選択されたスライドのみが更新される場合もあります。ユーザはラジオボタン810に関連付けられたオプションを選択し、次のボタン520または前のボタン515を選択して、プレゼンテーションの他のトピックのスライドオプションを確認することができます。
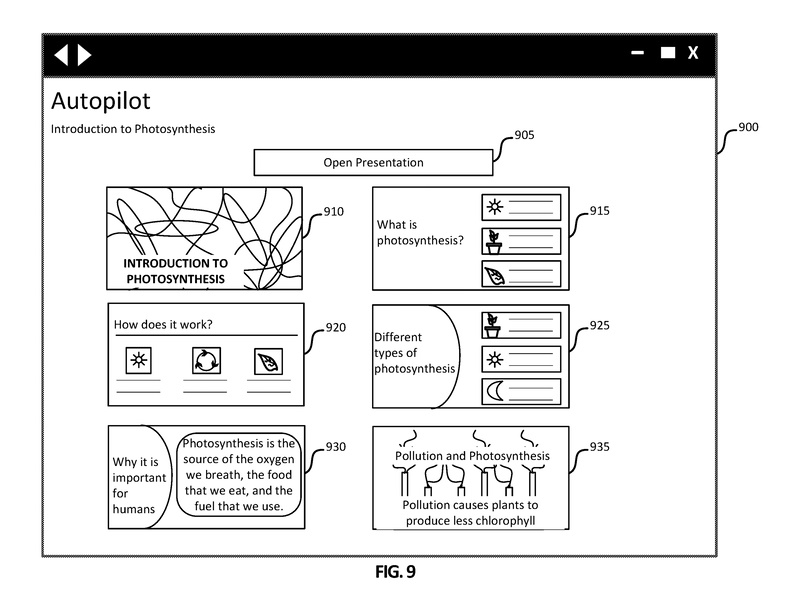
図9は、ユーザが最終化ボタン535を選択した後に生成される例示的なグラフィカルユーザインターフェース900を示しています。
各スライドの選択されたオプションがユーザに表示されます。選択されたオプションを含むコンテンツドキュメントは生成または更新される場合があります。ユーザインターフェース900には、開くボタン905と選択されたスライド910、915、920、925、930、935が含まれています。ユーザインターフェース900には、他の選択されたスライドを表示するために下にスクロールするためのスクロールバーが含まれている場合があります。ユーザが開くボタン905を選択すると、選択されたスライドを含むコンテンツドキュメントがMICROSOFT POWERPOINT®などのプレゼンテーション作成アプリケーションで開かれます。
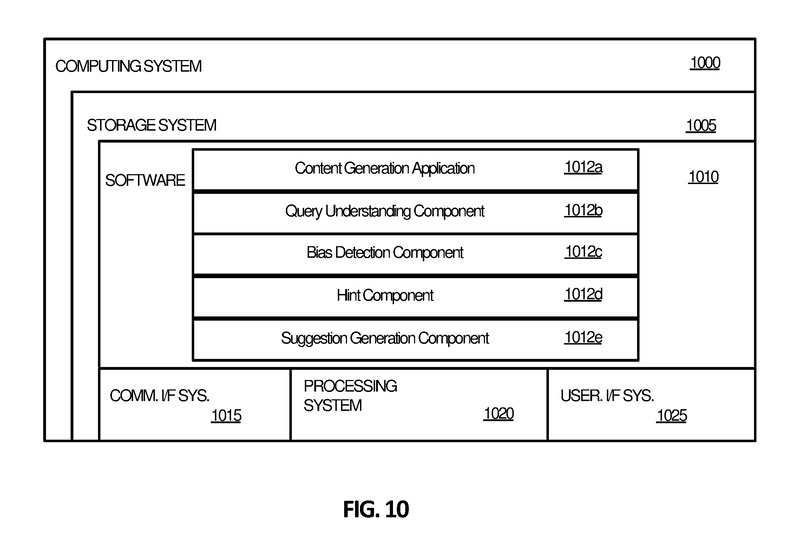
図10は、自動的なインテリジェントコンテンツ生成に関連する処理操作を実装するために適したコンピューティングシステム1000を示しています。コンピューティングシステム1000は、ユーザシステムデザインコンポーネント(例:図1のユーザシステムデザインコンポーネント135、アプリケーション/サービスコンポーネント110、プロンプトデザインコンポーネント115など)を含むなど、いかなるコンポーネントの処理操作も実装するように構成することができます。
したがって、コンピューティングシステム1000は、特定の目的のために構成されたコンピューティングデバイスであり、ユーザの制約されたテキスト入力に基づいてユーザに対してインテリジェントなコンテンツを生成するための処理操作を実行することができるというものになります。
ここがポイント!
本発明の自動インテリジェントコンテンツ生成システムは、コンテンツ生成アプリケーション内でコンテンツを作成するためのユーザクエリを受け取り、ユーザクエリの意図を読み取って、アクションを決定する処理を実行します。このアクションに基づいてプロンプトが生成され、自然言語生成モデルに提供されます。
プロンプトに対して、自然言語生成モデルからの出力が行われ、この出力に基づいて、コンテンツ生成アプリケーションと互換性のある形式でレスポンスコンテンツが生成されます。ユーザは、生成されたレスポンスコンテンツを保持、編集、または破棄することを選択できます。ユーザは、追加のクエリを繰り返すことで、コンテンツドキュメントがユーザの希望するコンテンツを反映するまで繰り返し操作できます。
未来予想
一昔前、作曲ソフトで予め用意されたテンプレートを組み合わせて曲を作っていくというものがありましたが、普段ビジネスで使用するOffice系ソフトウェアでもGPTモデルを活用して資料を自動生成させるようになるのは素晴らしい技術だと感じます。しかし、素晴らしいと感じる反面、自動生成ファイルからは単に紋切り型の同じような資料しか出てこない(肝心の伝えたいことが抜けている)かもしれないという危惧もありますね。また、機密情報の取り扱いなどもより一層の課題になりそうです。
特許の概要
|
発明の名称 |
Automated intelligent content generation |
|
出願番号 |
US17/152193 |
|
公開番号 |
US2022/0229832A1 |
|
特許番号 |
US11494396B2 |
|
優先日 |
2021.1.19 |
|
公開日 |
2022.7.21 |
|
登録日 |
2022.11.8 |
|
出願人 |
Microsoft Technology Licensing LLC |
|
発明者 |
Ji Li 他 |
| 国際特許分類 |
G06N 3/08 |
| 経過情報 |
36のファミリー件数があり、米国、欧州、日本、中国、韓国をはじめとして、各国に出願、特許登録されている。 |
ビルの壁面掃除ロボット

高層ビルなどの壁面清掃には、安全性等の観点から、古くから機械化が進んでおり、手動操作のロボットや特定の建物専用の高コストロボットが使用されていました。しかし、これらの方法は、建物の構造が変わると適応できず、特定の建物にしか使用できないという大きな問題がありました。
今回紹介する発明は、壁面の窓の配置に関わらず、自動的かつ効率的に壁面を清掃できる新しい方法、装置、システムに関するものです。具体的にどのような発明なのか、詳説していきます。
発明の背景
本発明は、建物の壁面の清掃を制御する方法、装置、システム、非一時的メモリに関します。
従来、例えば清掃員による手作業に頼らず建物の壁面を清掃するために、清掃ロボットを備えた清掃システムが使用されます。そのような清掃システムは、例えばビルの屋上からクレーンによって吊り下げられるフレーム(箱状の枠)に取り付けられます。この種の清掃システムでは、例えばロボットが人によって手動で操作されます。または、多額の費用をかけて開発された特定のロボットが、特定の建物のためだけに設計されます。この場合、特定の清掃システムは、他の建物に適用できず使用できません。
これに対して、ある種の清掃システムは、ロボットが清掃ルーチンのみを実行し、クレーンがフレームの昇降(上下移動)のみ実行して、ロボットが上下移動されるごとに清掃ルーチンを実行できるように設計されています。ロボットは、建物の構造に合わせて事前にプログラムされたルーチンに基づいて作動して清掃を進めます。同様に、クレーンは、建物の構造に合わせて事前にプログラムされたルーチン(例えば既知の窓のサイズおよび間隔)に基づいて移動するように設計されています。
したがって、ロボットは、特定の構造を有する建物用に設計されてしまうと、それ以外の構造の建物に使用できません。さらに、建物の壁面が意図せず変わる(例えば、一時的に窓が外側に開放される)と、クレーンやロボットは、その変化を自分自身で認識できません。
以上のような問題点があるため、建物の壁面を清掃するための新規な方法が要望されています。
どんな発明?
発明の目的
本発明は、フレーム(箱状の枠)を上下移動させるエレベータシステムの基幹ステーション(フレーム内に設置)によって建物壁面の清掃を制御する方法、装置、およびシステムなどを提供します。本発明によって、壁面の窓の配置に関わらず自動的かつ効率的に壁面を清掃できます。
本発明の方法では、建物の壁面の三次元マップに従って2つの命令を決定します。
2つの命令は、上記フレーム(箱状の枠)内にある基幹ステーション上のロボットアーム(清掃ツール)を制御するためのロボットアーム命令、および、基幹ステーションの位置を制御するための基幹ステーション命令です。
ロボットアーム命令および基幹ステーション命令は、壁面の清掃パターンを実行するために時間的に絡み合っています。すなわち、清掃ツールを有するロボットアームの動き、および、基幹ステーションを収容する上記フレーム(箱状の枠)の動きは、効率的となるようにうまく制御されます。
本発明では、ロボットアームの先端部(手首部分)にある清掃ツールは、例えばブラシであり、清掃パターンに従って動きます。本発明では、三次元マップ、清掃ツールの現在位置、および、基幹ステーションの上下移動に基づいて、ロボットアーム命令を計算します。ロボットアーム命令は、複数のロボットアームを同時に動作させます。
さらに本発明の方法では、清掃すべき壁面の選択、および、基幹ステーションのために計画された経路(上下移動または水平移動)に基づいて基幹ステーション命令を決定します。
例えば、本発明の方法では、現状の壁面がどのような状況であるかを把握するために、三次元マップを随時更新します。例えば、基幹ステーションにあるセンサ(カメラ)から得られたセンサデータを使用して、三次元マップを刻々と更新します。
本発明の方法やシステムでは、実施すべきタスクを手動または自動的に実行して完了できます。行うべきタスクは、ハードウェア、ソフトウェア、またはオペレーティングシステムなどによって実施されます。
発明の詳細
図面を参照して、本発明の具体例を説明します。本発明は、上述したように建物の壁面の清掃を制御するための方法、装置、システム、および、非一時的メモリに関します。
基幹ステーションは、建物の屋上から吊り下げられた建物メンテナンスエレベータの一部です。基幹ステーションは、ロボットアーム、および、ロボットアームを有するロボットシステムを備えます。基幹ステーションの上下移動は、自動的に制御されます。これに伴い、随時更新される壁面の三次元マップに適応した清掃パターンが生成されます。
三次元マップは、例えば壁面の変化(窓の開放など)を考慮して随時生成されます。三次元マップが随時生成されるため、ロボットアームの清掃パターン/ルーチンを別の建物でも使用できます。ロボットアームおよびエレベータの動作を別の建物のために手動で再カスタマイズする必要はありません。
三次元マップは、カメラシステムなどのセンサから得られた三次元データから確立されます。カメラは、互いに間隔をあけて複数配置され、異なる角度からそれぞれセンサ測定します。異なる角度からの測定値を使用すれば、正確な三次元マップを生成できます。
本発明の具体例では、オペレータは、三次元マップ上にマーキングすることによって清掃すべき壁面(例えば、窓)を決定できます。一方、システムによって事前に定義された経路を新しい別の経路に変更することも可能です。
例えば、オペレータは、ソフトウェアで検出された窓を建物の三次元モデル上で見て確認できます。オペレータは、その窓を(清掃される窓として)承認するか、または承認拒否できます。
一方、ソフトウェアで検出された窓が常に正しいとみなされてオペレータの介入余地がない場合もあります。
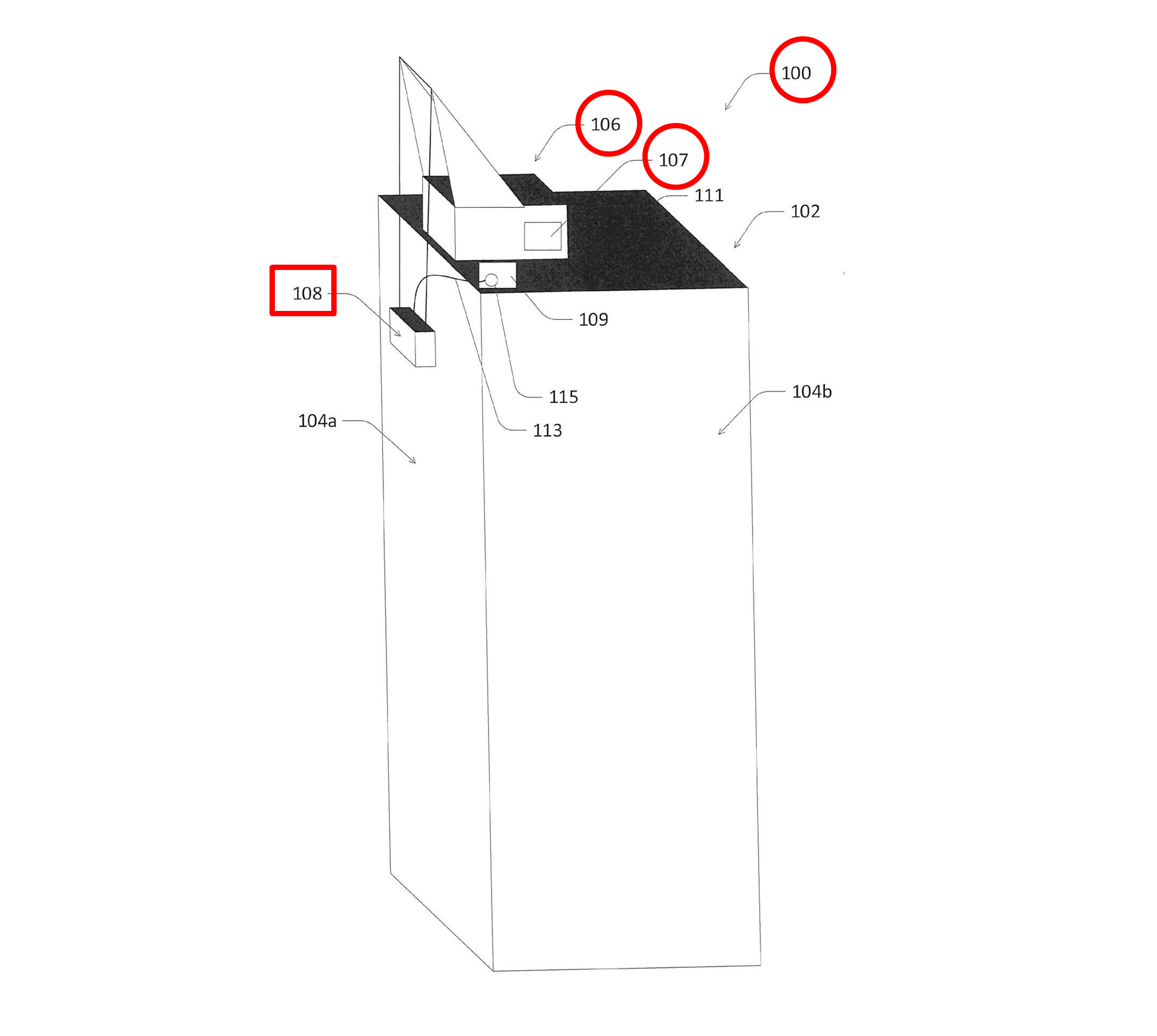
図1は、建物メンテナンスエレベータによる清掃サービスを受ける建物の概念図です。
 【図1】
【図1】
図1は、複数の壁面104a,104bを有する建物102を備えた構造物100を示します。クレーン106は、建物102の上部(屋上)に配置され、壁面104a,104bを清掃する建物メンテナンスエレベータ108を上方から吊り下げて支持します。クレーン106は、建物の壁面104aの各階部分が清掃されるように、建物メンテナンスエレベータ108を上下移動させる制御システム107を備えます。
図1に示される例では、壁面の全ての幅にわたって清掃できるように、クレーン106は、建物メンテナンスエレベータ108を横方向にも移動させるように構成される場合もあります。制御システム107は、クレーンと一体化していて、例えば、エレベータを上昇させるボタン、エレベータを下降させるボタンを作動させることによってエレベータを移動させる機械を備えます。制御システム107は、後に説明する処理機器221のような外部プロセッサと通信できます。このような通信として、例えばBluetooth(登録商標)が使用され得ます。
制御システム107は、有線または無線によって、遠隔装置から命令を受信できる通信手段を有します。制御システム107は、エレベータの昇降ボタンを作動させるのではなく、遠隔装置から(有線または無線接続によって)指令を受けてエレベータを上下に駆動できます。
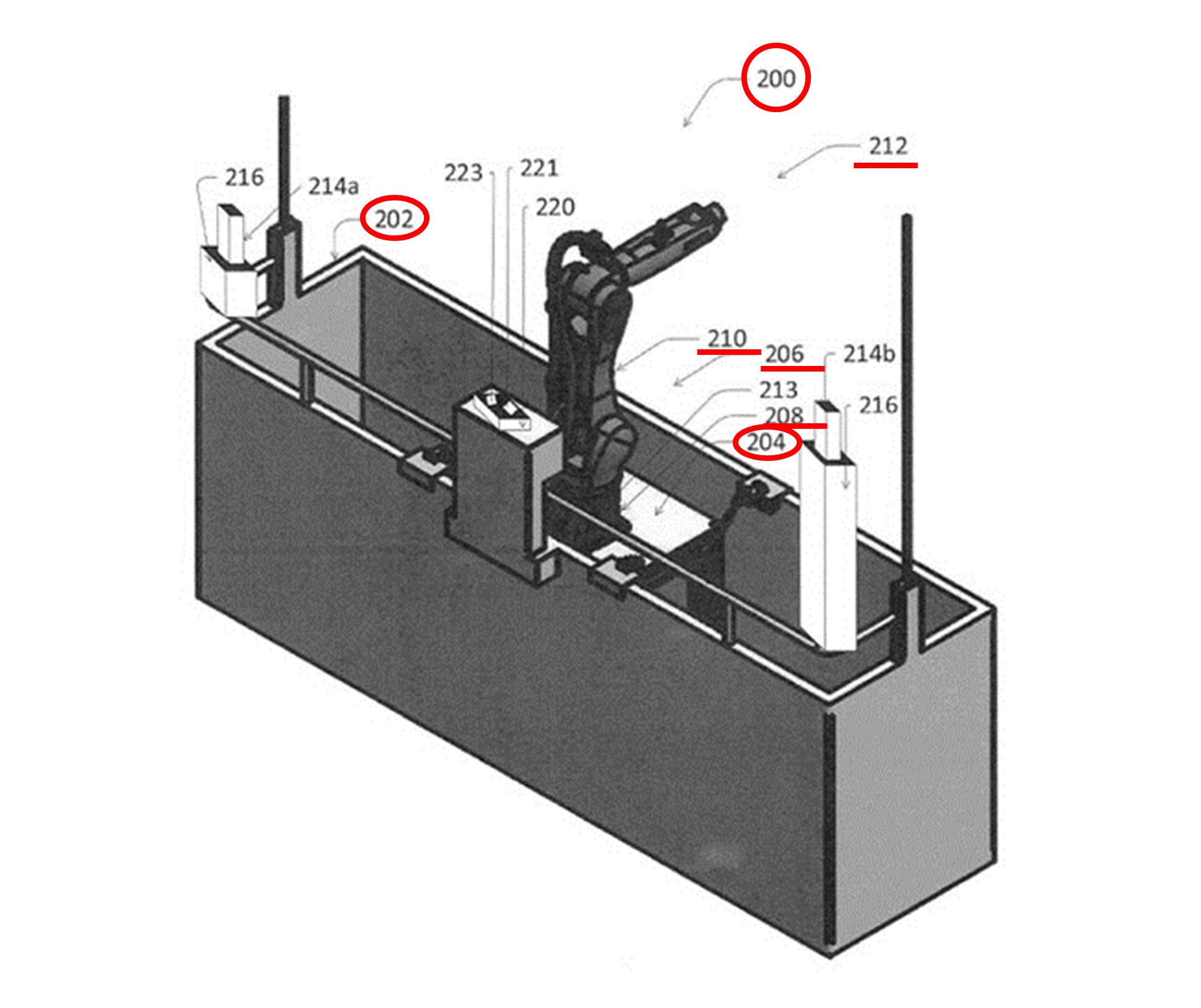
図2Aは、本発明に関わる建物メンテナンスエレベータの斜視図です。図2Bは、本発明で使用される清掃用具集合体の斜視図です。
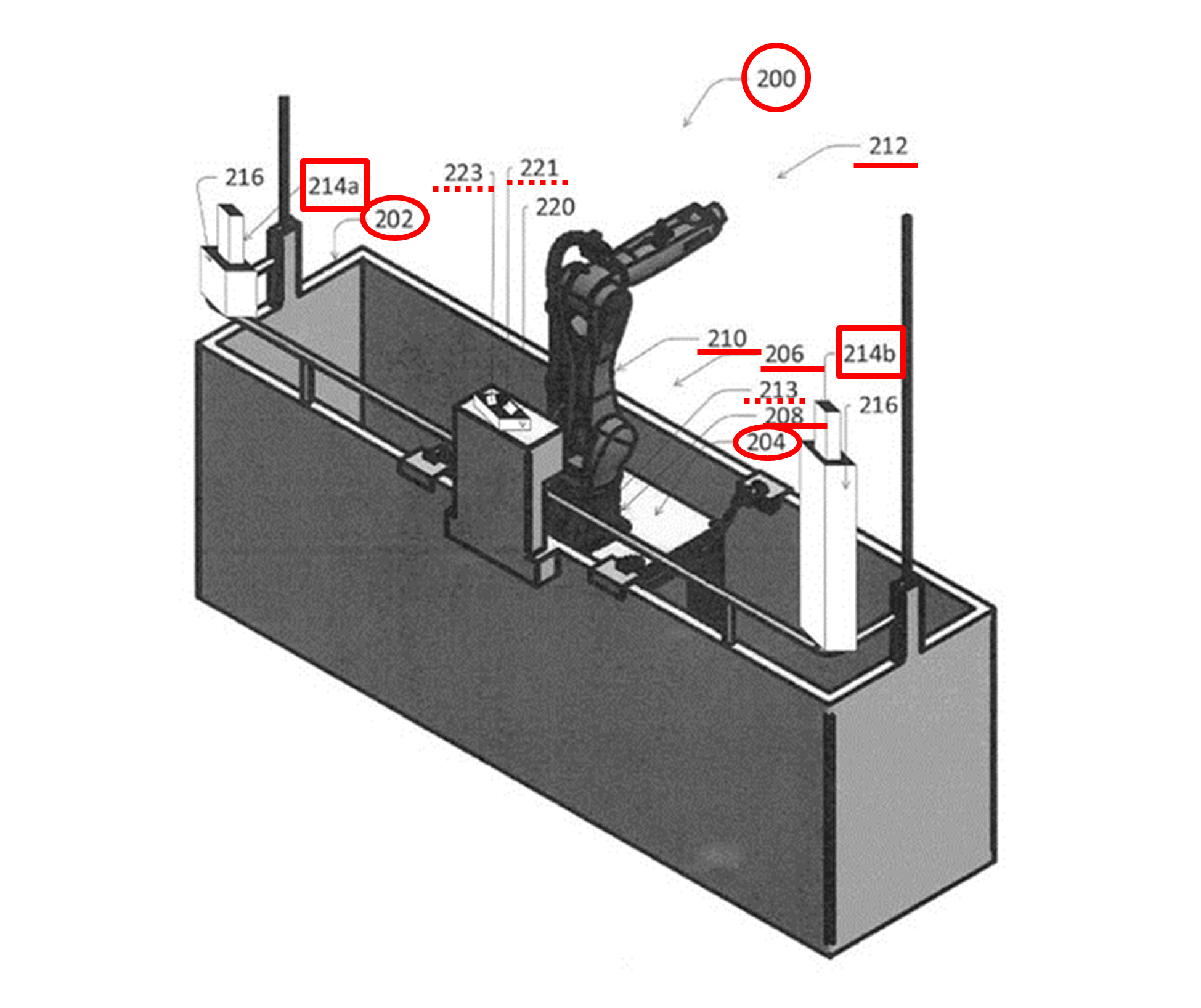
図2Aは、図1で示した建物メンテナンスエレベータ108に相当する、建物メンテナンスエレベータ200の拡大図です。このエレベータ200は、バスケット202(大型の箱)、および、ロボット206を取り付けるための支持構造物204を備えます。ロボット206は、支持構造物204に取り付けられた基部208、および、建物102の壁面104aを清掃するための清掃用具集合体250(図2B)を支持する手首部分212を有します。手首部分212は、ロボットアーム210の先端部分に取り付けられています。
ロボットアームは、液体浸透清掃システム109の清掃ツールを操作すべく自由に動ける動作部分です。ロボットアーム210は、縦横無尽に動けます。上下に移動できるクレーンによって、ロボットアーム210の上下移動を助けることも可能です。
液体浸透システム109は、図1に示すように、例えば建物102の屋根111上に配置され、水管113を使用して清掃ツールに水を供給するように構成されています。
 【図2A】
【図2A】
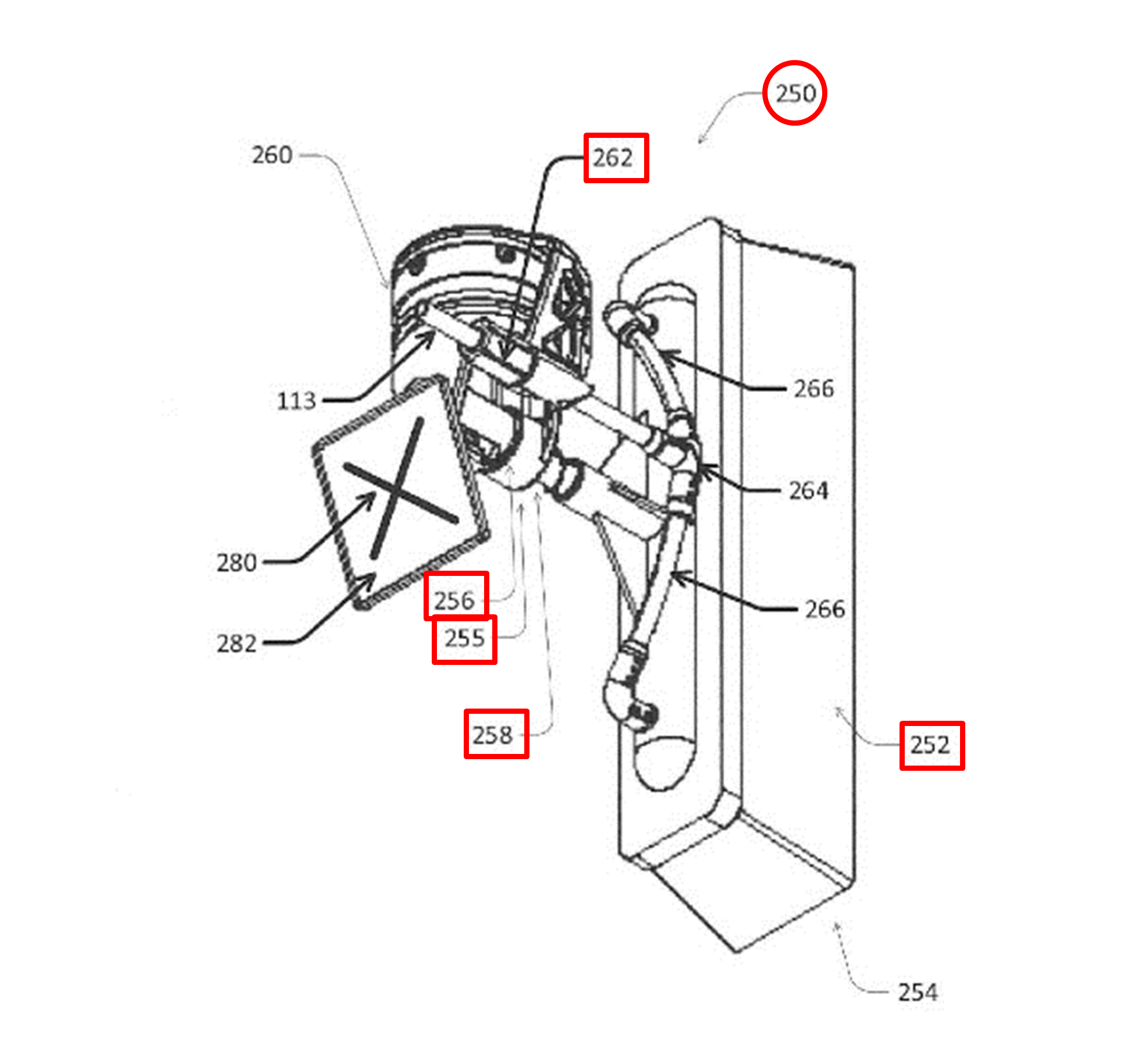
図2Bに示すように、清掃用具集合体250は、壁面に接触するように取り付けられた交換可能なブラシ252を有します。ブラシ252は、清掃用具集合体の支持体260から延びるブラシホルダ255によって保持されます。清掃用具集合体250は、例えばブラシホルダ255内に、壁面に対する接触力を測定する力学センサ256を有します。接触力は、例えばブラシホルダ255に対するブラシ252の変位に基づいて測定されます。この変位は、ブラシ252の圧縮に対抗するばね258を利用して把握できます。
清掃用具集合体250は、円筒状の穴を有する受水部262を有します。受水部262は、液体浸透システム109からの水を通す管113とつながり、管は、ブラシ252全体に水を供給するように複数の枝266に分かれています。
 【図2B】
【図2B】
図2Cは、ロボットアーム210に取り付けられた清掃用具集合体250(ロボットアームの手首部分)の斜視図です。
 【図2C】
【図2C】
図3A-図3Dは、ロボット206を取り付けるための支持構造物204を詳細に示しています。
図3Aは、支持構造物204にロボットアームが取り付けられた建物メンテナンス用エレベータフレームの平面図です。図3Aは、図2Aのフレーム202に相当する建物メンテナンス用エレベータフレーム302の平面図です。建物メンテナンス用エレベータフレーム302は、例えば箱状であり、底部を有します。支持構造物はテーブル304を有し、テーブル304の側面にサイドレール306が取り付けられています。
図3Bは、図3Aの建物メンテナンスエレベータの側面図です。図3Bは、支持構造物を側面図で示しています。図3Bに示されているように、テーブル304は、開口部330を有します。開口部には、処理機器331(コントローラ)が収容されています。
 【図3A】
【図3A】
 【図3B】
【図3B】
テーブル304内に収容された処理機器331は、例えばコンピュータであり、ロボットアームと通信します。ロボットアームの下のテーブル304内に処理機器331を配置することによって、エレベータフレーム302の重心を下げることができ、よって安定性を向上できます。重量をあまり増加させずに重心を下げることができるため、エレベータフレーム302は、重量制限内でより容易に維持され得ます。
サイドレール306は、長手方向に間隔をおいて配置された複数の穴308を有します。支持構造物は、エレベータフレーム302内の所定位置でテーブル304を固定するための固定部305を4つ有します。各固定部305は、複数の穴308のうち1つに固定される内側接続用金具307(図3A)を有します。
図3Aに示すように、エレベータフレーム302が支持構造物204よりも十分に大きい場合、内側接続用金具307は、レール306の最も外側の穴308に固定されます。一方、エレベータフレーム302が小さい場合、固定部の内側接続用金具307がレール306の最も内側の穴に嵌め込まれます。
なお、図示していませんが、エレベータフレーム302または352の内部に複数の支持構造物204を並べて配置して、複数のロボット206を収容することも可能です。例えば、1列に並べた複数のロボット206を1つのテーブル304によって支持することもできます。
図2Aに戻り、ロボット206は、基部208またはロボットアーム210内に、ロボットアーム210の手首部分212の動きを制御するための制御システムを備えます。ロボット206の制御システムは、(a)ロボットアームを動かすためにロボット内で通信するための内部通信手段、および、(b)外部装置と通信するための外部通信手段を有する処理システム(以下、処理機器213とも称します)を備えます。
 【図2A】
【図2A】
通信手段を使用してロボットアーム210を動かすために、例えば間隔をあけて支持体216に取り付けられた複数の測定装置214(a,b)が設けられます。本発明は、複数の測定装置214(a,b)からのセンサデータを受信するように構成された制御システムの処理機器213でもあります。
図2Aの具体例では、2つの測定装置(214a、214b)がありますが、より多くの測定装置がある場合もあります。本発明は、測定装置214の測定データを受信するために測定装置214との通信手段を提供したり、また、ロボット206との通信手段を提供したりする処理機器221(例えば処理システム)も提供します。
いずれの場合においても、処理機器213または処理機器221(以下では単に処理機器221と称します)は、命令を読み取って本発明を実行するために、非一時的メモリ223を内部に有したり、または非一時的メモリ223と通信したりします。処理機器221は、例えば測定装置214からセンサデータを受信し、測定装置206によって測定された壁面の三次元マップを生成して、メモリに格納します。その後、処理機器221は、三次元マップ、および、ロボットアームの手首部分の現在位置をメモリから読み出します。処理機器221は、例えば窓が配置されていない壁面104aを省略する清掃パターンを実行するために、命令をロボットアーム210に伝えます。処理機器221は、ロボットシステムのロボットアームを制御するために、ロボットアームに指示の命令を送信します。処理機器221は、クレーン106にある制御システム107に、建物メンテナンスエレベータの上下移動を制御するための指示命令を、通信手段を介して無線で送信します。処理機器221との間の通信は、直接通信手段、または中間通信手段を介して行われます。例えば、4Gルータを介した無線リンクが存在します。
本発明の具体例では、壁面の現在の状況を表す三次元マップを生成するために、センサデータが使用されます。三次元マップを最新の状態に保つために、三次元マップは、ロボットアームを制御するための命令と、建物メンテナンスエレベータの上下移動を制御するための命令と、を実行している間にも測定されて生成されます。時間を追って生成される三次元マップによって、以前に生成された三次元マップを更新することになります。三次元マップは、ロボットの清掃ツールが現在どこに存在するかを決定するために使用されます。
測定装置のセンサがカメラセンサである場合には、3つ以上のカメラのセンサデータを組み合わせて、三次元測定値を生成する場合もあります。一方で、カメラをさまざまな位置に移動させて、複数の画像を撮影し、それら画像から三次元データを生成することも可能です。カメラは、スマートフォンなどによって提供される場合があります。例えばカメラ214a,bは、図2Aに示すように、エレベータ外枠の角に配置されます。一方、図3Aに示される例において、例えばカメラ214(c-f)は、ロボットアーム210の周囲に配置されて支持構造物204に取り付けられ得ます。各カメラ214(c-f)は、清掃用具集合体が到達可能な全ての位置がカメラの視野に含まれるように配置されます。
図示しませんが、ロボットシステムは、複数のロボットアームを有する場合もあります。この場合、各ロボットアームは、図2Aのロボットアーム206の特徴を有します。そして、壁面をより迅速に清掃できるように、複数のロボットアームが同時に動作します。
本発明の制御システム221では、時間最適化のためにエレベータの移動経路が三次元マップから計算されて、エレベータフレームの移動が制御されます。例えば、エレベータの経路(例えば横方向の移動)は、より効率的な清掃経路のために最適化されます。最適化は、例えば、エレベータフレーム(箱状の外枠)が次に斜め下へ移動するときに、適切に左に移動させる距離を定義します。特に、窓が均等に分布していない建物では重要です。次の窓に移動するための最も適切な距離は、窓ごとに異なる場合があります。例えば、左へ1.2メートル移動する方が最適な場合もあれば、1メートル移動する方が好ましい場合もあります。壁面を清掃するための総時間をできるだけ短くするために、最適な経路は、清掃パターンおよび窓の位置を定義するパラメータから決定されます。
制御システム221は、清掃されたばかりの壁面104から、次に清掃されるべき壁面104へ移動するように、クレーンの制御システム107にエレベータ200の上下移動を指示し、清掃パターンを継続します。
本発明の制御システムは上記の例に限定されません。例えばオペレータ(操作者)は、清掃すべき壁面を選択できます。オペレータは、三次元マップを画像で表示するユーザ通信手段を介して、清掃すべき壁面に印を付けて壁面を選択します。このようなユーザ通信手段は、装置220上に表示されたり、装置220の装置処理機器221と通信するスマートフォン、タブレットなどの遠隔装置上に表示されたりします。例えばオペレータは、タブレット上に表示された三次元マップの画面上で、窓をマークまたは確認し、清掃すべきではない窓のマークを外したり確認したりできます。
別の例では、オペレータに頼るのではなく、清掃すべき窓を見つけるために機械学習が使用されます。窓を自動的に検出するために機械学習を採用する例では、オペレータは、清掃の実行前に窓のマーキングを確認または編集するだけで済みます。エレベータ200が上下移動していったん位置が決まると、清掃ツールの位置が再計算され、次に移動する新たな位置が決定されます。したがって、処理機器221からの一連の命令は、清掃パターンを実行するためにロボットアームおよびエレベータを交互にまたは同時に動かすように時間的に絡み合っています。
他の例では、壁面清掃のための全ての経路が最初に決定されます。すなわち、ロボットアームおよびエレベータの経路は、最初から最後まですべて計画されます。
上記の具体例では、三次元(3D)マップが生成されますが、一方、三次元マップの代わりに二次元マップが使用される場合もあります。例えば、窓の間隔や位置が規則的な建物の場合に二次元マップが使用されます。
ここがポイント!
以上説明しましたように、本発明の方法、装置、システムによって、壁面の窓の配置に関わらず自動的かつ効率的に壁面を清掃できます。
本発明は、建物(ビルなど)の壁面(104a)の清掃を制御するための方法などです。エレベータシステムの基幹ステーション(200)で生成された壁面(104a)を清掃する三次元マップに従って、命令が決定されます。命令は、少なくとも2つの命令で構成されています。一方の命令は、壁面(104a)の清掃パターンを実行するために時間的に絡み合っているロボットアーム命令であり、もう一方の命令は、基幹ステーション命令です。前者のロボットアーム命令は、ロボットアーム(206)を制御するための命令であり、後者の基幹ステーション命令は、基幹ステーション(200)の上下移動を制御するための命令です。また、上記本発明の方法を実施するための装置(221、213)、非一時的メモリ(223)、およびその装置を備えるシステムも本発明に含まれます。
未来予想
本特許出願は、イスラエルのSkyline Robotics(スカイライン・ロボティクス)社からPCT出願され、アメリカへ移行した段階です。同社は、特許2023年8月に約5億円の資金を調達できたと発表しています。資金調達には、日本およびシンガポールで権利化できた特許が深く関与しているようです。
スカイライン・ロボティクス社は、「OZMO」という窓拭きロボットを開発して製品化しています。この製品は、イスラエル国のテルアビブやアメリカニューヨークの高層ビルで採用された実績があり、上述したような構造を有しています
本発明は、上記製品に活かされていると予想されます。本発明の利点は、作業者の危険作業を回避し、しかも人力よりもはるかに速く窓拭きが完了できる点です。慢性的な人手不足と言われている日本国では、このような作業ロボットが活躍できる機会は、かなり多いと考えられます。
特許の概要
|
発明の名称 |
DEVICE AND METHOD FOR USE IN CLEANING A FAÇADE(壁面の清掃に使用する装置および方法) |
|
出願番号 |
US. 2019 16/967,830(アメリカ出願) |
|
公開番号 |
US. 2021/0040757(アメリカ公開公報) |
|
出願日 |
2019.02.07(PCT出願日) |
|
公開 |
2021.02.11(公開公報) |
|
出願人 |
Skyline Robotics Ltd.(スカイライン ロボティクス リミテッド) |
|
発明者 |
ABADI Avi(アバディ アヴィ)SCHWARCZ Yaron(シュヴァルツ ヤロン) |
| 国際特許分類 |
B25J 9/16 |
| 経過情報 |
・本願はPCT出願からアメリカへ移行した出願です。アメリカではまだ特許となっていませんが、PCT出願から日本へ移行した日本出願はすでに特許となっています。 |
動きで話す、技術で理解する

私たちの日常生活において、音声認識技術はもはや新しいものではありません。スマートフォンやスマートスピーカーを通じて、「Hey Siri」や「OK Google」といったフレーズは、私たちの生活に溶け込んでいます。
しかし、この技術にはまだ改善の余地があります。特に、騒がしい環境やプライバシーが重視される場面では、音声認識の限界が露呈します。ここで、本発明で提示される「動作センシングを使用したキーワード検出」が登場します。
この技術は、ユーザーの顔や頭部の微細な動きを検出することで、特定のキーワードやフレーズを認識します。たとえば、ユーザーが「Hey Siri」と言うときの顔の筋肉の動きや頭部の振動など、微妙な動きを捉えることができます。これは、従来の音声認識技術とは異なり、周囲の騒音に左右されることなく、より正確な認識が可能になるのです。
具体的にどのような発明なのか、詳説していきます。
発明の背景
従来の音声認識システムは、主にオーディオセンサー(マイクロフォンなど)を使用して、ユーザーの声を捉え、特定のキーワードやフレーズを認識することでデバイスを操作する技術です。これらのシステムは、音声コマンドに基づいて様々なタスクを実行することができ、スマートフォン、スマートスピーカー、車載システムなど、多くのデバイスに組み込まれています。しかしながら、従来のシステムでは、次のような問題点が指摘されていました。
1.騒音環境下での性能低下: 従来の音声認識システムは、周囲が騒がしい環境や、複数の人が話している場合に、正確にキーワードを認識するのが難しくなります。背景ノイズや他の音声がシステムの性能に大きく影響を与えるため、特に公共の場所や騒がしい家庭環境では、認識率が著しく低下することがあります。
2.プライバシーへの懸念: 音声認識は、ユーザーが声を使ってコマンドを発する必要があるため、プライバシーに敏感な環境や公共の場では使用が制限されることがあります。声を録音されることへの抵抗感や、周囲の人々に聞かれたくない内容を話すことへの不安が、使用を妨げる要因となり得ます。
3.アクセシビリティの問題: 言語障害を持つ人々や、声を出すことが困難な人々にとって、従来の音声認識システムは使いにくい、または全く使えない場合があります。これにより、これらのユーザーがテクノロジーの恩恵を受ける機会が限られてしまいます。
4.限定された応用範囲: 従来の音声認識システムは、主に音声コマンドに依存しているため、その応用範囲が限定されています。例えば、静かな環境や、音声を使いたくない状況では、ユーザーは他の操作方法を求めることになります。
これらの問題点は、音声認識技術の普及とともにより顕著になり、新しい解決策の必要性を高めています。特に、ユーザーのプライバシーを保護し、より多様な環境や状況で利用できる音声認識システムの開発が求められています。
どんな発明?
発明の目的
この発明は、ユーザーの顔や頭部の微細な動きを検出し、これを特定のキーワードやフレーズと関連付けます。例えば、ユーザーが「Hey Siri」と言う際の顔の筋肉の動きや頭部の振動を検出し、これを参照データと照合することで、キーワードを認識します。このアプローチにより、周囲の騒音や他の音声に影響されることなく、より正確かつ迅速にキーワードを認識することが可能になります。
発明の詳細
それでは、図面も参照しながら、本発明の詳細について見ていきます。
<システムと環境>
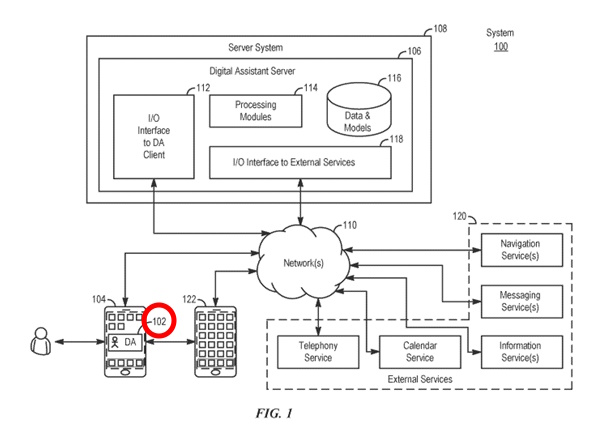
図1は、様々な例に基づいたシステム100のブロック図を示しています。一部の例では、システム100はデジタルアシスタントを実装しています。「デジタルアシスタント」、「バーチャルアシスタント」、「インテリジェントオートメーションアシスタント」、または「自動デジタルアシスタント」という用語は、話し言葉および/またはテキスト形式での自然言語入力を解釈し、ユーザーの意図を推測し、推測されたユーザーの意図に基づいて行動を実行する情報処理システムを指します。
例えば、推測されたユーザーの意図に基づいて行動するために、システムは以下の一つまたは複数を実行します:推測されたユーザーの意図を達成するために設計されたステップとパラメータを持つタスクフローを特定し、推測されたユーザーの意図から特定の要件をタスクフローに入力し、プログラム、方法、サービス、APIなどを呼び出してタスクフローを実行し、聴覚的(例えば、音声)および/または視覚的形式でユーザーに出力応答を生成します。
このようなデジタルアシスタントは、自然言語のコマンド、リクエスト、声明、物語、および/または問い合わせの形式で少なくとも部分的にユーザーのリクエストを受け入れることができます。
通常、ユーザーのリクエストは、情報的な回答またはデジタルアシスタントによるタスクの実行を求めます。ユーザーのリクエストに対する満足のいく応答には、要求された情報的な回答の提供、要求されたタスクの実行、またはその両方の組み合わせが含まれます。例えば、ユーザーがデジタルアシスタントに「今、私はどこにいますか?」と質問すると、デジタルアシスタントはユーザーの現在の位置に基づいて「あなたはセントラルパークの西ゲート近くにいます」と答えます。また、ユーザーはタスクの実行をリクエストすることもあります。
例えば、「来週、私の彼女の誕生日パーティーに私の友達を招待してください」というリクエストです。これに対して、デジタルアシスタントは「はい、すぐに」と応答して、ユーザーの電子アドレス帳に記載されている各友人に適切なカレンダー招待状をユーザーの代わりに送ることができます。要求されたタスクの実行中、デジタルアシスタントは時にユーザーとの間で、長期にわたる複数の情報交換を含む継続的な対話でやり取りすることがあります。情報のリクエストや様々なタスクの実行をデジタルアシスタントに依頼する他の多くの方法があります。口頭での応答やプログラムされた行動を取るだけでなく、デジタルアシスタントはテキスト、アラート、音楽、ビデオ、アニメーションなど、他の視覚的または聴覚的な形式での応答も提供します。
図1に示されたデジタルアシスタントは、クライアント側部分(例えば、DAクライアント102)とサーバー側部分(例えば、DAサーバー106)の両方を含んでいますが、一部の例では、デジタルアシスタントの機能は、ユーザーデバイスにインストールされたスタンドアロンアプリケーションとして実装されていてもよいでしょう。さらに、デジタルアシスタントのクライアント部分とサーバー部分の間の機能の分割は、異なる実装で異なる場合もあります。
たとえば、一部の例では、DAクライアントは、ユーザー向けの入出力処理機能のみを提供するシンクライアントであり、デジタルアシスタントの他のすべての機能をバックエンドサーバーに委任します。
<電子デバイス>
ここでは、デジタルアシスタントのクライアント側部分を実装するための電子デバイスの実施形態に注目します。図2Aは、いくつかの実施形態に従って、タッチ感応ディスプレイシステム212を備えた携帯多機能デバイス200を示すブロック図です。デバイス200には、メモリ202(1つ以上のコンピュータ可読記憶媒体を含むことがある)、メモリコントローラー222、1つ以上の処理ユニット(CPU)220、周辺機器インターフェース218、RF回路208、オーディオ回路210、スピーカー211、マイクロフォン213、入出力(I/O)サブシステム206、その他の入力制御デバイス216、および外部ポート224が含まれています。
デバイス200には、オプションで1つ以上の光センサー264が含まれています。デバイス200には、オプションでデバイス200上の接触の強度を検出するための1つ以上の接触強度センサー265が含まれています(例えば、デバイス200のタッチ感応ディスプレイシステム212などのタッチ感応表面)。デバイス200には、オプションでデバイス200上で触覚出力を生成するための1つ以上の触覚出力ジェネレーター267が含まれています(例えば、デバイス200のタッチ感応ディスプレイシステム212やデバイス400のタッチパッド455などのタッチ感応表面上で触覚出力を生成する)。
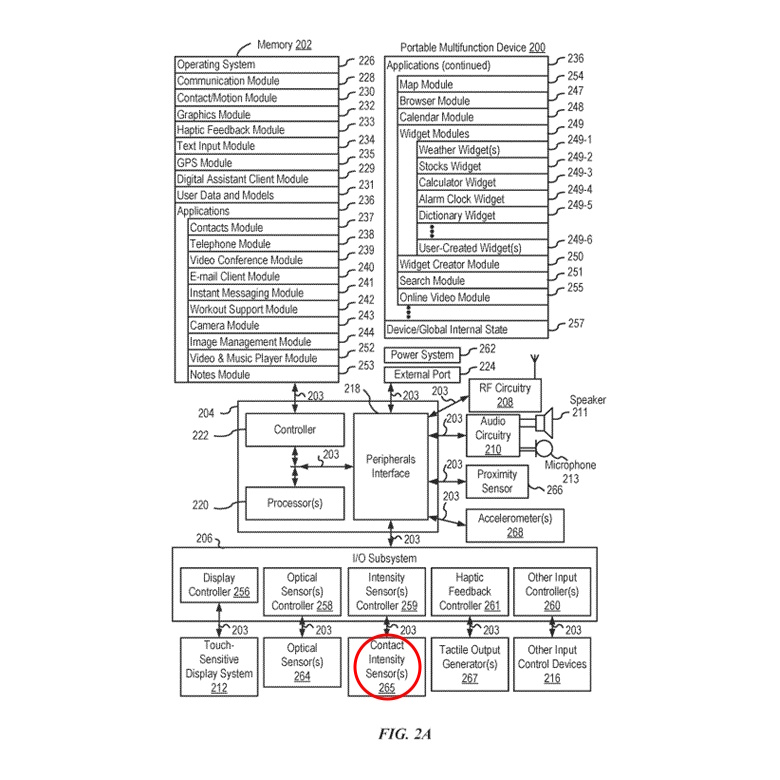
タッチスクリーン212は、LCD(液晶ディスプレイ)技術、LPD(発光ポリマーディスプレイ)技術、またはLED(発光ダイオード)技術を使用しますが、他のディスプレイ技術も他の実施形態で使用される場合があります。タッチスクリーン212およびディスプレイコントローラ256は、既知のタッチセンシング技術の多様性を使用して、接触およびその動きまたは解除を検出します。これには、静電容量式、抵抗式、赤外線式、表面音波式など、現在知られているまたは後に開発されるタッチセンシング技術が含まれます。また、タッチスクリーン212との接触点を決定するための近接センサーアレイやその他の要素も使用されます。一例として、Apple Inc.のiPhone®およびiPod Touch®に見られるような、予測相互静電容量センシング技術が使用されます。
デバイス200には、オプションで一つ以上の接触強度センサー265も含まれています。図2Aでは、I/Oサブシステム206内の強度センサーコントローラー259に接続された接触強度センサーが示されています。接触強度センサー265には、圧電抵抗型ひずみゲージ、静電容量型力センサー、電気力センサー、圧電力センサー、光力センサー、静電容量型タッチセンシティブ表面、またはその他の強度センサー(例えば、タッチセンシティブ表面上の接触の力(または圧力)を測定するために使用されるセンサー)が含まれることがあります。接触強度センサー265は、環境からの接触強度情報(例えば、圧力情報または圧力情報の代理)を受け取ります。一部の実施形態では、少なくとも一つの接触強度センサーは、タッチセンシティブ表面(例えば、タッチセンシティブディスプレイシステム212)と同じ場所に配置されるか、またはその近くに配置されます。一部の実施形態では、少なくとも一つの接触強度センサーはデバイス200の背面に配置され、デバイスの前面にあるタッチスクリーンディスプレイ212と反対側にあります。
接触/動作モジュール230は、ユーザーによるジェスチャー入力を検出します。タッチセンシティブ表面上の異なるジェスチャーには、異なる接触パターンがあります(例えば、検出された接触の異なる動き、タイミング、および/または強度)。したがって、ジェスチャーは、特定の接触パターンを検出することによって、オプションで検出されます。たとえば、指のタップジェスチャーを検出するには、指が下がったイベントを検出した後に、指が下がったイベントと同じ位置(または実質的に同じ位置)で指が上がった(離陸)イベントを検出することを含みます(例えば、アイコンの位置で)。別の例として、タッチセンシティブ表面上での指のスワイプジェスチャーを検出するには、指が下がったイベントを検出した後に、一つ以上の指のドラッグイベントを検出し、その後に指が上がった(離陸)イベントを検出することを含みます。
タッチスクリーンおよび/またはタッチパッドを介して排他的に実行される事前に定義された機能のセットには、ユーザーインターフェース間のナビゲーションが含まれることがあります。一部の実施形態では、ユーザーがタッチパッドに触れると、デバイス200が表示されている任意のユーザーインターフェースからメイン、ホーム、またはルートメニューにナビゲートします。このような実施形態では、「メニューボタン」はタッチパッドを使用して実装されます。他の実施形態では、メニューボタンはタッチパッドではなく、物理的な押しボタンまたは他の物理的な入力制御デバイスです。
図2Bは、一部の実施形態に従ったイベント処理のための例示的なコンポーネントを示すブロック図です。一部の実施形態では、メモリ202(図2A)または470(図4)には、イベントソーター270(例えば、オペレーティングシステム226内)と、それぞれのアプリケーション236-1(例えば、前述のアプリケーション237-251、255、480-490のいずれか)が含まれます。
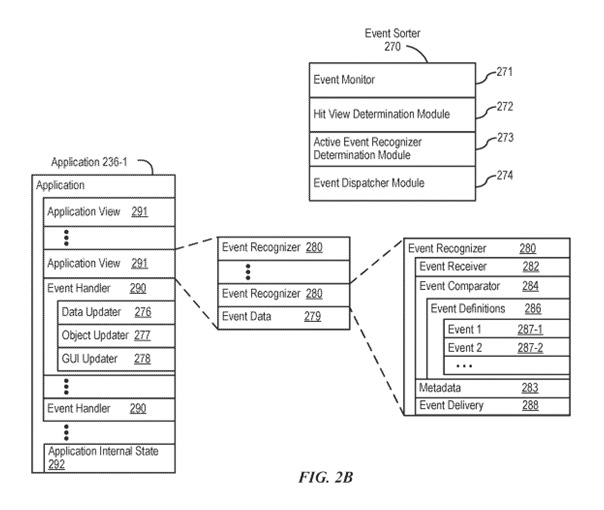
イベントソーター270はイベント情報を受け取り、イベント情報を配信するアプリケーション236-1およびアプリケーションビュー291を決定します。イベントソーター270にはイベントモニター271とイベントディスパッチャーモジュール274が含まれます。一部の実施形態では、アプリケーション236-1にはアプリケーション内部状態292が含まれ、これはアプリケーションがアクティブまたは実行中のときにタッチ感応ディスプレイ212に表示される現在のアプリケーションビューを示します。一部の実施形態では、デバイス/グローバル内部状態257がイベントソーター270によって現在アクティブなアプリケーションを決定するために使用され、アプリケーション内部状態292がイベントソーター270によってイベント情報を配信するアプリケーションビュー291を決定するために使用されます。
イベント比較器284は、イベント情報を事前定義されたイベントまたはサブイベントの定義と比較し、その比較に基づいてイベントまたはサブイベントを特定するか、イベントまたはサブイベントの状態を決定または更新します。一部の実施形態では、イベント比較器284にはイベント定義286が含まれています。イベント定義286には、例えば、イベント1(287-1)、イベント2(287-2)などのイベントの定義が含まれています。一部の実施形態では、イベント(287)のサブイベントには、例えば、タッチ開始、タッチ終了、タッチの動き、タッチのキャンセル、複数のタッチが含まれます。一つの例として、イベント1(287-1)の定義は、表示されたオブジェクトへのダブルタップです。ダブルタップは、例えば、所定のフェーズの表示オブジェクトへの最初のタッチ(タッチ開始)、所定のフェーズの最初の離陸(タッチ終了)、所定のフェーズの表示オブジェクトへの2回目のタッチ(タッチ開始)、および所定のフェーズの2回目の離陸(タッチ終了)で構成されます。別の例では、イベント2(287-2)の定義は、表示されたオブジェクト上でのドラッグです。ドラッグは、例えば、所定のフェーズの表示オブジェクトへのタッチ(または接触)、タッチ感知ディスプレイ212上を横切るタッチの動き、およびタッチの離陸(タッチ終了)で構成されます。一部の実施形態では、イベントには関連する一つ以上のイベントハンドラー290の情報も含まれます。
一部の実施形態では、イベント定義287には、それぞれのユーザーインターフェースオブジェクトのイベントの定義が含まれています。一部の実施形態では、イベント比較器284はヒットテストを実行して、サブイベントに関連するユーザーインターフェースオブジェクトを特定します。例えば、タッチ感知ディスプレイ212上に3つのユーザーインターフェースオブジェクトが表示されているアプリケーションビューでは、タッチ感知ディスプレイ212上でタッチが検出されると、イベント比較器284はヒットテストを実行して、タッチ(サブイベント)に関連する3つのユーザーインターフェースオブジェクトのうちのどれかを特定します。表示された各オブジェクトがそれぞれのイベントハンドラー290に関連付けられている場合、イベント比較器はヒットテストの結果を使用して、どのイベントハンドラー290がアクティブ化されるべきかを決定します。例えば、イベント比較器284は、ヒットテストをトリガーするサブイベントとオブジェクトに関連付けられたイベントハンドラーを選択します。
一部の実施形態では、それぞれのイベント(287)の定義には、サブイベントのシーケンスがイベント認識器のイベントタイプに対応しているかどうかが決定されるまでイベント情報の配信を遅延させる遅延アクションも含まれています。
それぞれのイベント認識器280が、サブイベントのシリーズがイベント定義286のいずれのイベントにも一致しないと判断した場合、それぞれのイベント認識器280はイベント不可能、イベント失敗、またはイベント終了の状態に入り、その後、タッチベースのジェスチャーの後続のサブイベントを無視します。この状況では、ヒットビューに対してアクティブなままの他のイベント認識器(存在する場合)は、進行中のタッチベースのジェスチャーのサブイベントを追跡し、処理し続けます。
一部の実施形態では、それぞれのイベント認識器280には、メタデータ283が含まれ、これには設定可能なプロパティ、フラグ、および/またはアクティブに関与するイベント認識器へのサブイベント配信をイベント配信システムがどのように実行すべきかを示すリストが含まれています。一部の実施形態では、メタデータ283には、イベント認識器が互いにどのように相互作用するか、または相互作用することが可能であるかを示す設定可能なプロパティ、フラグ、および/またはリストが含まれています。一部の実施形態では、メタデータ283には、サブイベントがビューまたはプログラム階層の異なるレベルに配信されるかどうかを示す設定可能なプロパティ、フラグ、および/またはリストが含まれています。
一部の実施形態では、それぞれのイベント認識器280は、イベントの特定のサブイベントが認識されると、イベントに関連付けられたイベントハンドラー290をアクティブ化します。一部の実施形態では、それぞれのイベント認識器280は、イベントに関連するイベント情報をイベントハンドラー290に配信します。イベントハンドラー290をアクティブ化することは、サブイベントをそれぞれのヒットビューに送信する(および遅延送信する)こととは異なります。一部の実施形態では、イベント認識器280は認識されたイベントに関連付けられたフラグを投げ、フラグに関連付けられたイベントハンドラー290がフラグをキャッチして事前定義されたプロセスを実行します。
タッチ感知ディスプレイ上のユーザータッチのイベント処理に関する前述の議論は、タッチスクリーン上で開始されるものに限らず、入力デバイスを備えた多機能デバイス200を操作するための他の形態のユーザー入力にも適用されることが理解されるべきです。例えば、マウスの動きやマウスボタンの押下、オプションで単一または複数のキーボードの押下または保持と連動するもの;タッチパッド上のタップ、ドラッグ、スクロールなどの接触動作;ペンスタイラスの入力;デバイスの動き;口頭の指示;検出された目の動き;生体認証入力;および/またはこれらの任意の組み合わせは、イベントを定義するサブイベントに対応する入力としてオプションで使用されます。
図3は、一部の実施形態に従ってタッチスクリーン212を備えた携帯型多機能デバイス200を示しています。タッチスクリーンはオプションで、ユーザーインターフェース(UI)300内の1つ以上のグラフィックスを表示します。この実施形態および以下で説明される他の実施形態では、ユーザーは、例えば1つ以上の指302(図では実際のスケールでは描かれていません)または1つ以上のスタイラス303(図では実際のスケールでは描かれていません)を使用してグラフィックス上でジェスチャーを行うことにより、1つ以上のグラフィックスを選択することができます。
一部の実施形態では、ユーザーが1つ以上のグラフィックスとの接触を解除するときに、1つ以上のグラフィックスの選択が行われます。一部の実施形態では、ジェスチャーには、1つ以上のタップ、1つ以上のスワイプ(左から右、右から左、上方および/または下方)、および/またはデバイス200に接触した指のローリング(右から左、左から右、上方および/または下方)が含まれることがあります。一部の実装または状況では、グラフィックスに対する偶発的な接触は、グラフィックスを選択しません。例えば、アプリケーションアイコンを通過するスワイプジェスチャーは、選択に対応するジェスチャーがタップである場合、対応するアプリケーションを選択しません。
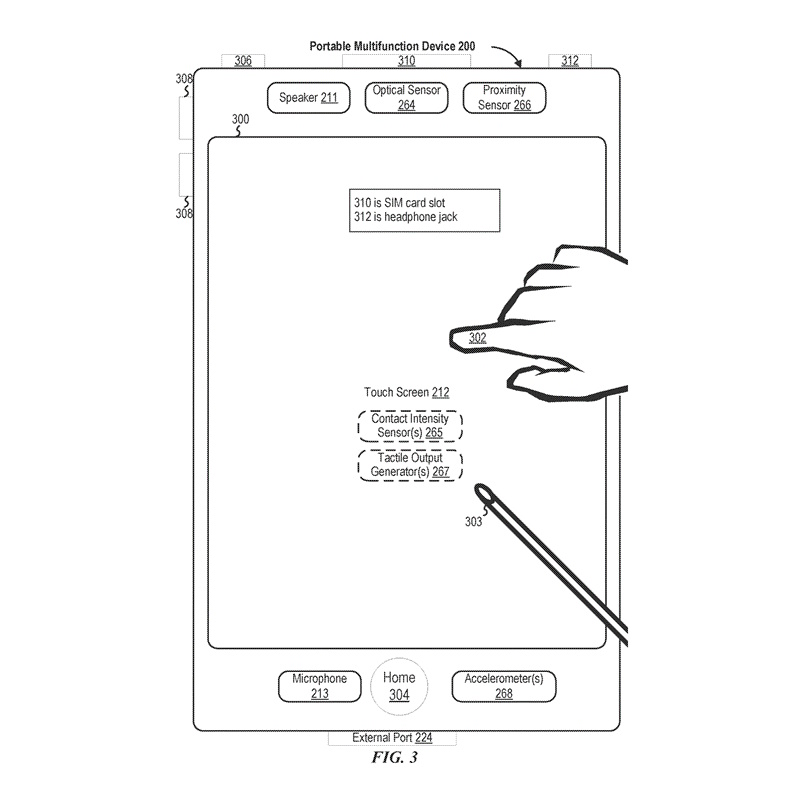
デバイス200には、「ホーム」またはメニューボタン304などの1つ以上の物理ボタンも含まれています。以前に説明したように、メニューボタン304は、デバイス200で実行されるアプリケーションのセット内の任意のアプリケーション236にナビゲートするために使用されます。または、一部の実施形態では、メニューボタンはタッチスクリーン212に表示されるGUI内のソフトキーとして実装されています。
ある実施形態では、デバイス200にはタッチスクリーン212、メニューボタン304、デバイスの電源のオン/オフおよびロックのためのプッシュボタン306、音量調整ボタン308、加入者識別モジュール(SIM)カードスロット310、ヘッドセットジャック312、およびドッキング/充電用外部ポート224が含まれています。プッシュボタン306は、オプションで、ボタンを押して所定の時間間隔保持することによりデバイスの電源をオン/オフにするため、所定の時間間隔が経過する前にボタンを押して離すことによりデバイスをロックするため、および/またはデバイスをアンロックするかアンロックプロセスを開始するために使用されます。別の実施形態では、デバイス200はマイクロフォン213を通じて一部の機能のアクティベーションまたはデアクティベーションのための口頭入力も受け入れます。デバイス200には、オプションで、タッチスクリーン212上の接触の強度を検出するための1つ以上の接触強度センサー265および/またはデバイス200のユーザーに触覚出力を生成するための1つ以上の触覚出力ジェネレーター267も含まれています。
図4は、一部の実施形態に従ったディスプレイおよびタッチ感知表面を備えた典型的な多機能デバイスのブロック図です。デバイス400は携帯型である必要はありません。一部の実施形態では、デバイス400はラップトップコンピュータ、デスクトップコンピュータ、タブレットコンピュータ、マルチメディアプレーヤーデバイス、ナビゲーションデバイス、教育デバイス(例えば子供の学習玩具)、ゲームシステム、または制御デバイス(例えば家庭用または産業用コントローラー)です。
デバイス400には通常、1つ以上の処理ユニット(CPU)410、1つ以上のネットワークまたは他の通信インターフェース460、メモリ470、およびこれらのコンポーネントを相互接続するための1つ以上の通信バス420が含まれています。通信バス420には、オプションで、システムコンポーネント間の通信を相互接続および制御する回路(チップセットと呼ばれることもあります)が含まれています。デバイス400には、通常、タッチスクリーンディスプレイであるディスプレイ440を含む入出力(I/O)インターフェース430が含まれています。I/Oインターフェース430には、オプションで、キーボードおよび/またはマウス(または他のポインティングデバイス)450およびタッチパッド455、デバイス400上で触覚出力を生成するための触覚出力ジェネレーター457(例えば、上記図2Aに関連して説明された触覚出力ジェネレーター267と同様)、センサー459(例えば、光学、加速度、近接、タッチ感知、および/または接触強度センサー、上記図2Aに関連して説明された接触強度センサー265と同様)が含まれています。メモリ470には、DRAM、SRAM、DDR RAM、または他のランダムアクセス固体状態メモリデバイスなどの高速ランダムアクセスメモリ、およびオプションで、1つ以上の磁気ディスク記憶装置、光学ディスク記憶装置、フラッシュメモリデバイス、または他の非揮発性固体状態記憶装置などの非揮発性メモリが含まれています。メモリ470には、CPU410から離れた場所にある1つ以上の記憶装置がオプションで含まれています。

図5Aは、一部の実施形態に従って携帯型多機能デバイス200上のアプリケーションメニューのための典型的なユーザーインターフェースを示しています。

図5Bは、デバイス(例えば、図4のデバイス400)上の典型的なユーザーインターフェースを示しており、このデバイスには、ディスプレイ550(例えば、タッチスクリーンディスプレイ212)とは別のタッチセンシティブな表面551(例えば、図4のタブレットまたはタッチパッド455)があります。デバイス400は、オプションで、タッチセンシティブな表面551上の接触の強度を検出するための1つ以上の接触強度センサー(例えば、センサー459の1つ以上)および/またはデバイス400のユーザーに触覚出力を生成するための1つ以上の触覚出力ジェネレーター457を含んでいます。
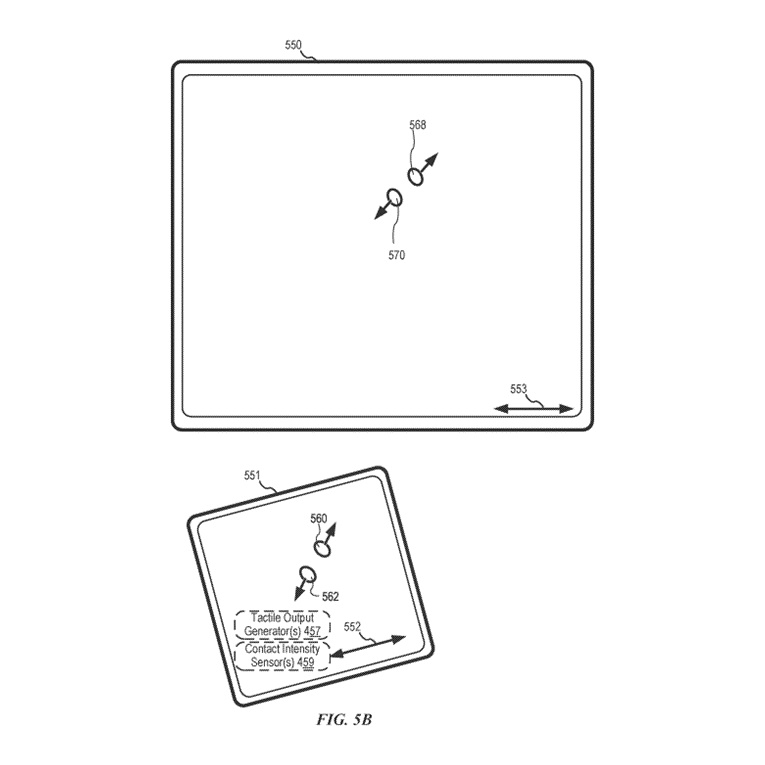
以下の例のいくつかはタッチスクリーンディスプレイ212(タッチセンシティブな表面とディスプレイが組み合わされている場所)上の入力に関連して与えられますが、一部の実施形態では、デバイスは図5Bに示されるように、ディスプレイから別のタッチセンシティブな表面上の入力を検出します。一部の実施形態では、タッチセンシティブな表面(例えば、図5Bの551)は、ディスプレイ(例えば、図5Bの550)上の主軸(例えば、図5Bの553)に対応する主軸(例えば、図5Bの552)を有します。これらの実施形態に従って、デバイスはタッチセンシティブな表面551上の接触(例えば、図5Bの560および562)を、ディスプレイ上のそれぞれの位置に対応する位置で検出します(例えば、図5Bでは、560は568に、562は570に対応します)。このようにして、デバイスはタッチセンシティブな表面(例えば、図5Bの551)上で検出されたユーザー入力(例えば、接触560および562およびそれらの動き)を使用して、タッチセンシティブな表面がディスプレイから別の場合に、多機能デバイスのディスプレイ(例えば、図5Bの550)上のユーザーインターフェースを操作します。ここで説明されている他のユーザーインターフェースに対しても、同様の方法がオプションで使用されることが理解されるべきです。
さらに、以下の例は主に指の入力(例えば、指の接触、指のタップジェスチャー、指のスワイプジェスチャー)に関連して与えられますが、一部の実施形態では、1つ以上の指の入力が別の入力デバイス(例えば、マウスベースの入力またはスタイラス入力)からの入力に置き換えられることが理解されるべきです。例えば、スワイプジェスチャーは、接触の代わりにマウスクリック(例えば、接触の動きの代わりにスワイプのパスに沿ってカーソルを動かす)に置き換えられることがあります。別の例として、タップジェスチャーは、カーソルがタップジェスチャーの位置の上にある間にマウスクリック(例えば、接触の検出に続いて接触の検出を停止する代わりに)に置き換えられることがあります。同様に、複数のユーザー入力が同時に検出される場合、複数のコンピューターマウスがオプションで同時に使用されるか、またはマウスと指の接触がオプションで同時に使用されることが理解されるべきです。
図6Aは、典型的な個人用電子デバイス600を示しています。デバイス600にはボディ602が含まれます。一部の実施形態では、デバイス600には、デバイス200および400(例えば、図2A-4)に関して説明された機能の一部または全部が含まれます。一部の実施形態では、デバイス600にはタッチセンシティブなディスプレイスクリーン604、以下タッチスクリーン604があります。タッチスクリーン604に加えて、またはタッチスクリーン604の代わりに、デバイス600にはディスプレイとタッチセンシティブな表面があります。デバイス200および400と同様に、一部の実施形態では、タッチスクリーン604(またはタッチセンシティブな表面)には、適用される接触(例えば、タッチ)の強度を検出するための1つ以上の強度センサーがあります。タッチスクリーン604(またはタッチセンシティブな表面)の1つ以上の強度センサーは、タッチの強度を表す出力データを提供します。デバイス600のユーザーインターフェースは、その強度に基づいてタッチに応答し、異なる強度のタッチがデバイス600上の異なるユーザーインターフェース操作を呼び出すことを意味します。

一部の実施形態では、デバイス600には1つ以上の入力メカニズム606および608があります。入力メカニズム606および608が含まれている場合、それらは物理的です。物理的入力メカニズムの例には、押しボタンや回転式メカニズムが含まれます。一部の実施形態では、デバイス600には1つ以上の取り付けメカニズムがあります。これらの取り付けメカニズムが含まれている場合、例えば、帽子、眼鏡、イヤリング、ネックレス、シャツ、ジャケット、ブレスレット、腕時計のストラップ、チェーン、ズボン、ベルト、靴、財布、バックパックなどにデバイス600を取り付けることができます。これらの取り付けメカニズムにより、デバイス600をユーザーが身につけることができます。
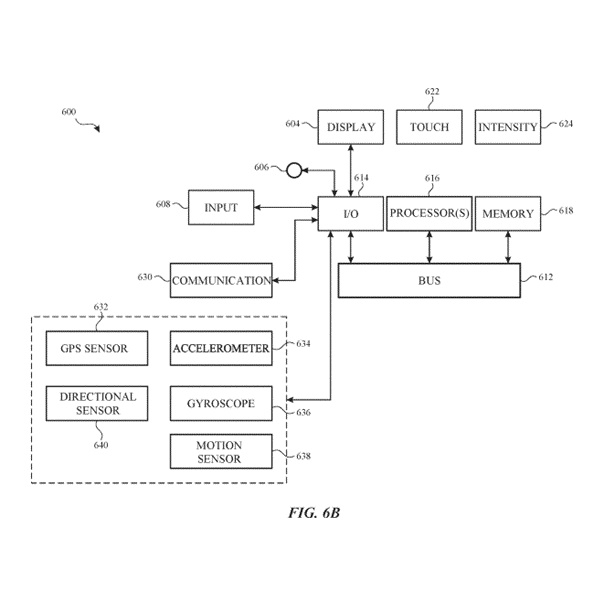
図6Bは、典型的な個人用電子デバイス600を示しています。一部の実施形態では、デバイス600には、図2A、2B、および4に関して説明されたコンポーネントの一部または全部が含まれます。デバイス600には、I/Oセクション614を1つ以上のコンピュータプロセッサ616およびメモリ618と操作的に結合するバス612があります。I/Oセクション614はディスプレイ604に接続されており、これにはタッチセンシティブコンポーネント622およびオプションでタッチ強度センシティブコンポーネント624があります。さらに、I/Oセクション614は、Wi-Fi、Bluetooth、近距離通信(NFC)、セルラー、および/またはその他の無線通信技術を使用してアプリケーションおよびオペレーティングシステムデータを受信する通信ユニット630に接続されています。デバイス600には入力メカニズム606および/または608が含まれています。入力メカニズム606は、例えば、回転式入力デバイスまたは押し込み可能かつ回転可能な入力デバイスです。入力メカニズム608は、例えば、ボタンです。
一部の実施形態では、特徴的強度を決定するためにジェスチャーの一部が識別されます。例えば、タッチセンシティブサーフェスが連続的なスワイプ接触を受け取り、開始位置から終了位置に移行し、その地点で接触の強度が増加します。この例では、終了位置での接触の特徴的強度は、連続的なスワイプ接触の一部に基づいており、スワイプ接触全体ではありません(例えば、終了位置でのスワイプ接触の部分のみ)。一部の実施形態では、接触の特徴的強度を決定する前に、スワイプ接触の強度に平滑化アルゴリズムが適用されます。例えば、平滑化アルゴリズムには、オプションで、加重なしのスライディング平均平滑化アルゴリズム、三角形平滑化アルゴリズム、中央値フィルター平滑化アルゴリズム、および/または指数平滑化アルゴリズムの一つまたは複数が含まれます。これらの平滑化アルゴリズムは、特徴的強度を決定するために、スワイプ接触の強度の狭いスパイクや窪みを排除することがあります。
一部の実施形態では、デバイスは「ジッター」と呼ばれる偶発的な入力を避けるために強度ヒステリシスを使用します。ここで、デバイスはプレス入力強度閾値に対して事前に定義された関係を持つヒステリシス強度閾値を定義または選択します(例えば、ヒステリシス強度閾値はプレス入力強度閾値よりX強度単位低い、またはヒステリシス強度閾値はプレス入力強度閾値の75%、90%、または合理的な割合です)。したがって、一部の実施形態では、プレス入力には、それぞれの接触の強度がプレス入力強度閾値を超える増加と、接触の強度がプレス入力強度閾値に対応するヒステリシス強度閾値を下回る後続の減少が含まれ、それぞれの操作は、それぞれの接触の強度がヒステリシス強度閾値を下回る後続の減少を検出することに応答して実行されます(例えば、それぞれのプレス入力の「アップストローク」)。同様に、一部の実施形態では、プレス入力は、デバイスが接触の強度がヒステリシス強度閾値以下からプレス入力強度閾値以上に増加することを検出し、オプションで、接触の強度がヒステリシス強度に至るかそれ以下に減少することを検出した場合にのみ検出され、それぞれの操作はプレス入力(例えば、接触の強度の増加または減少、状況に応じて)を検出することに応答して実行されます。
<デジタルアシスタントシステム>
図7Aは、さまざまな例に従ったデジタルアシスタントシステム700のブロック図を示しています。
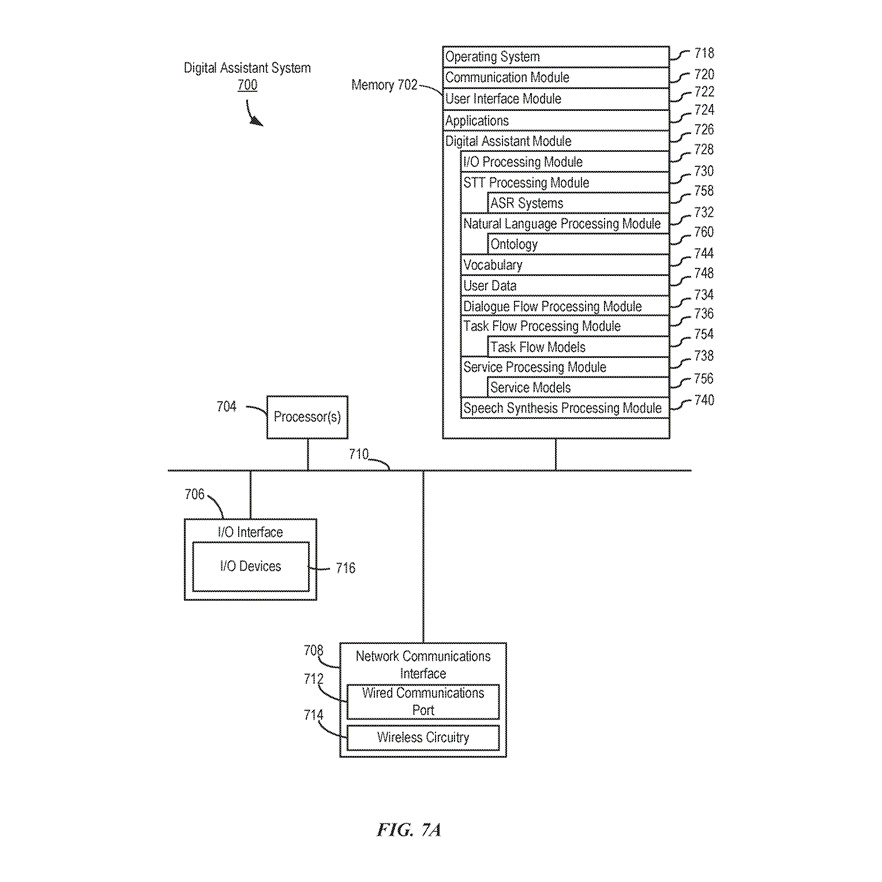
一部の例では、デジタルアシスタントシステム700はスタンドアロンのコンピュータシステム上に実装されます。一部の例では、デジタルアシスタントシステム700は複数のコンピュータにまたがって分散されています。一部の例では、デジタルアシスタントのモジュールと機能の一部がサーバー部分とクライアント部分に分割され、クライアント部分は1つ以上のユーザーデバイス(例えば、デバイス104、122、200、400、または600)上に存在し、1つ以上のネットワークを介してサーバー部分(例えば、サーバーシステム108)と通信します。例えば、図1に示されています。一部の例では、デジタルアシスタントシステム700は図1に示されたサーバーシステム108(および/またはDAサーバー106)の実装です。デジタルアシスタントシステム700はデジタルアシスタントシステムの一例に過ぎず、図に示されているよりも多くまたは少なくのコンポーネントを持つことができ、2つ以上のコンポーネントを組み合わせることができ、またはコンポーネントの異なる構成または配置を持つことができることに注意してください。図7Aに示されたさまざまなコンポーネントは、ハードウェア、1つ以上のプロセッサによる実行のためのソフトウェア命令、ファームウェア(1つ以上の信号処理および/またはアプリケーション固有の統合回路を含む)、またはそれらの組み合わせで実装されています。
一部の例では、図7Bに示されているように、入出力処理モジュール728は、図7AのI/Oデバイス716を介してユーザーと対話するか、または図7Aのネットワーク通信インターフェース708を介してユーザーデバイス(例えば、デバイス104、200、400、600)と対話して、ユーザー入力(例えば、音声入力)を取得し、ユーザー入力に対する応答(例えば、音声出力として)を提供します。入出力処理モジュール728は、オプションで、ユーザー入力の受領と同時に、またはそれに続いて、ユーザーデバイスからユーザー入力に関連する文脈情報を取得します。この文脈情報には、ユーザー入力に関連するユーザー固有のデータ、語彙、および/または好みが含まれます。
一部の例では、文脈情報には、ユーザー要求が受信された時点でのユーザーデバイスのソフトウェアおよびハードウェアの状態、および/またはユーザー要求が受信された時点でのユーザーの周囲の環境に関連する情報も含まれます。一部の例では、入出力処理モジュール728は、ユーザー要求に関してユーザーにフォローアップの質問を送信し、ユーザーから回答を受け取ります。ユーザー要求が入出力処理モジュール728によって受信され、ユーザー要求に音声入力が含まれている場合、入出力処理モジュール728は音声入力をSTT処理モジュール730(または音声認識器)に転送して、音声からテキストへの変換を行います。

STT処理モジュール730には、1つ以上のASRシステム758が含まれています。1つ以上のASRシステム758は、入出力処理モジュール728を介して受信された音声入力を処理して、認識結果を生成することができます。各ASRシステム758には、フロントエンドの音声プリプロセッサが含まれています。フロントエンドの音声プリプロセッサは、音声入力から代表的な特徴を抽出します。例えば、フロントエンドの音声プリプロセッサは、音声入力にフーリエ変換を行い、音声入力を代表的な多次元ベクトルのシーケンスとして特徴付けるスペクトル特徴を抽出します。
さらに、各ASRシステム758には、1つ以上の音声認識モデル(例えば、音響モデルおよび/または言語モデル)が含まれており、1つ以上の音声認識エンジンを実装しています。音声認識モデルの例には、隠れマルコフモデル、ガウス混合モデル、ディープニューラルネットワークモデル、n-gram言語モデル、およびその他の統計モデルがあります。音声認識エンジンの例には、動的時間伸縮に基づくエンジンおよび加重有限状態トランスデューサ(WFST)に基づくエンジンがあります。
1つ以上の音声認識モデルおよび1つ以上の音声認識エンジンは、フロントエンドの音声プリプロセッサの抽出された代表的な特徴を処理して、中間認識結果(例えば、音素、音素文字列、およびサブワード)を生成し、最終的にはテキスト認識結果(例えば、単語、単語文字列、またはトークンのシーケンス)を生成するために使用されます。一部の例では、音声入力は、少なくとも部分的に第三者のサービスまたはユーザーのデバイス(例えば、デバイス104、200、400、600)で処理されて、認識結果を生成します。STT処理モジュール730がテキスト文字列(例えば、単語、または単語のシーケンス、またはトークンのシーケンス)を含む認識結果を生成すると、認識結果は意図推論のために自然言語処理モジュール732に渡されます。一部の例では、STT処理モジュール730は、音声入力の複数の候補テキスト表現を生成します。各候補テキスト表現は、音声入力に対応する単語またはトークンのシーケンスです。
一部の例では、各候補テキスト表現は、音声認識信頼スコアに関連付けられています。音声認識信頼スコアに基づいて、STT処理モジュール730は候補テキスト表現をランク付けし、n番目に高いランク(例えば、nがゼロより大きい所定の整数)の候補テキスト表現を意図推論のために自然言語処理モジュール732に提供します。例えば、ある例では、最も高いランク(n=1)の候補テキスト表現のみが意図推論のために自然言語処理モジュール732に渡されます。別の例では、5番目に高いランク(n=5)の候補テキスト表現が意図推論のために自然言語処理モジュール732に渡されます。
一部の例では、STT処理モジュール730から得られた単語またはトークンのシーケンスに加えて、自然言語処理モジュール732は、例えばI/O処理モジュール728から、ユーザーリクエストに関連する文脈情報も受け取ります。自然言語処理モジュール732は、オプションで、STT処理モジュール730から受け取った候補テキスト表現に含まれる情報を明確にし、補完し、またはさらに定義するために文脈情報を使用します。文脈情報には、例えば、ユーザーの好み、ユーザーデバイスのハードウェアおよび/またはソフトウェアの状態、ユーザーリクエストの前、中、または直後に収集されたセンサー情報、デジタルアシスタントとユーザー間の以前の相互作用(例えば、対話)などが含まれます。ここで説明されているように、文脈情報は、一部の例では動的であり、時間、場所、対話の内容、その他の要因によって変化します。
一部の例では、自然言語処理は、例えば、オントロジー760に基づいています。オントロジー760は、多くのノードを含む階層構造で、各ノードは「実行可能な意図」または「実行可能な意図」または他の「プロパティ」に関連する「プロパティ」のいずれかを表しています。上述のように、「実行可能な意図」は、デジタルアシスタントが実行可能なタスクを表し、つまり「実行可能」であるか、行動に移すことができます。「プロパティ」は、実行可能な意図に関連するパラメーターまたは別のプロパティのサブアスペクトを表します。オントロジー760内の実行可能な意図ノードとプロパティノード間のリンクは、プロパティノードによって表されるパラメーターが実行可能な意図ノードによって表されるタスクにどのように関連するかを定義します。
一部の例では、オントロジー760は実行可能な意図ノードとプロパティノードで構成されています。オントロジー760内では、各実行可能な意図ノードは、直接または1つ以上の中間プロパティノードを介して1つ以上のプロパティノードにリンクされています。同様に、各プロパティノードは、直接または1つ以上の中間プロパティノードを介して1つ以上の実行可能な意図ノードにリンクされています。例えば、図7Cに示されているように、オントロジー760には「レストラン予約」ノード(つまり、実行可能な意図ノード)が含まれています。プロパティノード「レストラン」、「日時」(予約用)、および「パーティーサイズ」は、それぞれ実行可能な意図ノード(つまり、「レストラン予約」ノード)に直接リンクされています。
さらに、プロパティノード「料理」、「価格帯」、「電話番号」、および「場所」は、プロパティノード「レストラン」のサブノードであり、中間プロパティノード「レストラン」を介して「レストラン予約」ノード(つまり、実行可能な意図ノード)にそれぞれリンクされています。別の例として、図7Cに示されているように、オントロジー760には「リマインダー設定」ノード(つまり、別の実行可能な意図ノード)も含まれています。プロパティノード「日時」(リマインダー設定用)および「主題」(リマインダー用)は、それぞれ「リマインダー設定」ノードにリンクされています。プロパティ「日時」は、レストラン予約のタスクとリマインダー設定のタスクの両方に関連しているため、プロパティノード「日時」は、オントロジー760内の「レストラン予約」ノードと「リマインダー設定」ノードの両方にリンクされています。
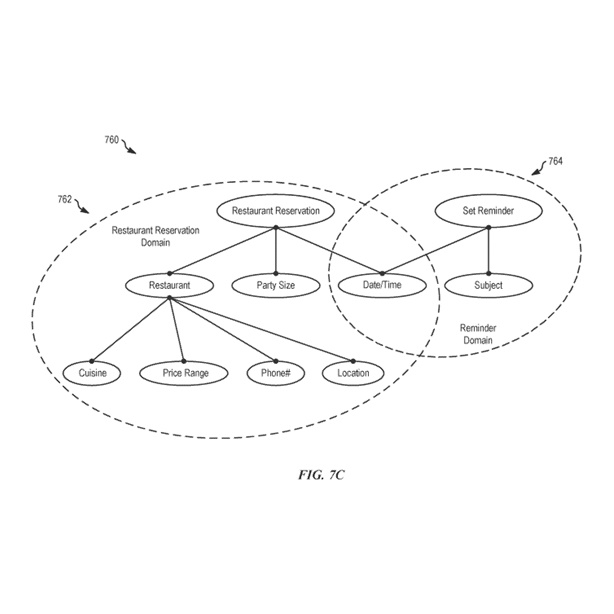
図7Cではオントロジー760内の2つの例示的なドメインを示していますが、他のドメインには例えば、「映画を探す」、「電話をかける」、「道順を探す」、「会議をスケジュールする」、「メッセージを送る」、「質問に答える」、「リストを読む」、「ナビゲーション指示を提供する」、「タスクの指示を提供する」などが含まれます。「メッセージを送る」ドメインは、「メッセージを送る」実行可能な意図ノードに関連付けられており、さらに「受信者」、「メッセージタイプ」、「メッセージ本文」などのプロパティノードを含みます。プロパティノード「受信者」は、例えば「受信者名」や「メッセージアドレス」などのサブプロパティノードによってさらに定義されます。
一部の例では、オントロジー760内の各ノードは、ノードによって表されるプロパティまたは実行可能な意図に関連する単語やフレーズのセットに関連付けられています。各ノードに関連付けられた単語やフレーズのそれぞれのセットは、ノードに関連付けられたいわゆる「語彙」です。各ノードに関連付けられた単語やフレーズのそれぞれのセットは、ノードによって表されるプロパティまたは実行可能な意図と関連付けて語彙インデックス744に格納されています。例えば、図7Bに戻ると、「レストラン」のプロパティのノードに関連付けられた語彙には、「食べ物」、「飲み物」、「料理」、「空腹」、「食べる」、「ピザ」、「ファストフード」、「食事」などの単語が含まれています。別の例として、「電話をかける」実行可能な意図のノードに関連付けられた語彙には、「電話をかける」、「電話」、「ダイヤル」、「リング」、「この番号に電話をかける」、「〜に電話をかける」などの単語やフレーズが含まれています。語彙インデックス744には、異なる言語の単語やフレーズが含まれることもあります。
実行可能な意図ノードとそれにリンクされたプロパティノードは、「ドメイン」として説明されます。現在の議論では、各ドメインはそれぞれの実行可能な意図に関連付けられており、特定の実行可能な意図に関連するノードのグループ(およびそれらの間の関係)を指します。例えば、図7Cに示されているオントロジー760には、レストラン予約ドメイン762の例とリマインダードメイン764の例が含まれています。レストラン予約ドメインには、実行可能な意図ノード「レストラン予約」、プロパティノード「レストラン」、「日時」、「パーティーサイズ」、およびサブプロパティノード「料理」、「価格帯」、「電話番号」、「場所」が含まれています。リマインダードメイン764には、実行可能な意図ノード「リマインダー設定」、およびプロパティノード「主題」と「日時」が含まれています。一部の例では、オントロジー760は多くのドメインで構成されています。各ドメインは、1つ以上の他のドメインと1つ以上のプロパティノードを共有します。例えば、「日時」プロパティノードは、レストラン予約ドメイン762およびリマインダードメイン764に加えて、多くの異なるドメイン(例えば、スケジューリングドメイン、旅行予約ドメイン、映画チケットドメインなど)に関連付けられています。
自然言語処理モジュール732は、STT処理モジュール730から候補テキスト表現(例えば、テキスト文字列やトークンシーケンス)を受け取り、各候補表現について、候補テキスト表現内の単語がどのノードに関連しているかを決定します。一部の例では、候補テキスト表現内の単語やフレーズがオントロジー760内の1つ以上のノード(語彙インデックス744を介して)と関連付けられていると判断されると、その単語やフレーズはそれらのノードを「トリガー」または「アクティベート」します。アクティベートされたノードの量や相対的な重要性に基づいて、自然言語処理モジュール732は、デジタルアシスタントに実行させることをユーザーが意図したタスクとして、実行可能な意図の1つを選択します。一部の例では、最も「トリガー」されたノードを持つドメインが選択されます。一部の例では、最も高い信頼度値を持つドメイン(例えば、その様々なトリガーされたノードの相対的な重要性に基づいて)が選択されます。一部の例では、トリガーされたノードの数と重要性の組み合わせに基づいてドメインが選択されます。一部の例では、デジタルアシスタントが以前に同様のユーザーリクエストを正しく解釈したかどうかなど、ノードを選択する際に追加の要因も考慮されます。
ユーザーデータ748には、ユーザー固有の語彙、ユーザーの好み、ユーザーの住所、ユーザーのデフォルトおよび第二言語、ユーザーの連絡先リストなど、各ユーザーに関する短期または長期の情報が含まれています。一部の例では、自然言語処理モジュール732は、ユーザー固有の情報を使用して、ユーザー入力に含まれる情報を補完し、ユーザーの意図をさらに定義します。例えば、「私の誕生日パーティーに友達を招待する」というユーザーリクエストに対して、自然言語処理モジュール732はユーザーデータ748にアクセスして、「友達」が誰で、「誕生日パーティー」がいつどこで開催されるかを決定することができ、ユーザーがそのような情報をリクエストに明示的に提供する必要がありません。
一部の例では、自然言語処理モジュール732、対話フロー処理モジュール734、およびタスクフロー処理モジュール736は、ユーザーの意図を推測し定義し、ユーザーの意図をさらに明確にし洗練するための情報を取得し、最終的にユーザーの意図を満たすための応答(つまり、ユーザーへの出力またはタスクの完了)を生成するために、集合的かつ反復的に使用されます。生成された応答は、ユーザーの意図を少なくとも部分的に満たす音声入力への対話応答です。さらに、一部の例では、生成された応答は音声出力として出力されます。これらの例では、生成された応答は音声合成処理モジュール740(例えば、音声合成装置)に送信され、そこで対話応答を音声形式で合成するために処理されます。他の例では、生成された応答は、音声入力のユーザーリクエストを満たすための関連するデータコンテンツです。
<モーションセンシングを使用して音声入力を認識するシステム>
図8Aは、様々な例において、モーションセンシングを使用して音声入力を認識するシステム800を示しています。システム800は、例えば、デジタルアシスタント(例えば、デジタルアシスタントシステム700)を実装する1つ以上の電子デバイスを使用して実装されます。
一部の例では、システム800はクライアントサーバーシステム(例えば、システム100)を使用して実装され、システム800の機能はサーバー(例えば、DAサーバー106)とクライアントデバイスの間で任意の方法で分割されます。他の例では、システム800の機能はサーバーと複数のクライアントデバイス(例えば、携帯電話とウェアラブルコンピューティングデバイス)の間で分割されます。したがって、システム800の一部の機能がクライアントサーバーシステムの特定のデバイスによって実行されると説明されていますが、システム800がこれに限定されるわけではありません。他の例では、システム800はクライアントデバイスのみ(例えば、ユーザーデバイス104)または複数のクライアントデバイスのみを使用して実装されます。システム800では、一部の機能はオプションで組み合わされ、一部の機能の順序はオプションで変更され、一部の機能はオプションで省略されます。一部の例では、システム800と組み合わせて追加の機能が実行される場合があります。
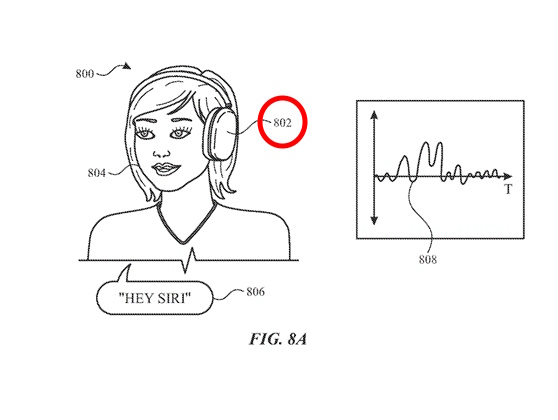
図8Aにおいて、デバイス802にはモーションセンサーが含まれています。図8Aに示されているように、デバイス802はユーザー804のこめかみ付近にモーションセンサーを備えたウェアラブル電子デバイスであり、ユーザー804の顔、頭、首からの振動や動きを検出することができます。デバイス802は、ヘッドセット、ヘッドホン/イヤホン(例えば、AirPodsやAirPods Max)、スマートグラスなどのウェアラブル電子デバイスに組み込まれることがあります。モーションセンサーには、1つ以上の加速度計、1つ以上のジャイロスコープ、1つ以上の磁力計、またはそれらの組み合わせ(例えば、慣性測定ユニット(IMU))が含まれることがあります。一部の実施形態では、デバイス802にはさらにオーディオセンサー(例えば、マイクロフォン)が含まれることがあります。
デバイス802に含まれるモーションセンサーは、ユーザー804の動きを検出し、モーションデータのストリームを生成します。例えば、モーションセンサーは筋肉の動き、振動、頭の動きなどを検出し、これらの動きによって生じる特定の力、角速度、および/または方向を表すデータストリームを出力することがあります。モーションセンサーは、音声入力を捉えるために適切なサンプリングレートでモーションデータをサンプリング(例えば、収集)することがあります。例えば、音声入力によって引き起こされる動きの信号は、周波数内容が100Hzから350Hzの範囲にある傾向があるため、700Hz以上(例えば、ナイキスト周波数以上)のサンプリングレートでモーションデータをサンプリングすると、歪みのないデータが生成される傾向があります。
デバイス802を音声制御に使用する前に、ユーザー804はシステム800のために個人化された音声プロファイルを設定することがあります(図9に関してさらに説明されています)。例えば、システム800は、ユーザー804にいくつかのフレーズを話すように促して、音声プロファイルをカスタマイズするために使用されるトレーニングデータを収集することがあります。
ユーザー804が音声入力806を話すとき(例えば、デジタルアシスタント(DA)を起動するためのトリガーフレーズ「Hey Siri」)、話す行為によって振動や動きが発生し、デバイス802のモーションセンサーによって検出されます。検出された動きの結果として、モーションセンサーは音声入力806に対応するデータ部分808(例えば、モーションデータのストリームの一部)を生成します。
図8Bを参照して、データ部分808を含むモーションデータのストリームは、1つ以上の単語(例えば、単語やフレーズ)の少なくとも1セットの参照データと比較され、モーションデータのストリームの任意の部分が特定の1つ以上の単語のセットの参照データと一致するかどうかを判断します。ユーザー804が個人の音声プロファイルを設定した実施形態では、比較に使用される参照データはユーザー804のカスタム参照データであることがあります。
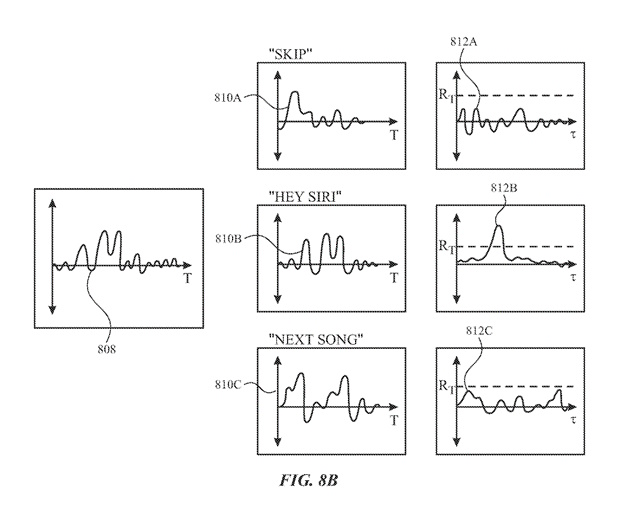
図示されているのは3セットの単語の参照データのみですが、一部の実施形態では、モーションデータのストリームは、システム800に利用可能なすべての参照データ(例えば、システム800の音声モデルに含まれる参照データ)と比較されることがあります。例えば、システム800が多くの単語やフレーズの参照データを持っている場合でも、システム800は文脈データ(例えば、時間、曜日、場所、使用履歴など)を使用して、最も可能性の高い単語やフレーズのサブセットに語彙を絞り込み、データ部分808は文脈に制限された語彙とのみ比較されることがあります。他の例としてのコマンド単語やフレーズには、「Start Timer」、「Stop Timer」、「What's the weather」、「Read messages」、「Lower volume」、「Raise volume」、「Stock prices」、「What time is it」などがあります。文脈依存のコマンド単語やフレーズの例には、「Stop」や「Snooze」(例えば、時計のアラームが鳴っている間やメッセージが再生されている間など)があります。
図8Bに示されているように、データ部分808と参照データ810A(「Skip」)との間のクロス相関は相関データ812Aを生成し、データ部分808と参照データ810B(「Hey Siri」)との相関はクロス相関データ812Bを生成し、データ部分808と参照データ810C(「Next Song」)とのクロス相関は相関データ812Cを生成します。相関データ812Bがしきい値振幅値RTを超えるため、システム800はデータ部分808が「Hey Siri」の単語セットの参照データと一致していると判断します。したがって、システム800は、モーションセンサー(例えば、データ部分808)から受信したモーションデータのストリームに基づいてのみ、ユーザー804が「Hey Siri」と発声したことを判断できます(例えば、ユーザー804が話している間にデバイス802に含まれるマイクロフォンやオーディオセンサーが非アクティブ状態であっても)。
データ部分808と特定の単語セットの参照データとの一致が判定されると、一致した単語セットに関連するタスクが開始されます。例えば、「Hey Siri」という単語セットはデジタルアシスタントセッションを開始するトリガーなので、システム800は一致を判定したことに応じてデジタルアシスタントセッションを開始させることができます。上述のように、音声入力806に対するタスクの応答は、音声入力806がモーションデータ(データ部分808)だけから理解されるため、オーディオデータを受信または処理する必要なく開始することができます。
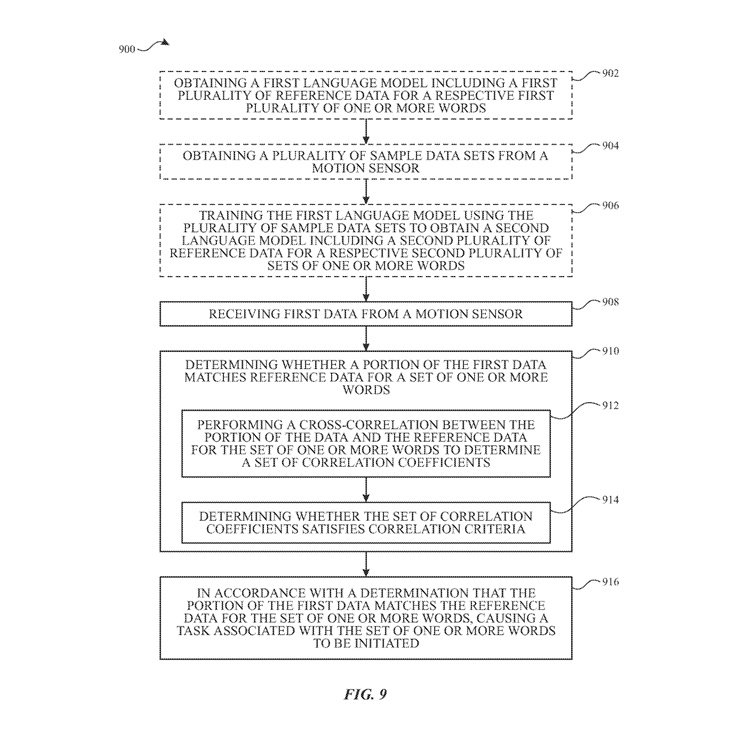
図9は、一部の実施形態においてモーションセンシングを使用して音声入力を認識する方法900を示すフローチャートです。ブロック902で、それぞれの第一の複数の単語セット(例えば、単語やフレーズの第一の語彙)のための参照モーションデータの第一の複数を含む第一の言語モデルが取得されます。例えば、コマンド語彙に含まれる単語やフレーズのセットには、「Hey Siri」、「Next Song」、「Skip」、「Stop」、「Snooze」、「Start Timer」、「Stop Timer」、「What's the weather」、「Read messages」、「Lower volume」、「Raise volume」、「Stock prices」、「What time is it」などが含まれることがあります。
一部の実施形態では、第一の言語モデルは非常に大きなモーションデータセットでトレーニングされ、基本語彙のための基本モデルを開発するために使用され、工場インストール、システムアップデート、ダウンロード、またはその他の適切な方法を通じて、方法900を実装するデバイスによって取得されることがあります。したがって、方法900は、ユーザー固有のデータやさらなるトレーニングなしに、基本語彙に含まれる音声入力を認識することができます。
一部の実施形態では、ブロック904で、モーションセンサー(例えば、デバイス802に組み込まれたモーションセンサー)から、ユーザー固有のモーションデータコーパスを表す複数のサンプルデータセットが取得されます。例えば、ユーザーはモーションセンシングを使用して音声入力を認識するための登録プロセスを完了し、その際にユーザーはサンプル音声入力を話すように促され、モーションセンサーはユーザーの動きを検出します。サンプル音声入力には、一般的に使用されるコマンド(例えば、「Hey Siri」、「Turn on/off」、「Play」など)、カスタム語彙(例えば、ユーザーの名前、ユーザーの連絡先の名前、デバイスのニックネームなど、基本言語モデルに含まれていない可能性のある語彙)、または言語モデルのトレーニングに役立つ音声入力のセット(例えば、多様な音素を含む音声入力)が含まれることがあります。ユーザーは、ユーザーの動きの変動を捉えるために、単一の音声入力を複数回話すように促されることがあります。
一部の実施形態では、モーションセンサーは、音声入力によって引き起こされる動きを正確に捉えるために選択された初期サンプリングレートを使用して、複数のサンプルデータセットを収集することがあります。例えば、人間の音声によって引き起こされる動きからの信号は、周波数コンテンツが100Hzから350Hzの範囲にある傾向があるため、700Hz以上の初期サンプリングレート(例えば、ナイキスト周波数以上)を使用すると、歪みのないデータが生成される傾向があります。
一部の実施形態では、複数のサンプルデータセットはバンドパスフィルター(例えば、100Hzから350Hzのバンドパスフィルター)を使用してフィルタリングされ、非音声周波数を減衰させることによって信号のノイズを減らします。例えば、ユーザーが歩いたり、デバイス802に触れたりすることによって引き起こされる動きは、100Hzから350Hzのバンドの外側の周波数で主に構成されるため、トレーニングや比較に使用されるモーション信号からフィルタリングすることができます。
一部の実施形態では、ブロック906で、第一の言語モデルが複数のサンプルデータセットを使用してトレーニングされ、それぞれの第二の複数の単語セットのための第二の複数の参照データを含む第二の言語モデルを取得するために使用されます。つまり、基本言語モデルは、ユーザー固有のデータを使用して再トレーニングされ、特定のユーザーの音声モーションパターンのニュアンスを捉えるユーザー固有の言語モデルを生成することができます。
第二の複数の単語セット(例えば、ユーザー固有の言語モデル語彙)には、第一の複数の単語セット(例えば、基本言語モデル語彙)に含まれていない少なくとも1つの単語セットが含まれることがあります。例えば、登録プロセスを完了する際に、ユーザーはよく使用する連絡先の名前やカスタム音声ショートカットなど、カスタム単語やフレーズのサンプル音声入力を提供することがあり、第二の言語モデルはそれらを認識するためにトレーニングされることがあります。
ブロック908では、モーションセンサーからの第一のデータが受信されます。モーションセンサーには、1つ以上の加速度計、1つ以上のジャイロスコープ、1つ以上の磁力計、またはそれらの組み合わせ(例えば、慣性測定ユニット(IMU))が含まれることがあります。モーションセンサーは、特に、ユーザーが話すことによって引き起こされる動き、例えば顔の筋肉の動き、振動、頭のうなずきや揺れなどを表すデータを生成するために使用されます。
したがって、一部の実施形態では、モーションセンサーは、ヘッドフォン/イヤフォン、ヘッドセット、スマートグラスなどのウェアラブル電子デバイスに組み込まれる(例えば、収容される)ことがあります。モーションセンサーは、ユーザーが話すことによって引き起こされるモーションデータを捉えることができる場所、例えばユーザーの額、こめかみ、耳などに位置することがあります。
一部の実施形態では、モーションセンサーから受信される第一のデータには、1つ以上のデータストリームが含まれることがあります。つまり、モーションセンサーは、ユーザーが積極的に話しているかどうかに関わらず、継続的にモーションデータを収集することがあります。例えば、方法900を実装するシステムは、モーションセンサーを「常時オン」状態に設定し、システムが稼働している限りモーションデータを収集することがあります。別の例として、システムは、オーディオセンサーが積極的に使用されていない場合(例えば、電話をかけるためやテキストを書くため)、システムの充電レベルが特定のレベル以下になった場合(例えば、バッテリー残量が20%以下の場合)、またはシステムが低電力状態に設定された場合(例えば、「バッテリーセーバー」モード)など、モーションデータの収集をデフォルトにすることがあります。
ブロック904-906に記載されたように、モーションセンサーは、音声入力によって引き起こされる動きを捉えるために適切なサンプリングレートで第一のデータをサンプリングすることがあります。
ブロック910では、第一のデータの一部(例えば、データ部分808)が1つ以上の単語のセットの参照データと一致するかどうかを判断します。つまり、方法900は、モーションセンサーから受信したモーションデータが、特定の単語またはフレーズ(例えば、「Hey Siri」)の参照モーションデータに基づいて、ユーザーが特定の単語またはフレーズを話したことを示しているかどうかを判断します(例えば、参照データ810B)。例えば、図8Bに示されているように、「Hey Siri」という音声入力は、デバイス802のモーションセンサーからのデータ部分808が「Hey Siri」という単語のセットの参照データ810Bと一致することを判断することによって認識されます。
一部の実施形態では、第一のデータの部分が1つ以上の単語のセットの参照データと一致するかどうかを判断することには、ブロック912で、データの部分と1つ以上の単語のセットの参照データとの間でクロス相関を行い、相関係数のセットを決定することが含まれます。例えば、モーションセンサーから受信した第一のデータ(例えば、モーションデータストリーム)と特定の参照データとの間でスライディングウィンドウ相関が行われ、各変位(例えば、時間遅延)τに対して相関係数R(τ)が生成されます。特定の参照データとデータストリームの部分(例えば、「ウィンドウ」)との間の類似性が高いほど、相関係数R(τ)の振幅は大きくなります。クロス相関は変位τ(例えば、比較される信号を異なる点で整列させることによって)で決定されるため、システムは比較前に信号を同期または整列させる必要はありません(例えば、システムは関連するデータ部分がいつ始まるか終わるかを「知る」必要はありません)。
一部の実施形態では、モーションデータのストリームを参照データと比較することには、信号にフーリエ変換を行い、周波数領域での分析を行うことが含まれます。例えば、図8Bに関して、データ部分808のフーリエ変換と参照データ810Aのフーリエ変換の畳み込みは、データ部分808と参照データ810Aの時間領域でのクロス相関と同等の信号間の比較を生成します。
一部の実施形態では、ブロック914で、相関係数のセットが相関基準を満たすかどうかを判断します。例えば、相関基準には閾値相関振幅RTが含まれ、相関係数のセットは、第一のデータの部分と参照データ(例えば、図8Bの相関データ812Bで示されているように)の間の少なくとも1つの変位τでR(τ)の振幅がRTを超える場合、相関基準を満たすことがあります。相関係数のセットが相関基準を満たすと判断された場合、システムは、第一のデータの部分が1つ以上の単語のセットの参照データと一致すると判断します。
一部の実施形態では、ブロック910は、追加の1つ以上の単語のセットの参照データ(例えば、複数の参照データ構造からの追加の参照データ構造を使用して)を使用して実行することもできます。つまり、第一のデータの部分は、システム語彙に含まれるいくつかまたはすべての単語やフレーズの参照データと比較されることがあります(例えば、図8Bで示されているように)。複数の比較は、並行しておよび/または順次実行され、最適な一致を決定することができます(例えば、データ部分808がフレーズ「Hey Siri」の参照データ810Bと最もよく一致すると判断する)。
一部の実施形態では、第一のデータの部分が1つ以上の単語のセットの参照データ(またはシステム語彙内の他の単語やフレーズの参照データ)と一致しないと判断された場合、システムはブロック908-910のいずれかまたは両方を繰り返すことができます。例えば、第一のデータの追加の部分、またはモーションセンサーから受信した追加のデータ(例えば、モーションデータストリーム)が参照データと比較され、正の一致が決定されるまで(例えば、特定の音声入力が認識されるまで)続けられることがあります。
ブロック916では、第一のデータの部分が1つ以上の単語のセットの参照データと一致すると判断された場合、その1つ以上の単語のセット(例えば、認識された単語やフレーズ)に関連するタスクが開始されます。例えば、タスクにはデジタルアシスタントセッションの起動(例えば、「Hey Siri」というフレーズを認識した場合、図8A-8Bに示されているように)、メディアの再生制御(例えば、映画の再生、テレビ番組のエピソードのスキップ、プレイリストの次の曲への進行など)、電話をかけることやメッセージを送ること、または電子デバイスで実行できる他のタスク(例えば、従来の音声制御方法を使用して)が含まれる場合があります。
上記のように、本技術の一側面は、動作センシングを使用して音声入力の認識を改善するために、さまざまなソースから利用可能なデータを収集し使用することです。本開示は、収集されたデータが個人情報データを含む場合があることを想定しています。このような個人情報データには、人口統計データ、位置情報データ、電話番号、メールアドレス、Twitter ID、自宅住所、ユーザーの健康状態やフィットネスレベルに関連するデータや記録(例えば、バイタルサインの測定、薬の情報、運動情報)、生年月日、その他の識別情報や個人情報が含まれることがあります。
本開示は、本技術におけるこのような個人情報データの使用が、ユーザーに利益をもたらすことを認識しています。例えば、個人情報データは、特定のユーザーのために参照データや語彙(例えば、本開示によって認識可能な一つ以上の単語のセット)をカスタマイズするために使用される可能性があります。したがって、このような個人情報データの使用により、特定のユーザーに対してより効率的で正確な音声制御が可能になります。さらに、本開示は、ユーザーに利益をもたらす個人情報データの他の使用も想定しています。例えば、健康やフィットネスのデータは、ユーザーの一般的なウェルネスに関する洞察を提供するために使用されたり、ウェルネス目標を追求するために技術を使用する個人に対して肯定的なフィードバックとして使用されたりすることがあります。
もちろん、本開示は、ユーザーが個人情報データの使用またはアクセスを選択的にブロックする実施形態も想定しています。つまり、本開示は、このような個人情報データへのアクセスを防止またはブロックするためのハードウェアおよび/またはソフトウェア要素を提供することを想定しています。例えば、動作センシングを使用した音声入力の認識の場合、本技術は、サービスへの登録時またはその後のいつでも、個人情報データの収集への「オプトイン」または「オプトアウト」を選択することをユーザーに許可するように設定することができます。別の例として、ユーザーは、動作センシングを使用した音声入力の認識のために気分関連データを提供しないことを選択することができます。さらに別の例では、ユーザーは、気分関連データの保持期間を制限するか、基本的な気分プロファイルの開発を完全に禁止することを選択することができます。また、「オプトイン」と「オプトアウト」のオプションを提供するだけでなく、本開示は、個人情報のアクセスや使用に関する通知を提供することも想定しています。
ここがポイント!
この「モーションセンシングを用いたキーワード検出」の発明は、音声入力の認識を改善するために、モーションセンサーからのデータを活用する技術です。従来の音声認識システムは、周囲の騒音や音声の変動に影響されやすく、特に騒がしい環境や音声が不明瞭な場合には、正確な認識が困難でした。この新しいアプローチでは、加速度計やジャイロスコープなどのモーションセンサーを使用して、ユーザーの顔や頭部の微細な動きを捉えます。これらの動きは、ユーザーが話す際に生じる特有のパターンを持っており、特定のキーワードやフレーズの検出に利用されます。
例えば、ユーザーが「Hey Siri」と発声した際の顔の筋肉や頭部の動きは、特定のパターンを示します。この発明では、これらの動きのデータを収集し、分析することで、音声コマンドを正確に認識し、適切なタスクを実行することができます。このプロセスは、音声データだけに頼る従来の方法と比較して、周囲の騒音や音声の変動の影響を受けにくいという大きな利点があります。
さらに、このシステムは、ユーザー固有の動きのパターンを学習し、カスタマイズすることが可能です。これにより、個々のユーザーに最適化された音声認識が実現され、より高い精度と利便性を提供します。特に、ユーザーが多様な環境や状況でデバイスを使用する現代において、この技術は音声認識の新たな可能性を提供するものといえます。
未来予想
本発明のような「モーションセンシングを用いたキーワード検出」技術を応用することにより、多くの展開が考えられます。
1.より高度なウェアラブルデバイス
本発明を、スマートウォッチ、フィットネストラッカー、スマートグラスなどのウェアラブルデバイスに統合することを考えれば、ユーザーの動きやジェスチャーを利用してより直感的なインタラクションが実現できるでしょう。たとえば、頷くだけで通話を受ける、首を振って通知を拒否するなどの機能が可能になると考えられます。
2.改善されたスマートホーム制御
家庭内のスマートデバイスや家電製品が、ユーザーの身体の動きやジェスチャーを認識して操作できるようになるでしょう。これにより、音声コマンドだけでなく、より自然な身体の動きで家電を制御できるようになります。
3.アクセシビリティの向上
言語障害や聴覚障害を持つユーザーにとって、この技術は新たなコミュニケーション手段が提供されるでしょう。身体の動きやジェスチャーを利用してデバイスを操作できるため、これまで音声コマンドに頼っていた機能がよりアクセスしやすくなるでしょう。
4.よりパーソナライズされたユーザーエクスペリエンス
この発明により、ユーザーの特定の動きや習慣を学習し、それに基づいてカスタマイズされた体験を提供することができます。例えば、ユーザーの特定のジェスチャーに基づいて、好みのアプリケーションを起動したり、設定を調整したりすることが可能になるでしょう。
5.セキュリティとプライバシーの強化
音声データに頼らないため、この技術はプライバシーに敏感な環境やセキュリティが重要な状況での使用に適しています。例えば、公共の場所やオフィスでのデバイス操作が、周囲に聞かれることなく行えます。
6.ヘルスケアとフィットネスの分野での応用
この発明は、ユーザーの身体の動きを分析することで、健康状態やフィットネスレベルのモニタリングにも利用できるでしょう。例えば、運動中のフォームの改善や、日常生活での姿勢の分析などに役立てることが可能でしょう。
このように、モーションセンシング技術が私たちの生活の様々な側面に革新をもたらす可能性が示唆されます。
特許の概要
|
発明の名称 |
Keyword detection using motion sensing |
|
出願番号 |
18/103427 |
|
公開番号 |
US2023/0245657A1 |
|
出願日 |
2023.1.30 |
|
公開日 |
2023.8.30 |
|
出願人 |
Apple.Inc |
|
発明者 |
Eddy Zexin LIANG, Madhu Chinthakunta |
| 国際特許分類 |
G06F 3/017 |
| 経過情報 |
本出願は、2022年2月1日に提出された「USING ACCELEROMETER FOR KEYWORD SENSING(加速度計を用いたキーワード検出)」と題された米国仮特許出願第63/305,535号に優先権を主張します。 |
CONCLUSION
皆さん、今年も+VISIONをご覧頂き誠にありがとうございました!
今年も様々な特許をわかりやすく解説させて頂きましたが、みなさんの中で印象的だった特許はありましたでしょうか?
さて、ベストパテント大賞は、編集スタッフが1年間かけて得た情報を元に、
それぞれ注目の特許を各3つずつ選出し、さらに全スタッフでポイント制の投票を行い、順位を決定させて頂いております。
主な審査基準としては、
①その年に発見したかどうか
②より先進性を感じられる特許かどうか
③社会課題を解決したり、活用がイメージできるかどうか
となっております。
今年はAIやロボットなどトレンドになっている分野からの特許がランクインしましたが、
どれも分かりやすく、イノベーションを感じさせてくれる技術となっており
一年を総括するにふさわしい特許だと思います。
1位になった「モーションセンシングを用いたキーワード検出」は、これまでの音声入力における
騒音などの問題点を解決する技術であり、これからスマートフォンを超えるようなウェアラブルデバイの登場を予感させてくれます。
きっと新しいデバイスの新しい入力方法の選択肢の一つとなるはずです。
このように、たったひとつの入力方法でも、デバイス全体の構造やデザイン性を大きく進化させることができます。
小さな発明でも、大きな変化に繋がる可能性を秘めていますので、
みなさんも来年に向けて、活用できそうな特許やアイデアを探してみては如何でしょうか。
2024年はIPマーケットがプラットフォーム化する予定をしておりますので、
引き続き2024年も+VISIONにご期待ください!