効率的な配送の新基準、ライフラインデータが切り開く未来

日々の暮らしに欠かせない配送サービスは、私たちの生活をより便利にしています。しかし、配送の効率化は依然として大きな課題の一つです。
今回紹介する特許発明は、その課題に対する新たなアプローチを提供します。ライフラインの利用データを活用して、特定の配送先の在宅確率を予測し、配送サービスの効率化を図るシステムについて紹介します。電力、ガス、水道など、日常生活を支える重要なインフラからのデータを分析し、配送計画の最適化を実現します。
このシステムでは、先進の機械学習技術を駆使して、配送先の在宅確率を高精度に予測します。配送業務の品質向上だけでなく、配送情報の管理においても配送先のプライバシーを守る配慮がなされています。再配送の回数を減らし、配送コストの削減にも寄与することで、配送サービスの全体的な品質向上を目指します。
発明の背景
従来、宅配業務の効率向上を可能とするシステムが知られています。例えば、在宅情報を地域別及び時間帯別に集計した情報に基づいて各地域の各時間帯における在宅割合を算定し、算定した在宅割合に基づいて配達順の情報を出力するシステムなどが存在します。
しかし、このようなシステムでは、ある時刻における特定の住居(荷物の配達先)の在宅割合など、個別の利用先の属性を推定することはできません。
どんな発明?
発明の目的
本発明は、上記事情に鑑みてなされたものであり、ある時刻における個別の利用先の属性を推定するための情報処理システムを提供することを目的にしています。
発明の詳細
本発明は、ライフライン使用量の時系列データを基に、特定の利用先(例えば住居やオフィスなど)の属性(特に在宅や不在などの状態)を予測するための情報処理システムに関連しています。
そして、本発明の核心となるのは、上記のライフライン使用量(特に電力使用量)の時系列データを効果的に活用して、利用先の現在または将来の属性を精度高く予測する点にあります。
情報処理システムの主要構成要素
取得部: 対象時刻を含む一定期間(第1期間)のライフライン使用量の時系列データを取得します。このデータは、特定の利用先でのライフライン(電力)の使用状況を示しています。
正規化部: 取得した利用データから、第1期間より短い期間(第2期間)にわたるライフライン使用量の正規化された時系列データ(正規化利用データ)を生成します。この正規化は、ライフライン使用量の集合を基準にして行われ、データのバリエーションを均一化することで、より精度の高い予測を可能にします。
学習部: 正規化された利用データと、対象時刻における利用先の属性(在宅・不在)を学習データセットとして使用し、利用先の正規化利用データが入力された場合にその属性の予測値を出力するように学習モデルを学習させます。
予測部: 生成された正規化利用データを学習済みモデルに入力し、利用先の属性(在宅・不在)の予測値を演算します。
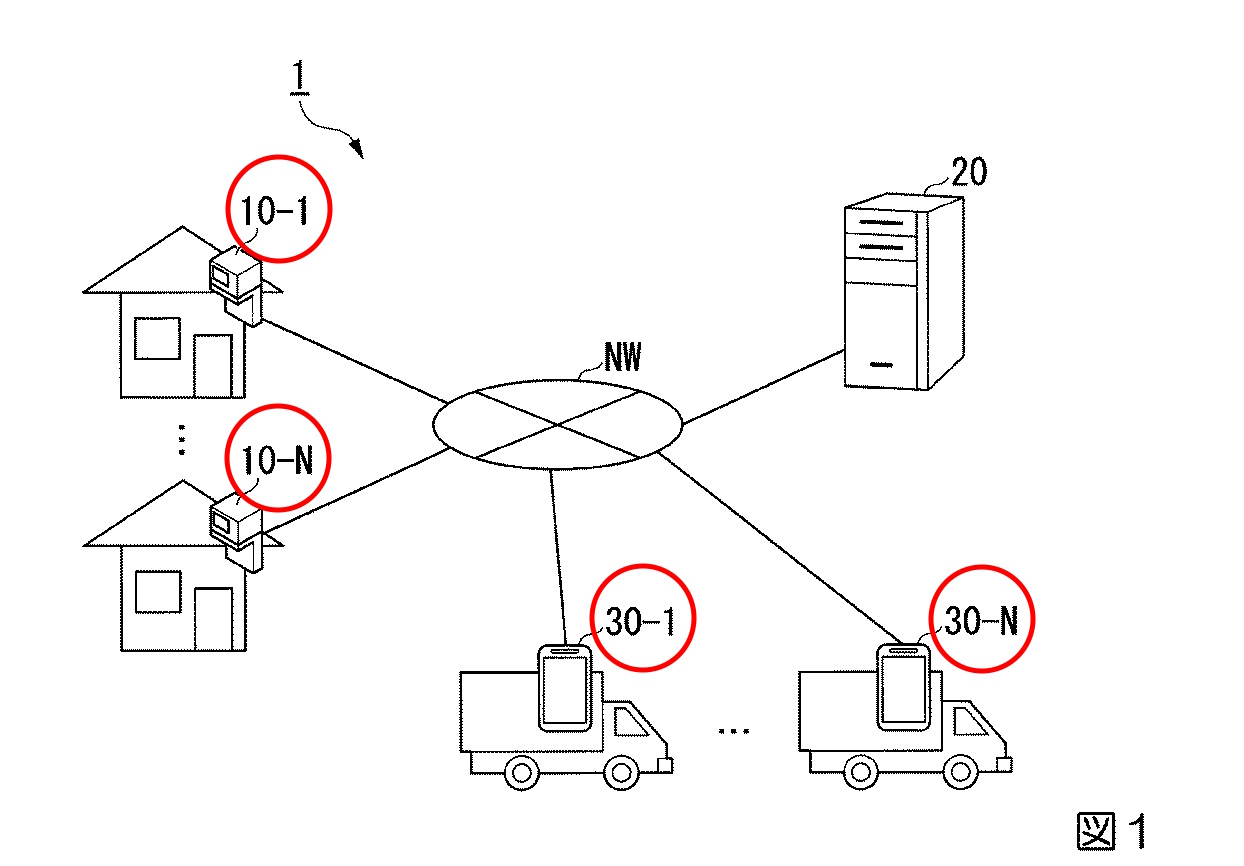
図1は、情報処理システム1の一例を示す概略図です。
情報処理システム1は、複数のスマートメータ10、サーバ20、及び、複数の配送端末30を備えます。
スマートメータは住居に設置され、電力使用量を計測する通信機能付きの電力量計です。これらのデータは、サーバによって収集され、住居の電力履歴と在宅履歴に基づいて学習が行われます。この学習には、住居が配達物を受け取ることが可能な在宅状態か、人が存在しないか受け取ることが不可能な不在状態かを示す情報が含まれます。サーバはこれらの情報と学習結果を基に、配送端末に配送順や予測結果などの出力情報を送信します。配送端末はこの情報を表示し、配送者は指示に従って配送を行い、結果を入力します。このシステムにより、電力情報から配送先の在・不在を予測し、人がいると予測される時間に効率的に荷物を届けることが可能になります。
本発明で用いられるサーバは、通信部、記憶部、処理部を含む構成で、ネットワークを介した各種通信、プログラムや処理結果の保存、入力情報に基づく出力情報の生成を行います(図3)。具体的には、電力履歴と在宅履歴を基に学習データセットを生成し、それに基づいて学習し、学習結果を記憶します。スマートメータからの電力情報や配送荷物の情報を取得し、将来の在・不在を予測、記憶し、配送端末の現在地情報を基に次の配送先を決定して配送端末に送信します。記憶部は、教師データ、学習結果、スマートメータ情報、荷物情報、時刻情報、予測情報、地図情報、配送情報を保存する複数の専用記憶部を含み、各種情報の処理と保存を担当します。
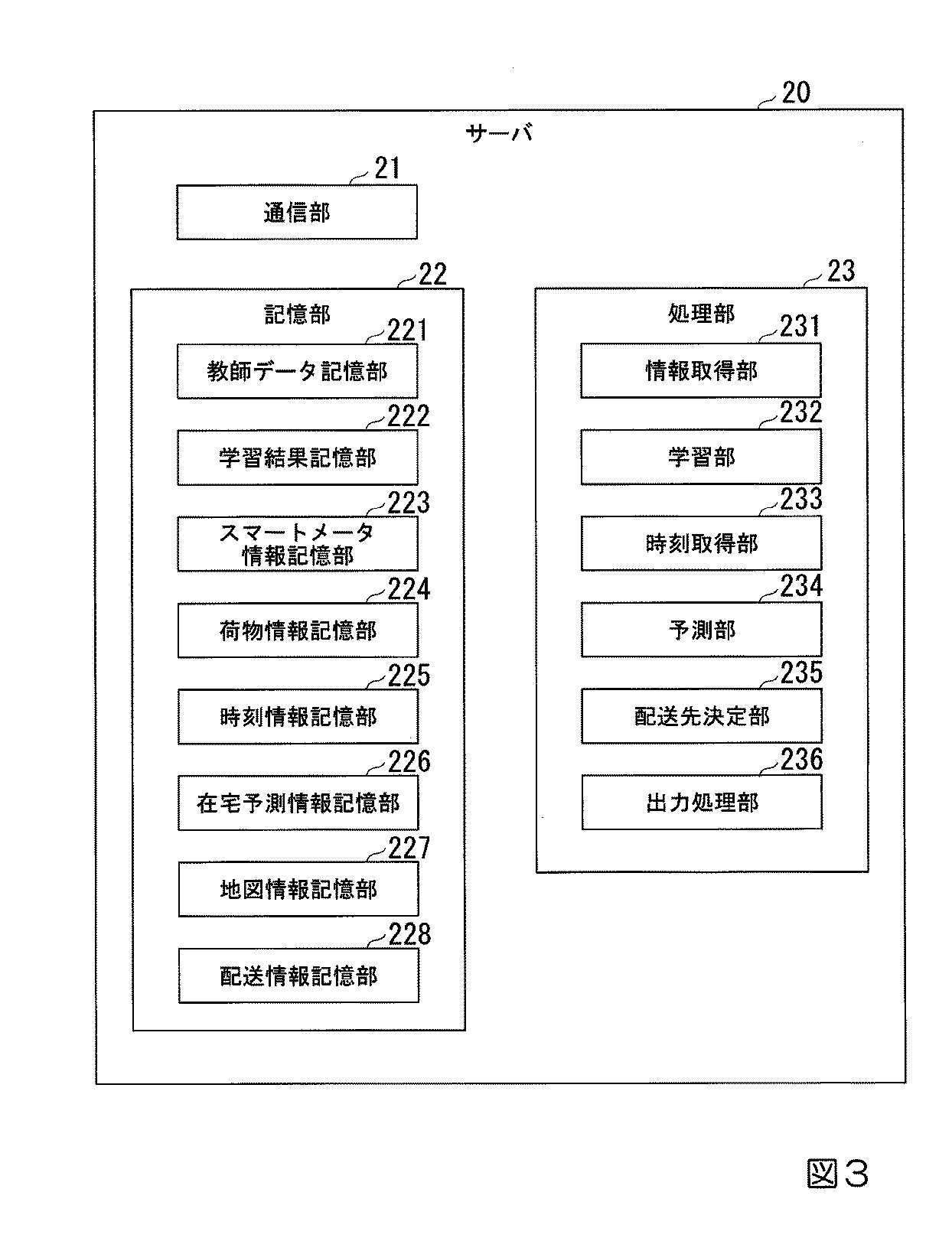
このサーバの記憶部は、教師データ、学習結果、スマートメータ情報、荷物情報、時刻情報、予測情報、地図情報、配送情報を含む複数の専用部分で構成されます。これらはそれぞれ、電力履歴と在宅履歴、学習したモデル、スマートメータの設置情報と電力履歴、配送荷物の詳細、現在時刻、予測した在・不在結果、配送先案内に必要な情報、配送順序や配送結果などの配送関連情報を記憶します。これにより、サーバは電力使用量と住居の在・不在状態を学習、予測し、効率的な配送計画を立てるための情報を管理します。
次に、記憶部が記憶する教師データ、設置情報、スマートメータが取得した電力情報、荷物情報、予測結果、配送情報の一例について、説明していきます。

図4では、電力と在宅履歴を特定の測定期間に対応付けた教師データの例を示しており、特定の1分間の期間において、電力消費量が0.6であり、その時の在宅状態が不在であることを示しています。
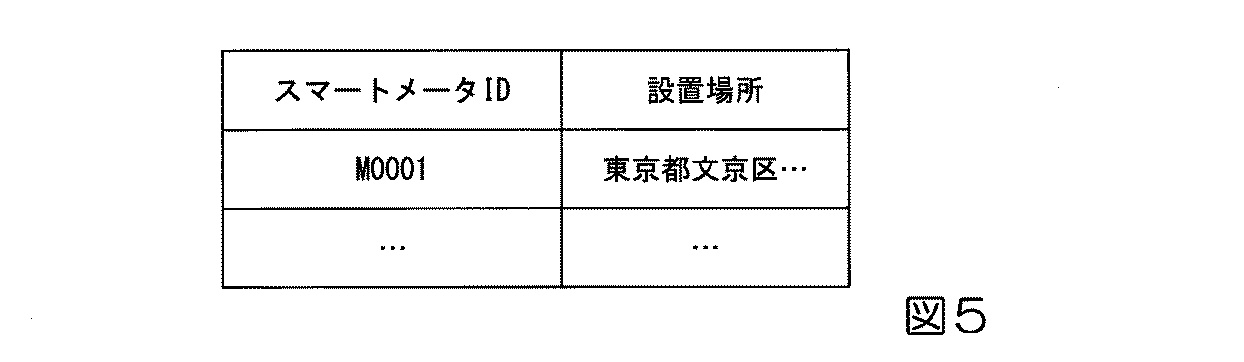
図5は、スマートメータのIDとその設置場所を対応付けた設置情報の例を説明しており、ID「M0001」のスマートメータが東京都文京区に設置されていることを示しています。
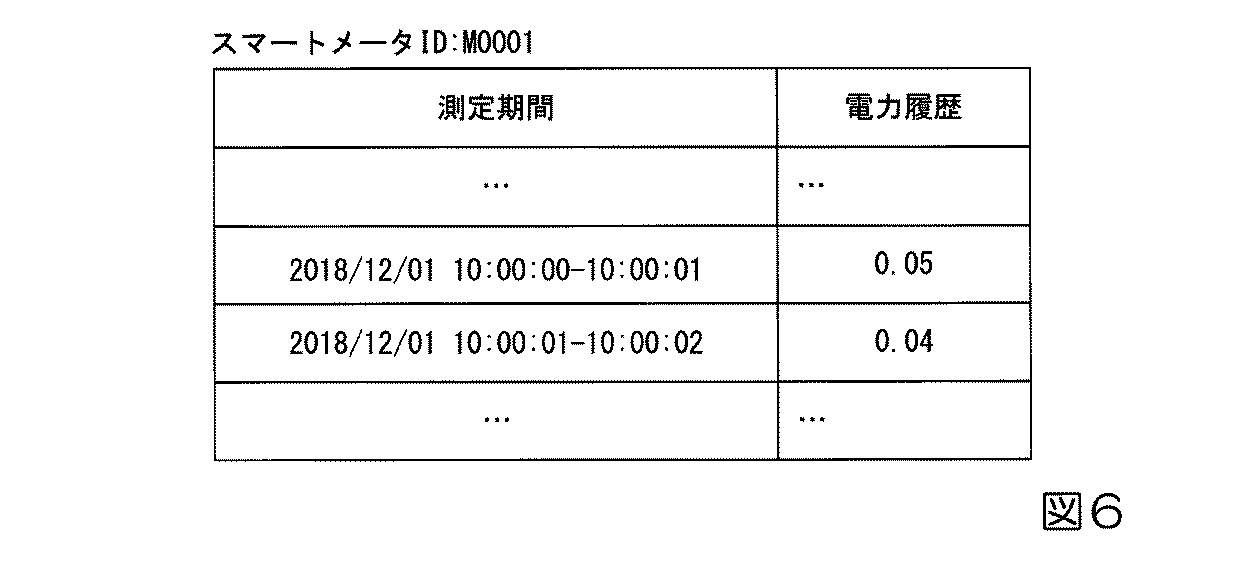
図6では、スマートメータによって取得された電力情報の例を示し、特定のスマートメータ(ID「M0001」)が一定期間(2018/12/01の10:00:00から10:00:01)に0.05の電力を測定したことを示しています。
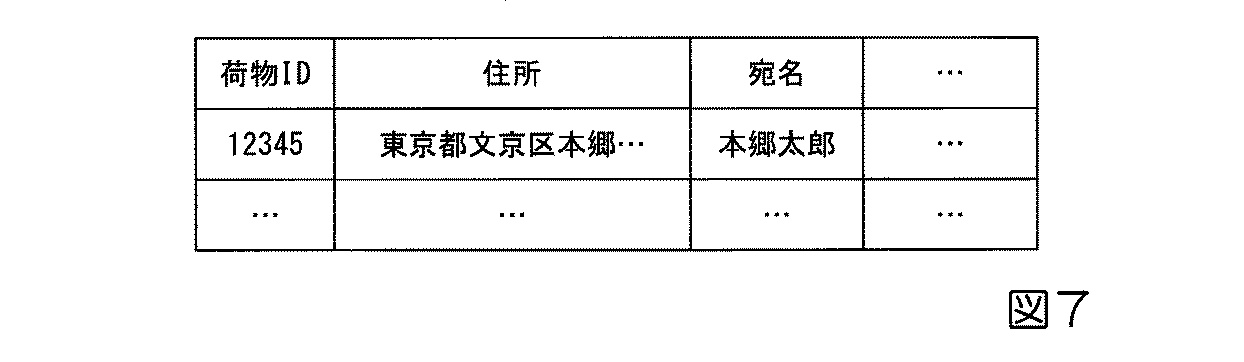
図7は、荷物ID、配送先住所、宛名を関連付けた荷物情報の例を示しており、荷物ID「12345」が東京都文京区本郷の「本郷太郎」宛に配送されることを示しています。
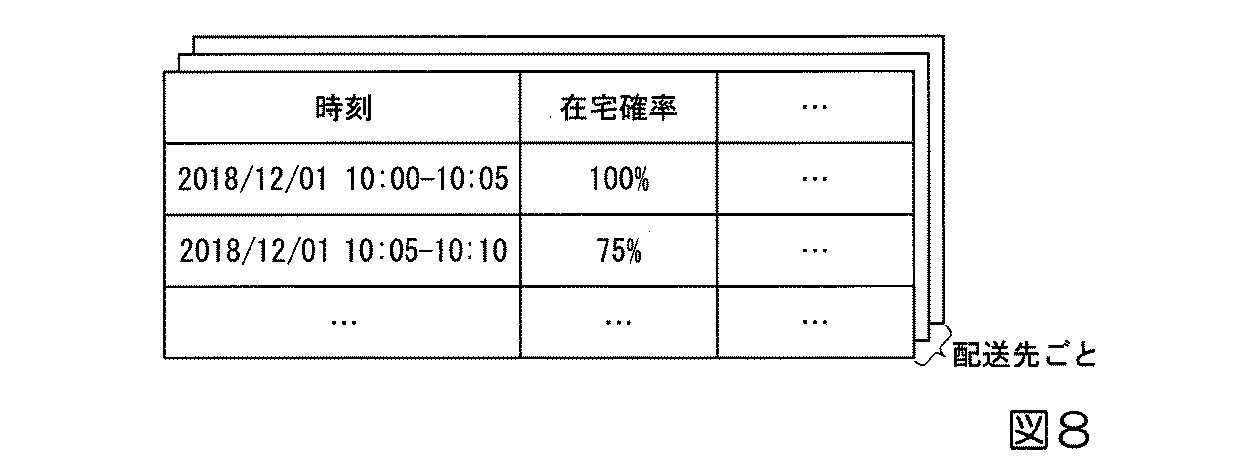
図8に示された予測結果の例では、特定の配送先の在宅確率が予測時刻(2018/12/01の10:00から10:05)に100%であることが示されています。
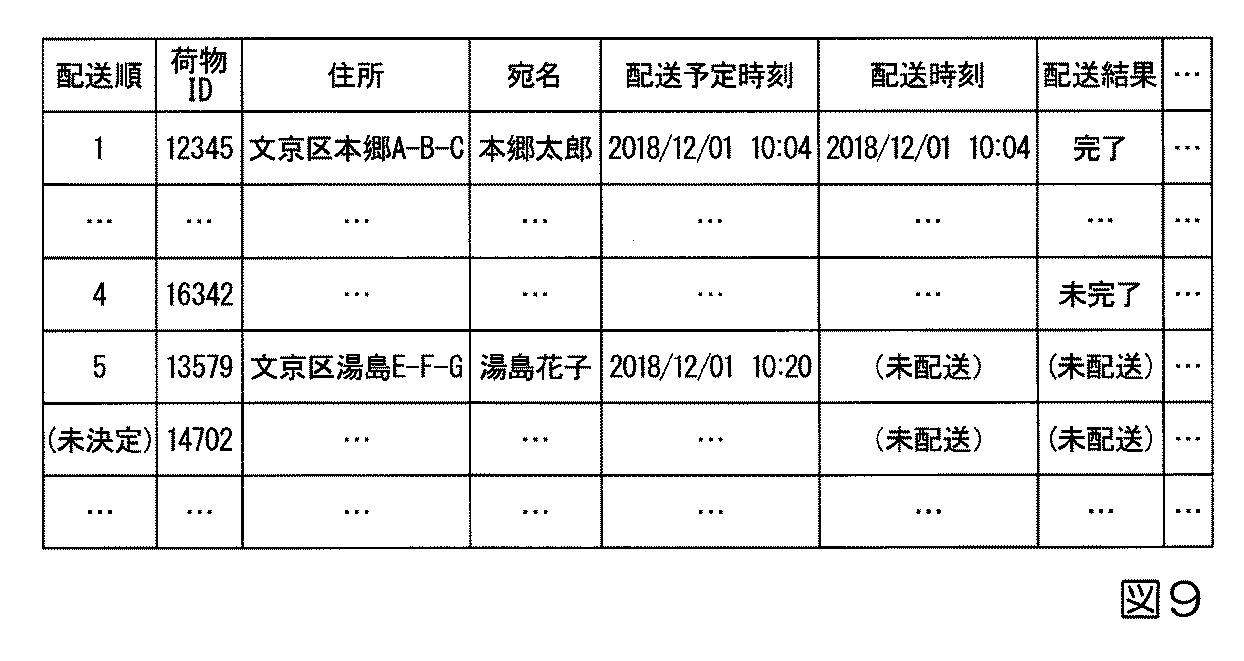
図9は、配送情報の例を示しており、配送順序、荷物ID、配送先住所、宛名、配送予定時刻、実際の配送時刻、配送結果を対応付けた情報で、特に「配送順」1の荷物は配送が完了し、「配送順」4の荷物は未完了であること、および「配送順」5の荷物がまだ配送されていないことを示しています。
サーバの処理部について
図3に戻り、サーバの処理部について見ていきます。
処理部23は、情報取得、学習、時刻取得、予測、配送先決定、出力処理の各部分を含み、サーバの中心的な機能を担っています。
情報取得部231はスマートメータからの電力情報や配送端末からの配送結果を取得し、それらを記憶部に保存します。また、教師データを用いて学習データセットを生成し、所定の期間ごとの電力履歴の統計値や在宅履歴の代表値を算出します。
学習部232は提供された学習データセットを用いて学習を行い、電力履歴の統計値を独立変数、在宅履歴の代表値を従属変数として設定し、学習モデルを構築します。このモデルは将来の時刻における在宅確率を予測するために使用されます。
時刻取得部233は現在時刻を取得し、この情報を時刻情報記憶部に保存します。
予測部234は学習結果と取得した電力情報を用いて、配送先の将来の在宅確率を予測し、予測結果を記憶します。
配送先決定部235は予測結果、荷物情報、地図情報、配送端末の位置情報に基づいて次の配送先を決定します。これには、移動距離、所要時間、在宅確率を考慮した距離(OWD)を算出し、OWDが最小となる配送先を次の配送先として選択します。
出力処理部236は次の配送先情報を配送端末に送信し、配送情報の更新がある場合にはそれを通知します。また、配送が完了した場合や配送を行わない決定が下された場合には、配送終了情報を配送端末に送信します。
サーバの処理部は、電力情報と在宅履歴から学習データセットを生成し、学習済みモデルを用いて将来の在宅確率を予測、これに基づいて効率的な配送計画を立案することで、配送効率を最大化する役割を果たしています。
サーバの動作について
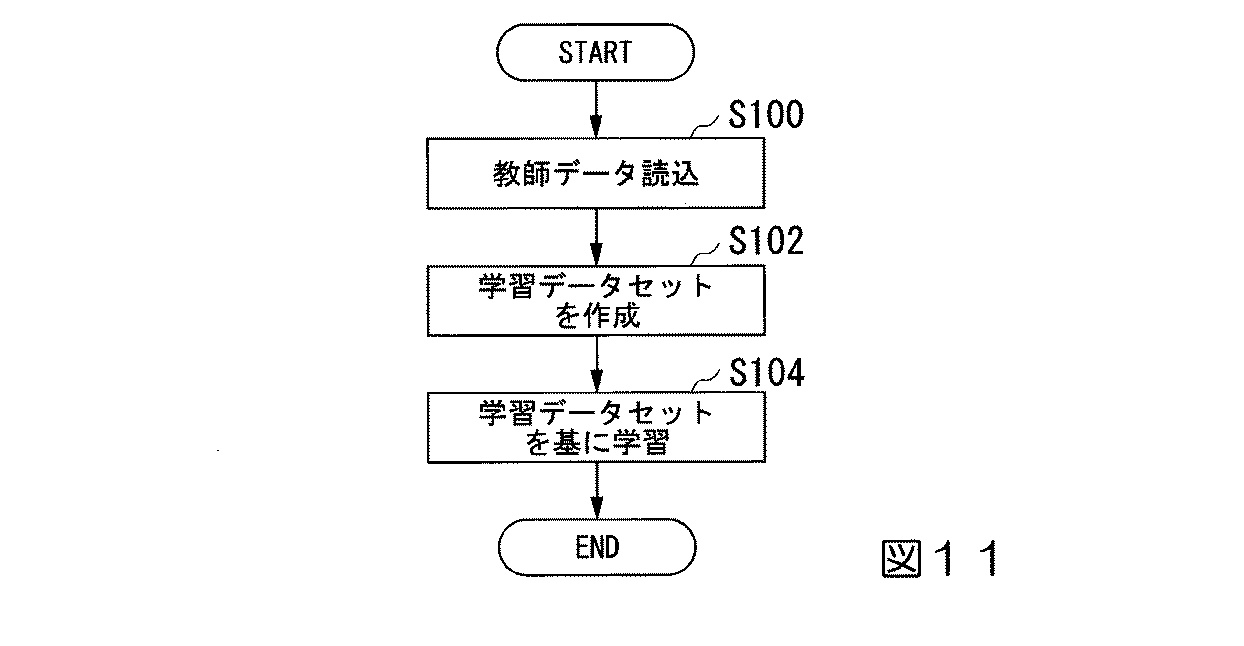
図11は、サーバ20の学習段階の動作をフローチャートで示しています。教師データを読み出し、学習データセットを作成し、最後に学習を行って学習結果を記憶します。
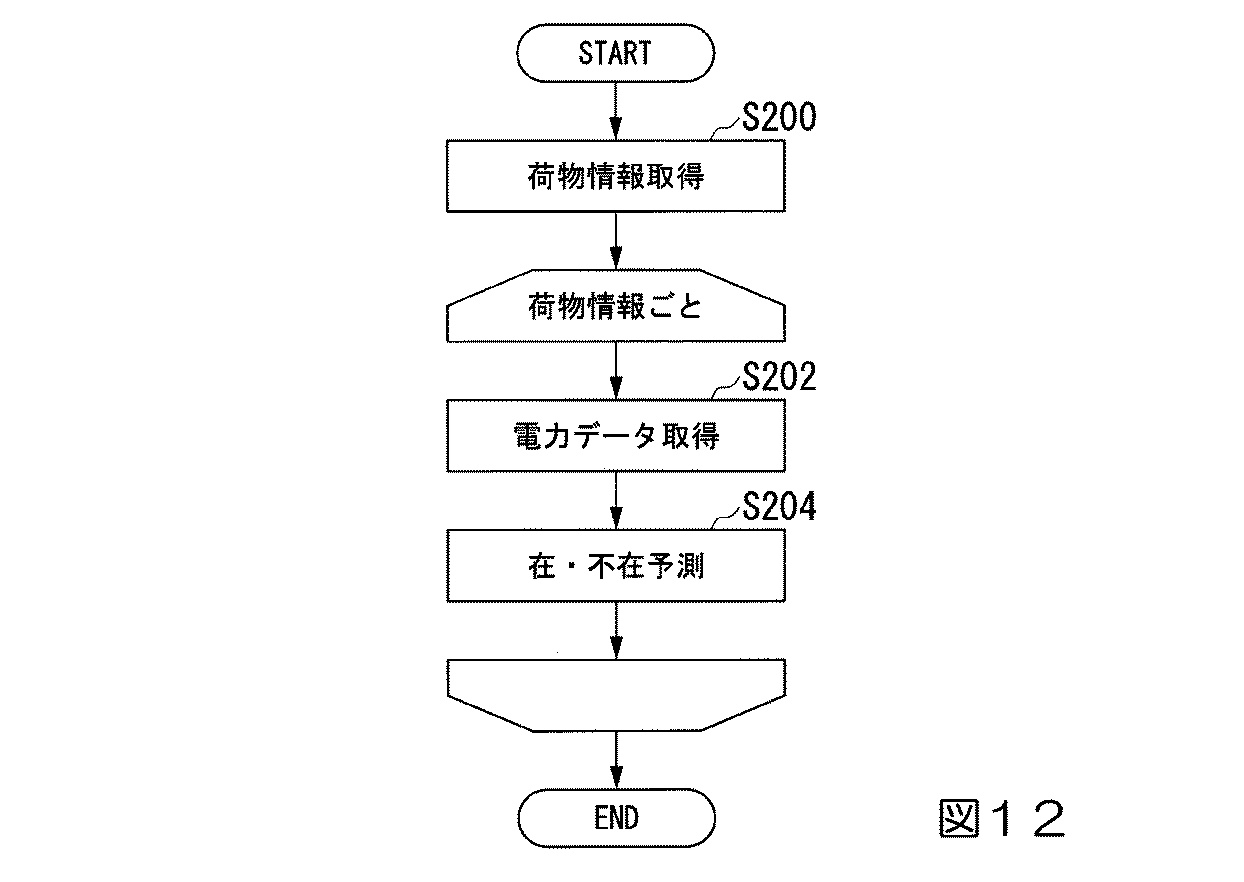
図12では、予測段階のサーバ20の動作をフローチャートで表しており、荷物情報の取得、配送先の電力履歴の取得、そして学習結果を用いて配送先の将来の在・不在を予測し、予測結果を記憶する手順が示されています。
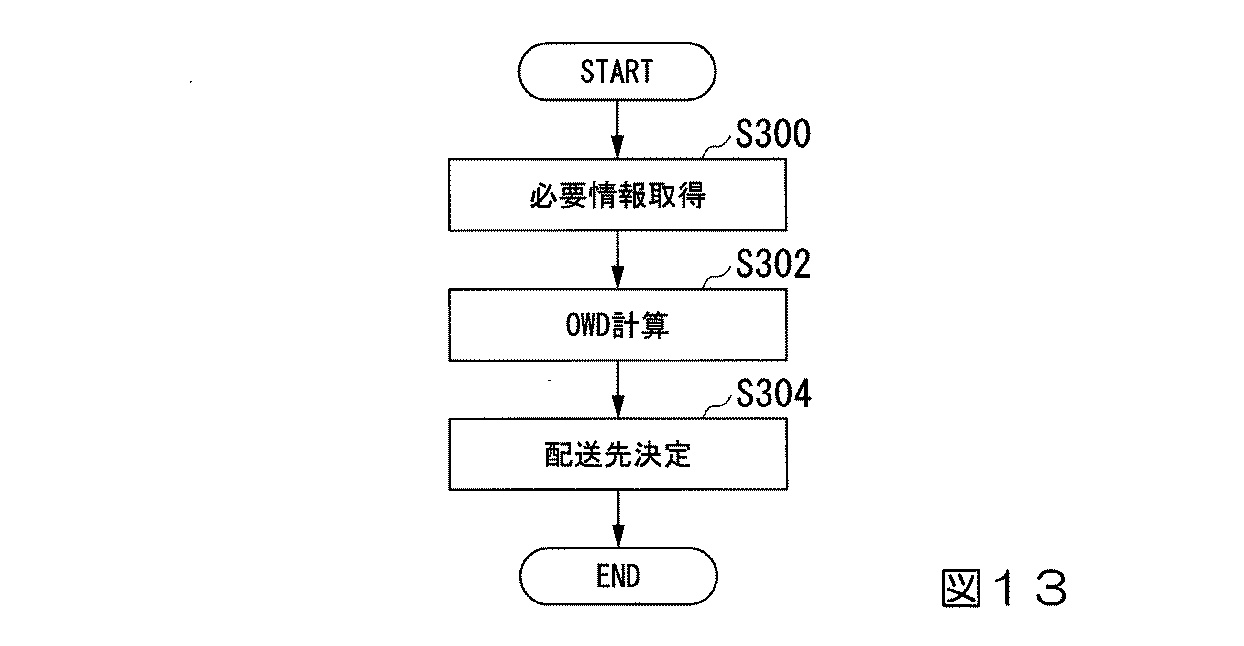
図13は、次の配送先の決定段階におけるサーバ20の動作をフローチャートで示しています。配送情報の取得、未配送先の配送情報と地図情報の取得、未配送先のOWD計算、そして最もOWDが小さい未配送先を次の配送先として決定し、配送情報に記憶する手順を示しています。
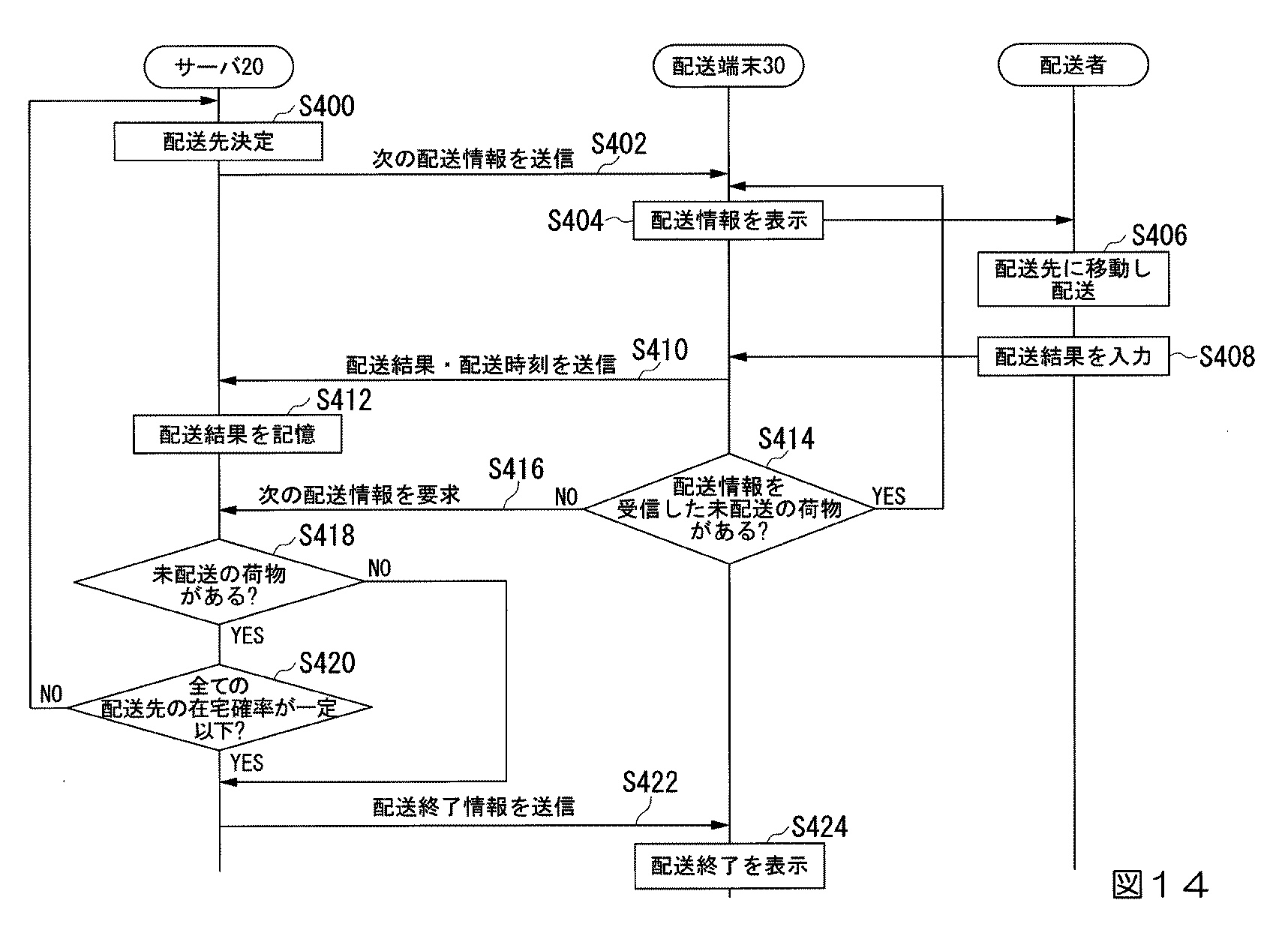
図14は、情報処理システム1の配送処理の動作をフロー図で説明しており、最初の配送先の決定、配送情報の送信、配送情報の表示、配送実施、配送結果の入力と送信、次の配送先の情報要求と受信、そして配送終了情報の送信と表示までの一連の配送処理手順を示しています。
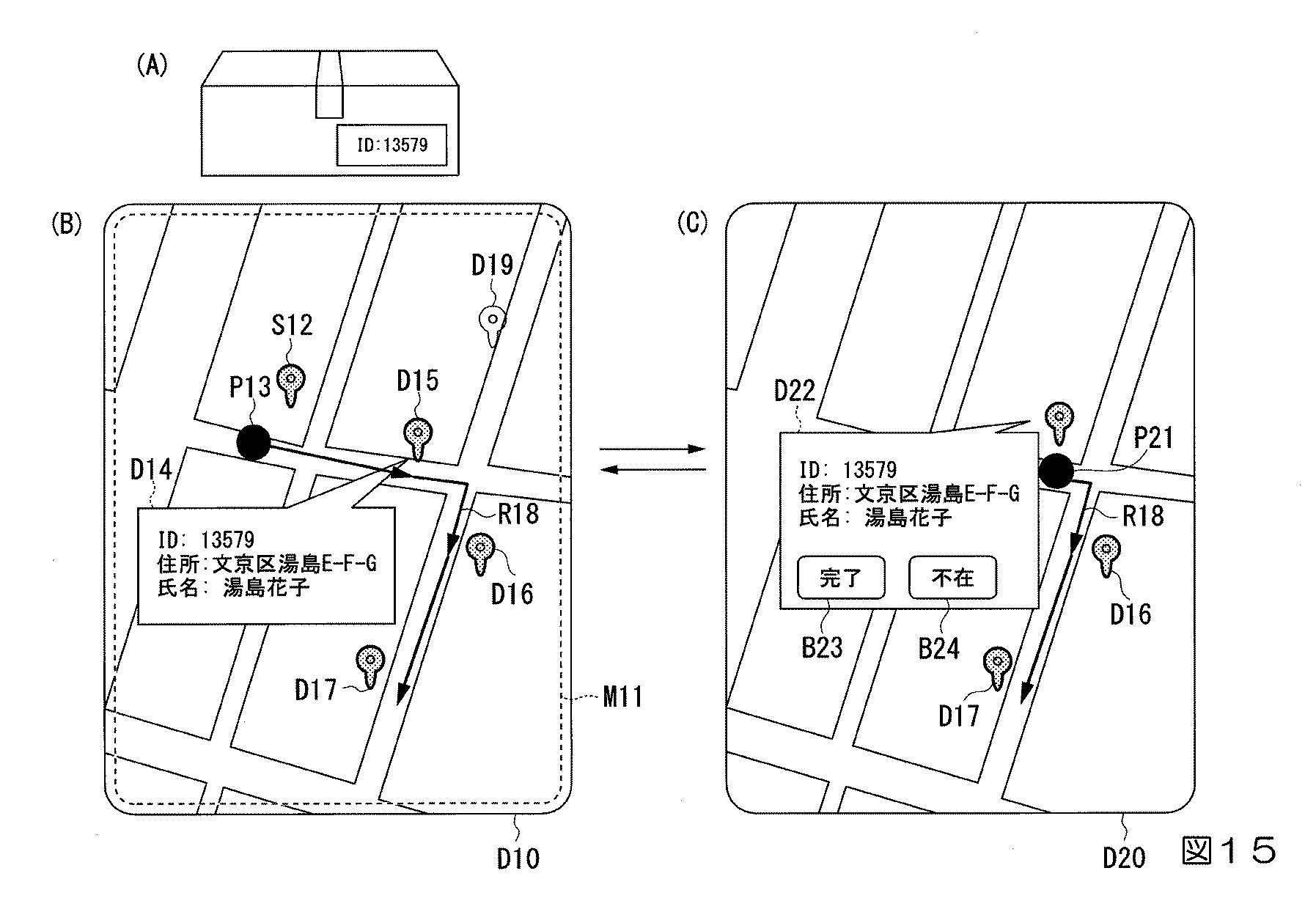
図15は、配送荷物と配送端末の表示例を示しています。配送荷物(図15(A))には荷物IDのみ記載し、配送先の情報は含めないことでプライバシーを保護しています。配送端末の表示画面D10(図15(B))では、地図画像、配送先のアイコン、配送情報、移動経路などを含み、新しい配送先情報を提示します。表示は配送端末の現在位置と直前及び新しい配送先を中心に構成され、不在の配送先情報は表示しないことでプライバシーを守ります。
表示画面D20(図15(C))は配送結果の入力画面で、配送員が配送完了または未完了の結果を入力します。この表示方式により、配送先の情報を限定的に表示し、配送員による配送先のプライバシーへの配慮を可能にしています。

本発明の効果を検証するためのシミュレーションでは、本実施形態に基づく配送順決定方法(OWDを用いた方法)と他の2つのベンチマーク手法による配送処理の効率性を比較しました。
1つ目のベンチマークは最短配送経路に基づく方法で、予測情報を使用しません。2つ目のベンチマークは平均在宅確率に基づいて配送先を決定する方法で、リアルタイムの電力履歴を利用しません。一方、OWDを用いた方法では、リアルタイムの電力履歴に基づき在宅予測を行い、配送順を決定します。
シミュレーションは、100件の住居を持つ仮想マップ上で行われ、各住居は異なる電力履歴と在宅履歴を有しています。このシミュレーションでは、OWDのパラメータCを0.6、将来の存在確率の閾値hを0.9と設定しました。
結果として、OWDを用いた方法は他の2つのベンチマーク手法と比較して、1回目の配送サイクルでの配送完了率が高く(98%)、全配送サイクルにおける未完了の割合が最も低かった(2.2%)。また、全配送サイクルの経路の合計は、OWDを用いた方法の方が6%減少しました。
これらの結果から、OWDを用いた方法は再配送が少なく、効率的に荷物を届けることができることが示されました。この方法は、配送先の電力情報と学習結果を基に配送先の在宅確率を予測し、効率的な配送順を決定することで、配送効率の向上とプライバシーの保護を両立させることが可能です。
実施例の結果
本発明の実施例では、ライフラインの利用状況を分析し、特定の期間内でのライフライン使用量の正規化データを基に機械学習を用いた予測モデルの学習と評価を行っています。具体的には、正規化利用データに係る第2期間の長さ(予測に利用する期間)、第1期間の長さ(学習に利用する期間)、および時系列の周期(データを取得する時間間隔)を変化させて、それぞれの設定における予測精度(AUC)、学習時間、および予測時間の影響を観測しました。
実験結果として、以下の点が明らかになりました:
第2期間の長さが12時間以上36時間以下の範囲で予測精度が高くなり、特に24時間の設定で最も高い予測精度を示しました。これは、人間の概日リズムが24時間周期であることが影響していると考えられます。
第1期間の長さに関しては、8日以上16日以下の範囲で予測精度が高くなり、14日が最も効果的であることが示されました。これは、すべての曜日に関するデータが含まれることと、季節変動の影響を抑制することが理由として挙げられます。
時系列の周期は、1分以上30分以下の範囲で予測精度が高くなり、15分が最適であることが判明しました。これは、適度なデータの細かさが予測精度を向上させるためと考えられます。
本実施例における機械学習モデルの実験と評価は、LightGBMを用いて実施されました。シミュレーション結果は、様々な設定下での予測精度の違いを示し、特定の条件下で予測モデルの性能を最大化するための洞察を提供しています。
その他の応用について
本発明の明細書中には、さまざまな実施形態についての拡張性と適応性が説明されています。発明は、特定の実施形態に限定されるものではなく、その範囲内で多岐にわたる設計変更が可能であるとされています。
主なポイントは以下の通りです
ライフラインの使用量に基づく予測:電力以外にも、ガス、水道、通信データ量などのライフラインの使用量を用いて、在・不在を判定することが可能であることが示されています。これらの情報を活用することで、同様の効果を得ることが可能です。
予測の対象の拡張:在・不在の判定だけでなく、居住者の世帯属性、健康状態、商品の購買指数などの他の属性の予測にも応用できることが説明されています。
配送先の決定方法:配送先を複数同時に決定する方法以外にも、1度に1つの配送先を決定する方法も可能であり、配送結果の送信時に次の配送情報を要求する方法も考えられます。
表示方法の柔軟性:表示部に表示させる配送先の数についても、配送者が現場で選択することが可能であり、表示内容のカスタマイズが可能であることが示されています。
不在時の配送完了の考慮:宅配ボックスの利用や、オフィスなど別の受取場所の存在など、不在時でも配送を完了できる状況を考慮に入れることができる。
配送結果の反映:配送できなかった荷物について、配送端末に連絡先情報を表示し、配送者が直接連絡を取れるようにする方法も提案されています。
再予測の可能性:配送開始前だけでなく、所定の時間間隔ごとに在宅確率の再予測を行い、配送順を更新することも可能です。
外部情報の利用:気象情報や災害情報、カレンダー情報など、外部からの情報を取り入れて、予測の精度を向上させることも検討されています。
これらの拡張性と適応性は、発明が実用的なシナリオにおいて多様な形で応用できることを示しています。ライフラインの使用量を活用した予測モデルは、在・不在の判定に留まらず、より広範な応用が期待されます。
ここがポイント!
この発明は、ライフラインの使用量データを基に配送先の在不在予測や居住者の生活パターンを分析し、これをもとにした効率的な配送計画を立案するシステムに関連しています。特に、電力、ガス、水道などの利用量データを活用し、配送先の在宅確率をリアルタイムに予測することが核となっています。これにより、配送効率の向上、再配送の削減、及び配送コストの削減を目指します。
この発明のポイントをまとめると、以下のような点が挙げられます。
ライフライン利用データの活用:電力使用量などのライフライン利用データを利用して、配送先の在宅確率を予測します。これは、特定のライフラインの消費パターンが居住者の在宅状態と関連があることを利用したものです。
機械学習モデルの適用:ライフライン利用データを基にした機械学習モデルを用いて、在宅確率の予測精度を高めます。このモデルは、ライフスタイルの周期性(例:概日リズム)や季節性の影響を考慮しています。
予測に基づく配送計画の最適化:予測された在宅確率を基に、配送順序を決定し、効率的な配送ルートを計画します。これにより、不在での配送失敗を減らし、配送効率を向上させます。
多様なライフラインとデータ周期の柔軟な取り扱い:電力以外にもガスや水道利用量を含む様々なライフラインのデータを使用し、また、データ収集の周期を変化させることで最適な予測精度を求める柔軟性を持っています。
プライバシーの考慮:実際の住所や宛名などの詳細な情報を直接配送荷物に記載せず、配送端末で管理することで、プライバシー保護を図ります。
未来予想
この特許発明の効果を踏まえると、以下のような未来予想が可能です。
配送業界の効率化:このシステムの広範な採用により、配送業界全体の効率が大幅に向上し、環境負荷の低減、配送コストの削減、顧客満足度の向上が期待されます。
スマートシティの実現:都市全体でのライフライン利用データの分析と活用が進むことで、より賢く、生活者中心のサービス提供が可能になるスマートシティの実現に貢献します。
ライフスタイルの個別化対応:配送以外にも、ライフライン利用データを用いた居住者のライフスタイルや健康状態の分析により、個々の生活者に合わせたサービス提供が展開される可能性があります。これにより、より快適で健康的な生活支援が可能になるでしょう。
特許の概要
|
発明の名称 |
情報処理システム、学習済みモデル、情報処理方法、及びプログラム |
|
出願番号 |
特願2020-7464 |
|
公開番号 |
特開2021-114231 |
|
特許番号 |
特許第6908742号 |
|
出願日 |
2020年1月21日 |
|
公開日 |
2021年8月5日 |
|
登録日 |
2021年7月5日 |
|
審査請求日 |
2020年3月23日 |
|
出願人 |
株式会社JDSC |
|
発明者 |
大杉 慎平 |
| 国際特許分類 |
G06Q 10/08 |
| 経過情報 |
拒絶理由が通知されることなく、一発特許査定。 |