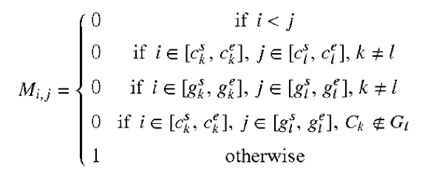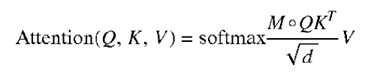プレゼンテーションをAIが自動提供

会社勤務をしている方の中には、仕事中はずっとPCに向かって様々な資料を作り続けることを業務としている方も多いのではないでしょうか。基本的に資料作成はユーザーが文書の内容を手入力することが当然でしたが、今後はその常識が変わっていくかもしれません。
今回紹介する特許は、ユーザが手動でコンテンツを作成する労力を軽減させるものです。ユーザは短いテキスト入力をするだけで、質の高い資料を生成させることができます。また、ユーザは生成された資料を保持、編集、破棄することができるため、自分のニーズに合わせてカスタマイズすることが可能です。
この特許は、プレゼンテーションの作成や資料作成にかかる時間や労力を削減するのに役立ち、特に、短い納期や制作に追われている場合には大きな助けとなるでしょう。
発明の背景
従来、ユーザはプレゼンテーション作成アプリケーション、ワードプロセッシングアプリケーションなどのコンテンツ開発ツールを使用してコンテンツを作成していました。ここで用いられるコンテンツや素材のデザインは、ユーザ自身によって作成・用意されます。一部のツールではデザインやレイアウトのテンプレートなどの提案を提供しますが、テキストのコンテンツはユーザが作成し、提案はユーザのテキスト入力に依存しています。
どんな発明?
発明の目的
本発明は、応答コンテンツの一部を、コンテンツ生成アプリケーションと互換性のあるコンテンツドキュメントに更新することを目的としています。また、ユーザクエリに基づいてバイアスの可能性を検出し、ヒントを生成して表示すること、さらに、複数のユーザクエリやユーザの選好履歴などを考慮して、プロンプトやヒントを生成することも目的としています。
本発明により、ユーザのテキスト入力への依存を削減し、ユーザのわずかな入力に基づいて完全なテキストを生成する方法を提供します。開示されるシステムは、どのようなコンテンツ開発アプリケーションでも実装することができます。このソリューションは、完全な自然言語生成モデルを使用して、ユーザが少ないテキスト入力で反復的にコンテンツを生成することを可能にします。
ユーザは短い問題や質問を提供する機会を与えられることがあります。システムはユーザの入力を使用してプロンプトを生成し、自然言語生成モデルにプロンプトを提供し、自然言語生成モデルから出力を取得し、出力に基づいてユーザにコンテンツドキュメントで使用する完全なコンテンツを提案することができます。このプロセスは反復的に行われます。
ユーザは編集や追加コンテンツの要求、明確化、デザイン支援などを必要な回数だけ行い、最初に作成されたコンテンツがユーザの最小限の追加入力に基づいて更新・修正され、ユーザが提案された結果を選択して最終化するまでの間、修正を行うことができます。これにより、ユーザは完全で正確なコンテンツドキュメントを生成するためにかかる時間を大幅に短縮することができます。
発明の詳細
では、本発明の詳細を説明していきます。
本発明のシステムは、機械的構成として、ソフトウェア、ファームウェア、ハードウェア、またはそれらの組み合わせがシステムにインストールされていることにより、特定の操作やアクションを実行するように構成することができます。1つまたは複数のコンピュータプログラムは、データ処理装置によって実行されると、その処理によって装置がアクションを実行するようにする命令を含むことにより、特定の操作やアクションを実行するように構成することができます。1つの一般的な側面は、自動的にインテリジェントなコンテンツを生成するためのコンピュータ実装方法を含みます。この方法は、ユーザのクエリを受け取り、ユーザクエリの意図からアクションを決定することを含みます。この方法は、アクションに基づいてプロンプトを生成し、そのプロンプトを自然言語生成モデルに提供することを含みます。
プロンプトに対して、自然言語生成モデルからの出力を受け取ります。この方法は、出力に基づいて、コンテンツ生成アプリケーションと互換性のある形式で応答コンテンツを生成することを含みます。さらに、この方法は、少なくとも一部の応答コンテンツを表示することを含みます。この側面の他の実施例には、それぞれが前記方法のアクションを実行するように構成された対応するコンピュータシステム、装置、および1つ以上のコンピュータ記憶装置に記録されたコンピュータプログラムが含まれます。

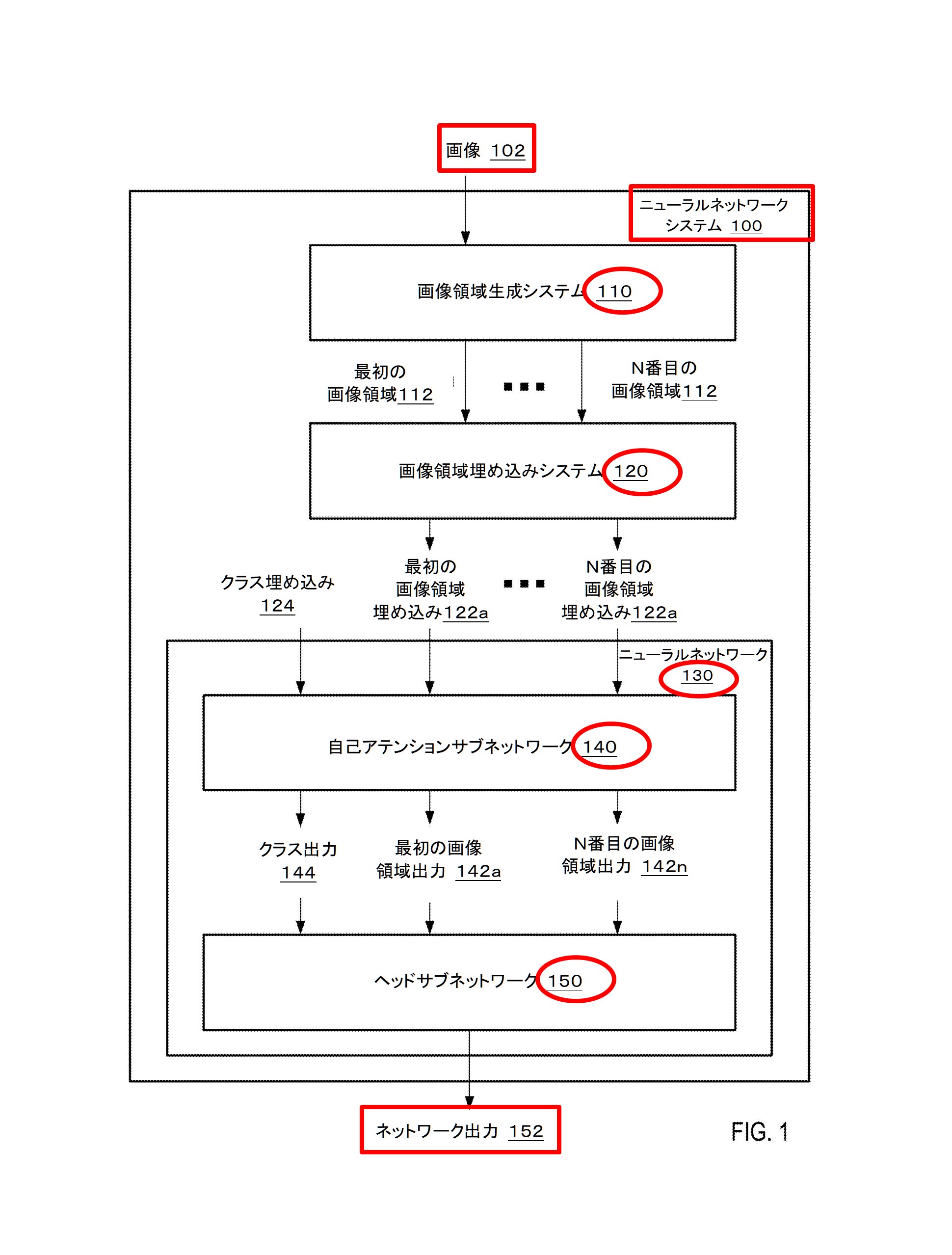
上図は、自動インテリジェントコンテンツ生成のための例示的なシステム100を示したものです。システム100は、ユーザシステム105、アプリケーション/サービスコンポーネント110、プロンプト設計コンポーネント115、知識リポジトリ120、および自然言語生成モデリングコンポーネント125を含むものです。
ユーザーシステム105は、プロセッサによって実行される命令を格納するためのメモリを含みます。メモリには、コンテンツ生成アプリケーション130およびユーザーシステムの設計コンポーネント135が含まれます。コンテンツ生成アプリケーション130は、ワードプロセッシングアプリケーション(例:MICROSOFT WORD®)、プレゼンテーション作成アプリケーション(例:MICROSOFT POWERPOINT®)、またはその他のコンテンツ生成アプリケーション(例:MICROSOFT EXCEL®、MICROSOFT ONENOTE®、MICROSOFT OUTLOOK®、MICROSOFT PUBLISHER®、MICROSOFT PROJECT®など)である場合があります。ユーザーシステムの設計コンポーネント135は、図に示されるようにユーザーシステム105に含まれます。ユーザーシステムの設計コンポーネント135はクラウドベースでもよく、ユーザーシステム105上のユーザーインターフェースを介してアクセスされる場合があります。ユーザーシステムの設計コンポーネント135は、ローカルでの使用のためにユーザーシステム105上に複製されてもよく、クラウドコンポーネントによる使用のためにクラウド環境にも存在する場合もあります。
クエリ理解コンポーネント140は、ユーザのクエリを処理し、ユーザの要求について判断するために使用されます。クエリ理解コンポーネント140は、ユーザが入力したテキストクエリ(つまり、ユーザクエリ)を受け取り、ユーザの意図を理解しようとします。クエリ理解コンポーネント140は、ユーザの意図を2つのアクションタイプのいずれかに分類します。最初のタイプは、自然言語生成モデルを使用する自然言語アクションです。2番目のタイプは、デザインリクエストや変更などの自然言語以外のアクションであり、自然言語生成モデルは使用されません。
バイアス検出コンポーネント145は、ユーザクエリを評価し、クエリがバイアスのある、有害な、または関連性のないコンテンツを生成する可能性があるかどうかを判断するために呼び出されることがあります。バイアス検出コンポーネント145は、また、自然言語生成モデルからの出力を評価して、コンテンツがバイアスのある、有害な、または関連性のないものであるかどうかを判断するために使用されることがあります。バイアスのある、有害な、または関連性のない出力は、自然言語生成モデルのトレーニングによるものである場合があります。たとえば、システム100で使用される自然言語生成モデルとしては、Generative Pre-trained Transformer 3(”GPT-3″)が挙げられます。これは、ディープラーニングを利用する自己回帰言語モデルです。GPT-3は、人間らしいテキストを生成する強力な自然言語生成モデルです。
ただし、そのトレーニングは、フィルタリングされていない、クリーン化されていない、および潜在的にバイアスのあるコンテンツを使用して行われます。そのため、出力はバイアスのある、有害な、または関連性のないものである可能性があります。このような出力は、バイアス検出コンポーネント145を使用してフィルタリングすることがあります。さらに、特定の入力は、そのような望ましくない出力を生成する可能性が高いです。バイアス検出コンポーネント145は、そのような入力を望ましくない結果を生成する可能性があると識別し、結果を回避するために入力をフィルタリングすることがあります。例えば、入力テキストが「Donald Trumpに関するプレゼンテーション」という場合、この入力はバイアス検出コンポーネント145によってフラグ付けされないかもしれませんが、出力には「Donald Trumpは史上最悪の米国大統領である」というバイアスのある文言、「Donald Trumpは最高のテレビパーソナリティであり実業家である」というバイアスのある文言、「Donald Trumpは実業家であり第45代米国大統領である」という中立的/事実的な文言などが含まれる可能性があります。
さらに、結果には不適切な言語(有害なもの)や関連性のないコンテンツも含まれる場合があります。バイアス検出コンポーネント145は、そのような望ましくない結果をフィルタリングおよび/またはフラグ付けすることがあります。さらに、バイアス検出コンポーネント145は、時間の経過とともに学習する機械学習アルゴリズムなどの人工知能(AI)コンポーネントである場合があります。このため、入力はフラグ付けされるか、バイアスの可能性が割り当てられる場合があります。バイアス検出コンポーネント145が入力が望ましくない結果を提供する可能性があるか、出力が有害な、バイアスのある、または関連性のないものであるか(バイアスの可能性が存在するか、または閾値を超えるかどうか)を判断すると、ヒントコンポーネント150を使用してより関連性の高いまたは望ましい結果を得るためのヒントが提供されることがあります。バイアス検出コンポーネント145は、処理されない可能性のある有害なテキストを検出するブロックリストを含んでいる場合があります。そのような場合には、バイアス検出コンポーネント145は、閾値を超えるバイアスの可能性を割り当てることがあります。一部の実施例では、自然言語生成モデルからの結果が有害であるか、またはユーザからのフィードバックで結果が有害または悪いと報告された場合、バイアス検出コンポーネント145は学習し、ブロックリストに新しい用語を追加することがあります。一部の実施例では、これらの結果とフィードバックを使用して、ブロックリストを拡張することができます。
ヒントコンポーネント150は、望ましくない結果を回避するためのヒントを生成するAIコンポーネントです。たとえば、ヒントコンポーネント150は、「Donald Trumpに関するプレゼンテーション」というプロンプトを受け取り、より具体的な要求が望ましくない結果を生成する可能性が低いと判断する場合があります。例えば、ヒントコンポーネント150は、「Donald Trumpのビジネスに関するプレゼンテーション」、「Donald Trumpの大統領の業績に関するプレゼンテーション」などのヒントを生成することがあります。ヒントコンポーネント150は、これらの結果をユーザに表示するために出力します。
ユーザシステムデザインコンポーネント135がユーザのクエリを処理し、ユーザが要求しているアクションを判断した後、そのアクションまたはユーザクエリはクラウドベースのアプリケーション/サービスコンポーネント110に送信されます。アプリケーション/サービスコンポーネント110は、ユーザクエリまたはアクションをプロンプト設計コンポーネント115に送信することがあります。プロンプト設計コンポーネント115は、自然言語生成モデル125への入力に適したプロンプトを生成するために使用されます。プロンプト設計コンポーネント115は、機械学習アルゴリズムやニューラルネットワークを使用して、時間の経過とともにより良いプロンプトを開発するAIコンポーネントです。プロンプト設計コンポーネント115は、ユーザの好みデータ、プロンプトライブラリ、およびプロンプトの例などを含むナレッジリポジトリ120にアクセスして、プロンプトを生成し、それをアプリケーション/サービスコンポーネント110に返します。
アプリケーション/サービスコンポーネント110は、プロンプトを自然言語生成モデル125に提供し、応答コンテンツを取得します。応答コンテンツはユーザシステム105に送信され、提案生成コンポーネント155によって処理されます。提案生成コンポーネント155は、ユーザインターフェースやコンテンツ生成アプリケーション内でのコンテンツの表示のために1つ以上の提案を生成する場合があります。一部の実施例では、提案生成コンポーネント155はコンテンツ生成アプリケーション130の一部であり、応答コンテンツの表示のためにデザインの提案ツールを利用することがあります。提案の例は、図4〜9に示されるようなユーザインターフェースに提供されます。選択された提案は、コンテンツ文書に組み込まれ、コンテンツ生成アプリケーション130によって表示されます。
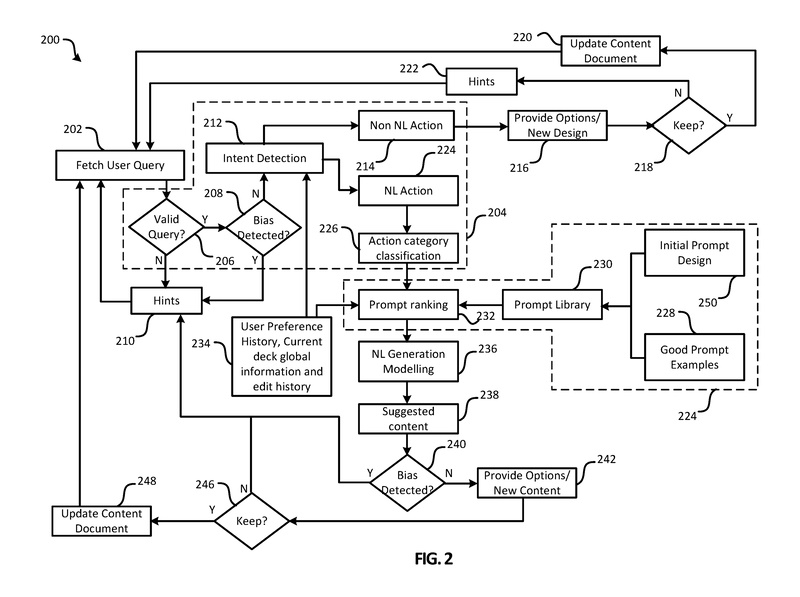
図2は、システム100によって実行されるアクションのフローチャート200を示しています。ステップには、ユーザシステムデザインコンポーネント135、コンテンツ生成アプリケーション130、アプリケーション/サービスコンポーネント110、プロンプト設計コンポーネント115、および自然言語モデリングコンポーネント125によって実行されるアクションが含まれています。フローチャート200でのアクションの実行には、ニューラルネットワーク、機械学習、AIモデリングなどの人工知能が使用される場合があります。
ステップ202では、ユーザクエリが取得されます。ユーザクエリは、ユーザシステムデザインコンポーネント135固有のユーザインターフェースを使用するか、コンテンツ生成アプリケーション130のユーザインターフェースを使用して取得される場合があります。
ステップ206では、クエリ理解コンポーネント140がクエリが有効かどうかを判断します。例えば、クエリが理解不能な場合は無効と見なされることがあります。ヒントコンポーネント150は、入力クエリに基づいてユーザにヒントを提供するために使用されます。システムのコンポーネントがユーザが望む結果を得られないと判断した場合、ヒントコンポーネント150がユーザにヒントを提供することがあります。例えば、ユーザの入力がバイアスがかかっていたり、有害であったり、理解不能であったりする場合、自然言語生成モデルの出力が有害であるかバイアスがかかっている場合、またはここで説明されている他のシナリオの場合、ヒントコンポーネント150がトリガーされる可能性があります。関連するヒントが特定できない場合は、一般的なガイドや指示がユーザに提供されることがあります。ヒントコンポーネント150は、ヒントコンポーネント150のトリガーの理由と、ヒントコンポーネント150のトリガーを引き起こしたデータの問題に関する情報をログに記録することがあります。記録された情報は、プロンプト設計コンポーネント115やクエリ理解コンポーネント140などのシステムの他のコンポーネントの改善に使用される場合があります。
ユーザからのクエリが有効である場合、ステップ208ではバイアス検出コンポーネント145が使用され、ユーザクエリにバイアスの可能性があるかどうかが判断されます。つまり、バイアス検出コンポーネント145は、ユーザクエリがバイアス、有害、関連性のない、またはその他の望ましくない出力を生む可能性があるかどうかを判断します。バイアス検出コンポーネント145は、ステップ208の判断のためにバイナリ(バイアス/バイアスでない)の出力を提供する場合があります。バイアス検出コンポーネント145はテキスト(例えば、ユーザクエリまたはモデルからの出力)にスコアを割り当て、そのスコアが閾値を超えることに基づいてステップ208での判断を行う場合があります。バイアス検出コンポーネント145が閾値を超えるバイアスの可能性を判断する場合、例えば、ステップ210で再びヒントコンポーネント150が使用され、より良いユーザクエリの提案やヒントが提供されます。バイアス検出コンポーネント145は、自然言語生成モデルの学習方法に基づいて重要な役割を果たします。前述のように、GPT-3はクリーニングやデバイアス処理がほとんど行われていないフィルタリングされていないテキストデータから学習します。ソースデータのバイアス、有害性、その他の問題は、モデルに引き継がれます。したがって、バイアス検出コンポーネント145は、攻撃的でバイアスのかかった、有害な、またはその他の望ましくない出力を防ぐのに役立ちます。バイアスの可能性が十分に低い場合、クエリ理解コンポーネント140はステップ212で意図検出を実行します。
意図検出には、ユーザクエリの意図を特定することが含まれます。意図検出のステップ212では、データ234からユーザの好みの履歴、現在のデッキのグローバル情報、および/または現在のデッキの編集履歴を使用して意図を特定します。意図検出は、ユーザクエリを自然言語モデリングを使用しないアクション(例:デザインリクエスト)または自然言語モデリングを使用するアクション(例:コンテンツリクエスト)のいずれかに分類します。したがって、クエリ理解コンポーネント140は、ユーザが非自然言語アクション(例:デザインの提案)または自然言語アクション(例:コンテンツの提案)を要求しているかどうかを判断します。ユーザが非自然言語アクションを要求している場合、ステップ214で非自然言語アクションが特定されます。これらのアクションは、コンテンツドキュメントの更新や提案の提供に直接使用することができます。例えば、コンテンツ生成アプリケーション130からのデザインや他のツールを使用して、ステップ216でオプションや新しいデザインやレイアウトを提供することができます。例えば、ユーザクエリが「背景を紫にする」というものである場合、デザインツールはいくつかの紫色の背景オプションを提供する可能性があります。ユーザは、どのオプションを選択するか、またはどのオプションを保持するかを決定ブロック218で選択することができます。ユーザが1つ以上のオプションを保持する場合、ステップ220でコンテンツドキュメントが更新され、システムはステップ202で新しいユーザクエリを待機する状態に戻ります。ユーザがオプションを保持しない場合、ステップ222でヒントコンポーネント150が使用され、ユーザが望む提案を得るためのヒントが提供されます。
図3は、たとえばシステム100を使用してインテリジェントなコンテンツを自動生成するための方法300を示しています。
ステップ305では、ユーザクエリが受信されます。たとえば、ユーザシステムデザインコンポーネントのユーザインターフェースを使用してユーザからクエリを取得することがあります。一部の実施例では、コンテンツデザインアプリケーション130のユーザインターフェースを使用してユーザからクエリを取得することがあります。ユーザクエリは、デザインの提案を要求する、コンテンツの提案を要求する、デザインとコンテンツの提案の組み合わせを要求する、またはその他の要求を含む、任意のリクエストまたはクエリです。クエリ理解コンポーネント(たとえば、クエリ理解コンポーネント140)は、不適切なユーザクエリを除外したり、コンテンツではないか、自然言語アクションを使用するクエリを適切なコンポーネントにルーティングしたりします。自然言語アクションを使用するユーザクエリは、クエリ理解コンポーネントによって特定され、ステップ310でユーザクエリの意図から自然言語アクションが決定されます。アクションのカテゴリが分類され、ユーザクエリ、アクション、および/またはアクションのカテゴリがプロンプトデザインコンポーネント(たとえば、プロンプトデザインコンポーネント115)に提供されます。プロンプトデザインコンポーネントは、決定されたアクションに基づいてステップ315でプロンプトを生成します。
ステップ320では、プロンプトが自然言語生成モデル(たとえば、自然言語生成モデル125)に提供されます(例:GPT-3など)。自然言語生成モデルはモデリングを行い、ステップ325ではモデルからの出力が受信されます。ステップ330では、出力を使用して応答コンテンツがコンテンツ生成アプリケーション(たとえば、ワープロアプリケーション、プレゼンテーション作成アプリケーションなど)と互換性のある形式で生成されます。応答コンテンツは、ユーザが選択するために1つ以上のオプションで提供される提案コンテンツです。ステップ335で応答コンテンツが表示されます。一部の実施例では、ユーザが選択した応答コンテンツでコンテンツドキュメントが更新され、コンテンツ生成アプリケーション130を介して表示されることがあります。
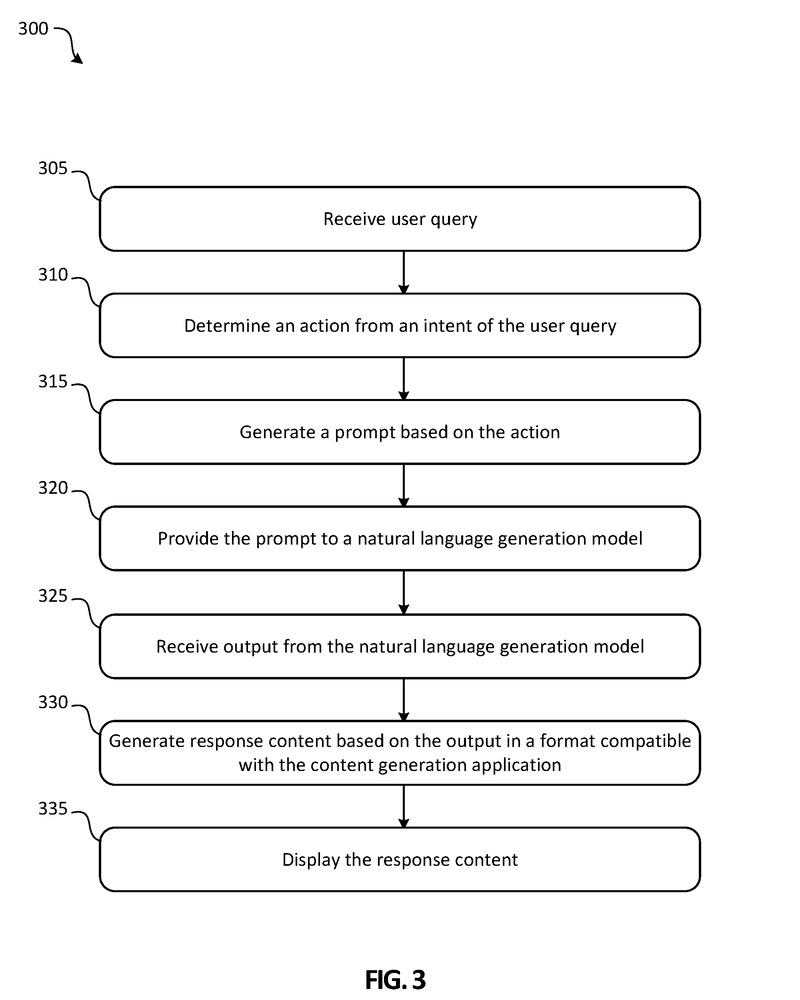
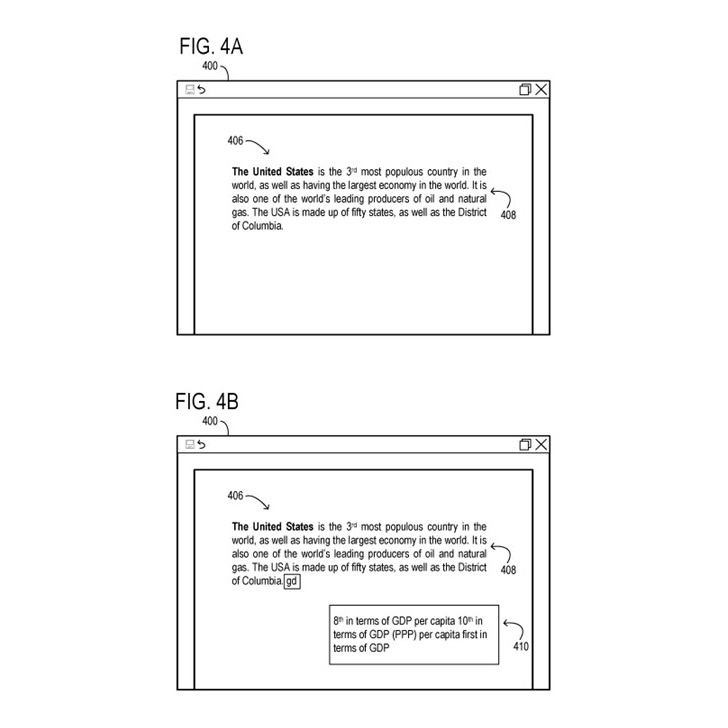
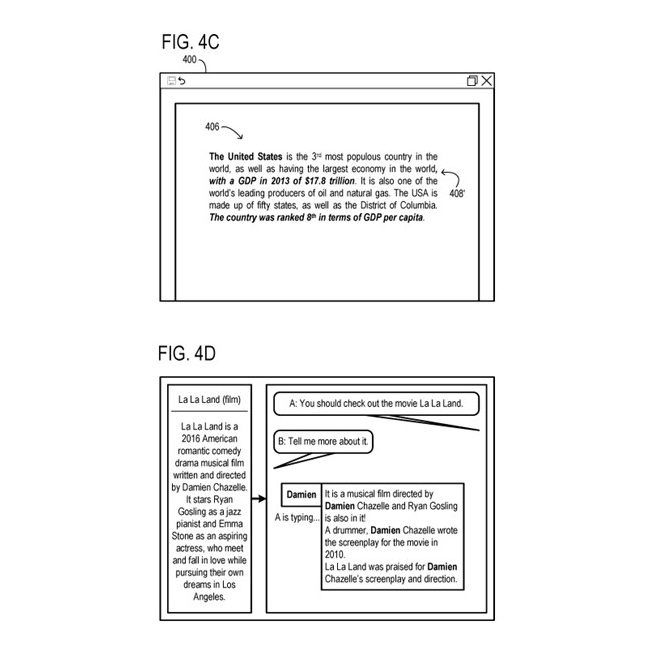
図4は、自動インテリジェントコンテンツ作成システム(たとえば、ユーザシステムデザインコンポーネント135、アプリケーション/サービスコンポーネント110)とのインタフェースに使用される、例示的なユーザインターフェース400を示しています。
ユーザインターフェース400は、ユーザにコンテンツの生成を行うために提供されます。
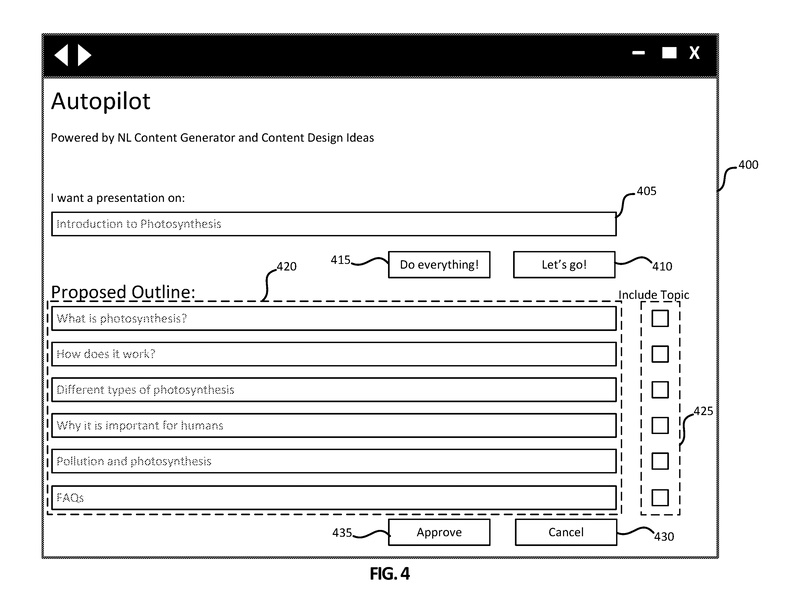
図4-9は、プレゼンテーションを生成するための例示的なユーザインターフェースを示していますが、トピック、オプションの数、レイアウト、デザインなどはすべて例示であり、変更が許容されることが本開示の範囲内で理解されるでしょう。
初期のユーザインターフェース400には、クエリボックス405、すべての操作を行うボタン415、Let’s goボタン410が含まれています。この特定のユーザインターフェース400は、ユーザが「光合成の紹介」としてクエリボックス405に表示されるタイトルに示されるように、MICROSOFT POWERPOINT®などのプレゼンテーション作成アプリケーションと共に使用されることがあります。
ユーザは、クエリボックス405に示されるように「光合成の紹介」と入力し、光合成の紹介を提供するプレゼンテーションを希望することを示します。ユーザがすべての操作を行うボタン415を選択すると、システムはプレゼンテーションを生成してユーザに提供することがあります。図示された例では、ユーザがLet’s goボタン410を選択し、提案された概要が提案セクション420に表示されます。
図5は、図4に示されるように、ユーザが提案された概要トピックと承認ボタン435を選択した後に生成される、例示的なグラフィカルユーザインターフェース500を示しています。
ユーザインターフェース500には、クエリボックス505とそれに関連する送信ボタン510が含まれています。提案オプションセクション525では、ユーザが選択するためにいくつかのタイトルスライドが提示されます。
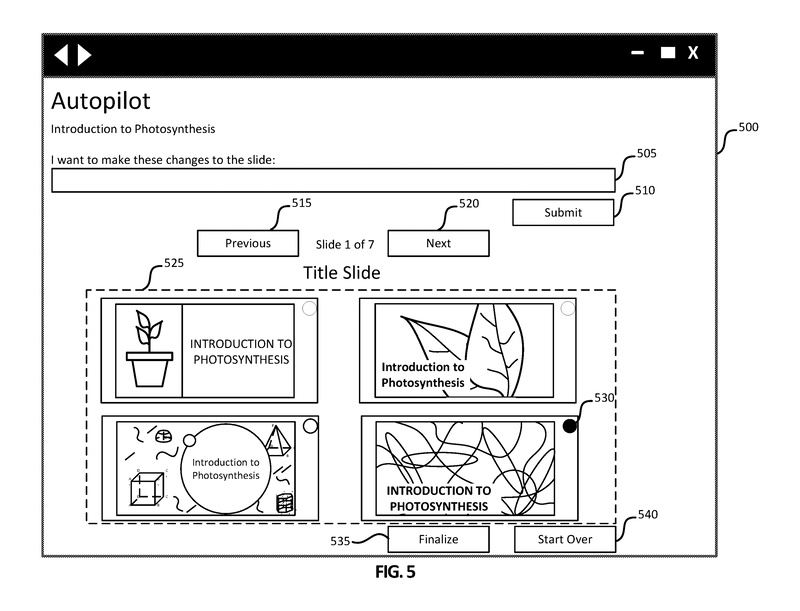
ユーザは、各選択肢の左上隅にあるラジオボタン(ラジオボタン530など)を使用して選択することができます。ユーザが選択したスライドに変更を要求する場合、ユーザはクエリボックス505にリクエストを入力し、送信ボタン510を選択します。クエリボックス505は、ユーザが提案されたオプションのコンテンツやデザインを反復的に更新する手段を提供し、ユーザが少なくとも1つのオプションに十分に満足するまで更新を行うことができます。
ユーザは、前のボタン515と次のボタン520を使用して、各トピックの提案されたオプションをスクロールして閲覧することができます。ユーザインターフェース500に示されているように、ユーザは7つのスライドのうち最初のスライドの提案オプションセクション525を表示しています。ユーザはユーザインターフェース400からすべての6つのトピックを選択しており、ユーザインターフェース500では7番目のスライドがタイトルスライドとして表示されています。ユーザは、ラジオボタン530で選択された右下のコーナーに表示されているスライドなどのオプションを選択し、次のボタン520を選択してオプションを進めることができます。ユーザは、選択済みの選択肢でプレゼンテーションを完成させるために、最終決定ボタン535をクリックすることができます。ユーザは、スタートオーバーボタン540を選択することで、プロセス全体を最初からやり直すことができます。この例では、ユーザはラジオボタン530に関連するスライドを選択し、次のボタン520を選択して続行しています。
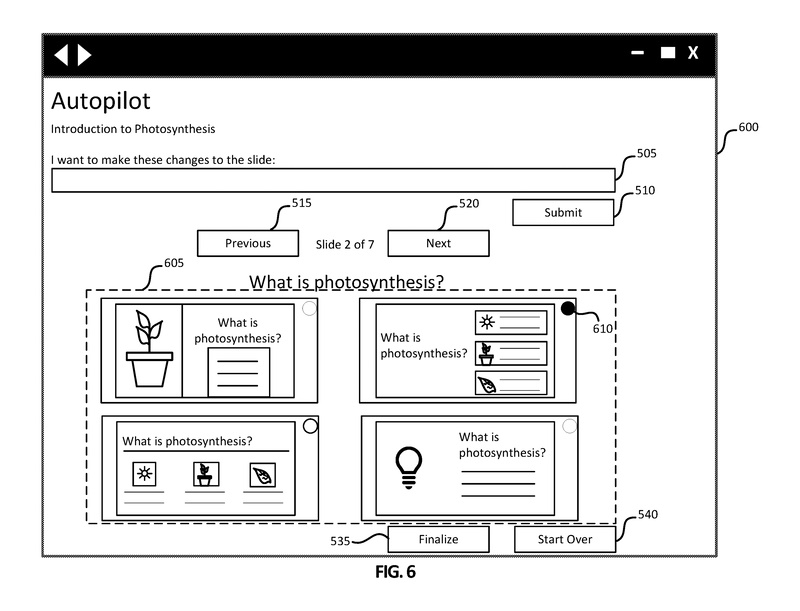
図6は、図5と同様の選択オプションを持つ、別の例示的なグラフィカルユーザインターフェース600を示しています。ユーザインターフェース600には、クエリボックス505、送信ボタン510、戻るボタン515、Nextボタン520、最終決定ボタン535、およびスタートオーバーボタン540が含まれています。
提案セクション605では、ユーザインターフェース500の提案セクション525とは異なる選択肢が提供されます。
図6に示されているように、7つのスライドのうち2番目のスライドのオプションが提案セクション605で選択可能です。さらに、提案されるオプションはスライド間で相関する場合があります。例えば、提案セクション605の左上隅の提案は、図5に示される提案セクション525の左上隅の提案と同様のデザイン、色、レイアウトなどを持つ場合があります。ユーザが各スライドのオプションをナビゲートするときに、一貫したデザインとレイアウトのオプションはユーザの利便性のために同じ順序で表示される可能性があります。この例では、ユーザはラジオボタン610に関連付けられたスライドの提案を選択し、次のボタン520を選択して3番目のスライドのオプションを表示します。
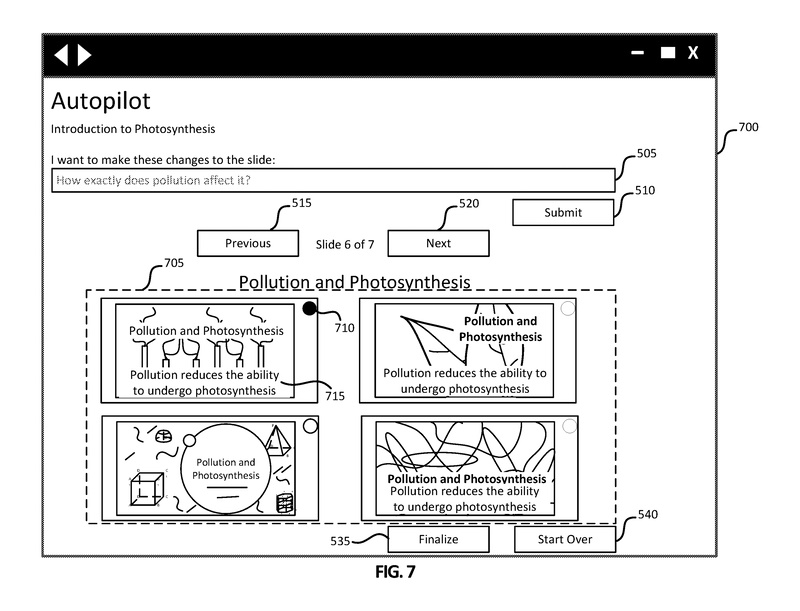
図7は、ユーザが7つのスライドのうち6番目のスライド(汚染と光合成のトピックを持つ)のオプションを表示している、別の例示的なグラフィカルユーザインターフェース700を示しています。提案セクション705には、6番目のスライドのオプションの提案が含まれています。描かれているように、汚染と光合成のオプションには4つのスライドオプションがあり、それぞれに対応するラジオボタンがあります。ラジオボタン710に関連付けられた選択されたスライドのテキストは、テキスト715に示されているように、「汚染は光合成を行う能力を低下させます」と述べています。この例では、ユーザはこのテキスト715が具体的ではないと考え、そのためクエリボックス505を使用して「汚染は具体的にどのように影響を与えるのですか?」と尋ねることができます。
ユーザは次に、クエリボックス505のクエリを提出するために送信ボタン510をクリックすることができます。ユーザの履歴、現在のスライドデッキなどの文脈を使用して、クエリ理解コンポーネントはクエリを処理して自然言語アクションを生成することができます。自然言語アクションは、現在のスライドデッキとユーザの履歴の文脈と共に使用され、プロンプトを設計して自然言語生成モデルに提出します。
出力は、応答コンテンツを生成するために使用され、ユーザインターフェース700は図8に示されるユーザインターフェース800を表示するために更新される場合があります。

図8は、ユーザがクエリボックス505に入力したリクエストの結果を反映させた後、7つのスライドのうち6番目のスライドの更新されたオプションを表示している例示的なグラフィカルユーザインターフェース800を示しています。
ユーザインターフェース800では、テキスト715がテキスト815に更新されて表示されています。「汚染は植物がクロロフィルをより少なく生成する原因です」というテキスト815が表示されています。提案セクション805の各オプションもテキスト815で更新されていますが、選択されたスライドのみが更新される場合もあります。ユーザはラジオボタン810に関連付けられたオプションを選択し、次のボタン520または前のボタン515を選択して、プレゼンテーションの他のトピックのスライドオプションを確認することができます。
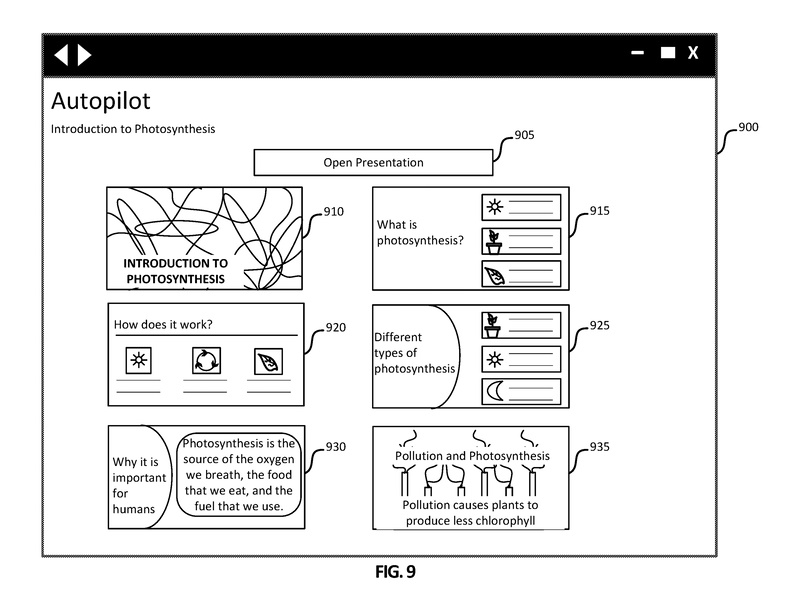
図9は、ユーザが最終化ボタン535を選択した後に生成される例示的なグラフィカルユーザインターフェース900を示しています。
各スライドの選択されたオプションがユーザに表示されます。選択されたオプションを含むコンテンツドキュメントは生成または更新される場合があります。ユーザインターフェース900には、開くボタン905と選択されたスライド910、915、920、925、930、935が含まれています。ユーザインターフェース900には、他の選択されたスライドを表示するために下にスクロールするためのスクロールバーが含まれている場合があります。ユーザが開くボタン905を選択すると、選択されたスライドを含むコンテンツドキュメントがMICROSOFT POWERPOINT®などのプレゼンテーション作成アプリケーションで開かれます。
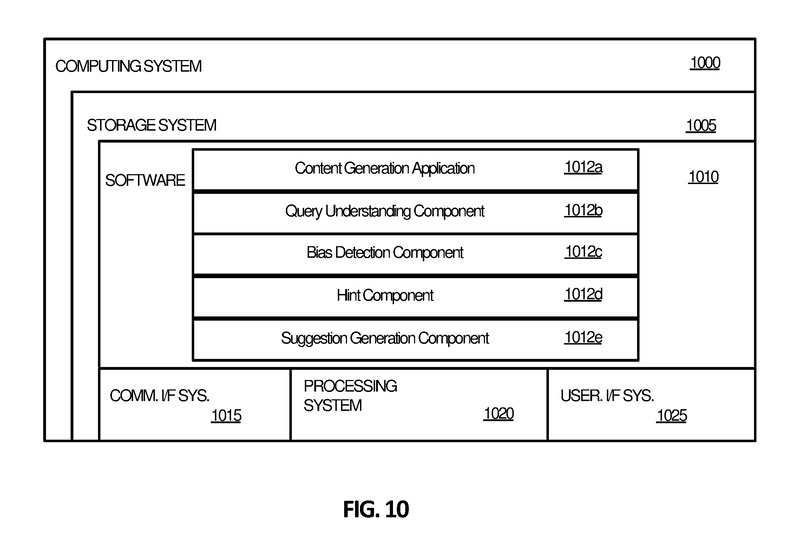
図10は、自動的なインテリジェントコンテンツ生成に関連する処理操作を実装するために適したコンピューティングシステム1000を示しています。コンピューティングシステム1000は、ユーザシステムデザインコンポーネント(例:図1のユーザシステムデザインコンポーネント135、アプリケーション/サービスコンポーネント110、プロンプトデザインコンポーネント115など)を含むなど、いかなるコンポーネントの処理操作も実装するように構成することができます。
したがって、コンピューティングシステム1000は、特定の目的のために構成されたコンピューティングデバイスであり、ユーザの制約されたテキスト入力に基づいてユーザに対してインテリジェントなコンテンツを生成するための処理操作を実行することができるというものになります。
ここがポイント!
本発明の自動インテリジェントコンテンツ生成システムは、コンテンツ生成アプリケーション内でコンテンツを作成するためのユーザクエリを受け取り、ユーザクエリの意図を読み取って、アクションを決定する処理を実行します。このアクションに基づいてプロンプトが生成され、自然言語生成モデルに提供されます。
プロンプトに対して、自然言語生成モデルからの出力が行われ、この出力に基づいて、コンテンツ生成アプリケーションと互換性のある形式でレスポンスコンテンツが生成されます。ユーザは、生成されたレスポンスコンテンツを保持、編集、または破棄することを選択できます。ユーザは、追加のクエリを繰り返すことで、コンテンツドキュメントがユーザの希望するコンテンツを反映するまで繰り返し操作できます。
未来予想
一昔前、作曲ソフトで予め用意されたテンプレートを組み合わせて曲を作っていくというものがありましたが、普段ビジネスで使用するOffice系ソフトウェアでもGPTモデルを活用して資料を自動生成させるようになるのは素晴らしい技術だと感じます。しかし、素晴らしいと感じる反面、自動生成ファイルからは単に紋切り型の同じような資料しか出てこない(肝心の伝えたいことが抜けている)かもしれないという危惧もありますね。また、機密情報の取り扱いなどもより一層の課題になりそうです。
特許の概要
|
発明の名称 |
Automated intelligent content generation |
|
出願番号 |
US17/152193 |
|
公開番号 |
US2022/0229832A1 |
|
特許番号 |
US11494396B2 |
|
優先日 |
2021.1.19 |
|
公開日 |
2022.7.21 |
|
登録日 |
2022.11.8 |
|
出願人 |
Microsoft Technology Licensing LLC |
|
発明者 |
Ji Li 他 |
| 国際特許分類 |
G06N 3/08 |
| 経過情報 |
36のファミリー件数があり、米国、欧州、日本、中国、韓国をはじめとして、各国に出願、特許登録されている。 |