
特許で企業の成長性を見通そう

特許制度は、19世紀から続く産業発展に欠かせない制度の一つです。企業がなぜ特許を取得するかといえば、それは当然、特許権という「独占排他権」を取得したいという願望が主たる理由になります。
一方で、特許権というものは第三者に公開されているものですから、その公開情報をデータベースとして利用して、特許を用いて産業の方向性を予測したり、技術の動向を判断したり、また、個別の企業の開発力を推し量る道具として、古くから活用されてきた面もあります。
今回紹介する特許は、特許情報を用いて、企業の成長率を客観的に算出するものです。特許情報をどのように活用すれば企業の成長度合いが見積もれるのか、詳細に解説していきます。
発明の背景
特許の活用方法として、自社の独占排他権を用いて事業を独占的に有利に進めたり、その独占権を売買したりということが行われていますが、特許権に対しての金銭的価値や、その特許を有している企業の能力(収益力など)を推し量るための手法についても、古くから種々検討されてきました。
特許の評価方法について、従来行われてきた手法としては、大きく「金銭的評価手法」と「相対的評価手法」の2つに大別されます。
金銭的評価手法では、スコアリング利用型DCF法、ブラックショールズモデルなど、様々な手法が用いられてきました。これらの手法は、特許を金銭的、経済的に評価する手法で、特許権譲渡の場面などでの需要が高いのですが、定性分析(スコアリング)に主観が入りやすく、また、すべての特許権を評価しようとすると莫大なコストがかかるという問題点がありました。
一方、相対的評価手法では、特許所有件数、登録率、出願件数、請求項数等を解析する統計的な評価手法や、特許明細書の単語分析、技術系統図などから技術価値を評価する手法が用いられています。これらの手法は、データ中心の評価手法であることから、客観性が担保されやすく、競合他社との相対的な技術力の比較の場面などでその機能を発揮するのですが、評価項目と経済活動(特許権の持つ独占排他力)との因果関係の特定が困難であるなどの問題点がありました。例えば、特許数が多い企業が必ずしも収益力が高いとは限らないことは一般的によく知られていることです。
このような背景に鑑みて、本発明の特許権者である工藤氏は、2009年に企業成長性予測指標算出のための装置、特に特定の企業の競合企業グループ内での位置を算出する発明を出願し、2014年に特許を取得しています。この特許によって算出される「位置」は、スコアリングを使用せずに客観データのみを用いて算出されるものであり、恣意性がなく、客観的かつ数値的に企業の成長性を判断できるという特徴がありました。
(先行技術例)特許5655275号
このような手法を用いて高成長業種に関連の深い技術についての特許力、特にその成長率を各企業について算出することができれば、高成長業種における技術的・特許的観点からの高成長企業を的確に選び出すことが可能となり、所望のテーマに特化したファンドやETFの組成、技術系銘柄の株式指数作成などがたやすくなります。
しかしながら、今や一つの企業が複数の業種に進出していることは珍しくなく、複数の業種にわたって特許を所有しいていることも珍しくありません。したがって、通常の業種分類(東証33業種など)で企業を分類して特許力を評価したとしても、各業種における特許力の正確な評価とはならない、という問題がありました。
このような問題点から、本発明では、特許に関する評価値を算出し、この評価値を、特許を保有する権利者(株式上場企業)ごと、かつ、特許分類と業種分類とを対応付けて得られる特許業種分類ごとに集計し、ここで得られた集計値を時系列で比較することにより、株式上場企業の各特許業種分類における特許力成長率を算出する株式上場企業特許力成長率評価装置を提案することとしました。
どんな発明?
発明の目的
では、本発明の詳細を説明していきます。
まず、基本的な定義の説明からですが、多数の競合他社がひしめき合う事業において広い権利範囲をもった強い特許権を持っているということは、強い独占排他力を持っているということになります。市場において強い独占排他力を持つということは、特許権利者に利益をもたらす源泉を持つということになります。つまり、特許の独占排他力を評価することは、特許の収益力を評価することと同義だと考えられます。
独占排他力の評価方法の考え方
独占排他力を持つ特許によって、特許権利者が事業を独占するためには必ず排除すべき相手が存在します。そこで、その排除すべき相手が独占排他力を持つ障害特許に対してとる行動を考えることとします。
仮に、自社の事業障害となる特許権を発見した場合、どのような行動をとるでしょうか。まずは、その特許権の内容を調べ、そして、ライセンス交渉をするのか、潰しにかかるのか、あるいは設計変更をするのか、といった判断が迫られます。そのとき、特許権に対して何らかのアクションを起こすことになるわけですね。よって、本発明の株式上場企業特許力成長率評価装置は、この特許権に対する第三者からのアクションを評価対象とすることが望ましいと考えられます。
実際に発明がなされてから出願、公開、審査、登録、そして消滅するまでには特許に対して様々なアクションが起こされます。例えば、審査請求、拒絶理由通知、特許査定または拒絶査定、閲覧請求、拒絶査定不服審判、異議申立、無効審判などです。このさまざまなアクションの中で、第三者のアクションとは、特許の審査経過情報を知ることができる閲覧請求や、特許権を無効にするために請求される異議申立、無効審判などです。本発明における株式上場企業特許力成長率評価装置は、このような第三者(競合他社)からのアクションを評価することで特許権の持つ独占排他力を指数化することが可能だ、ということを評価の根拠としています。
このように、評価対象を第三者のアクションのみに限定したのはなぜかといえば、例えば、多くの特許を出願した企業が特許による高い収益力を持つとは決して言えないからです。出願された特許のほとんどが審査請求をせずにみなし取下げになる場合や、審査において拒絶され、特許にならない場合にはたくさん出願をしても意味がないので、評価対象に入れることは妥当ではありません。また、自己のアクションを評価対象に入れると恣意的に自己の評価を変えることが可能となってしまいます。
一方で、競合他社がその存在を無視することができず、調査をしなければならない特許、調査をした結果特許回避をすることが難しいと判断し無効審判を起こして無効にしたいと思うような特許などは価値が高いと言えます。
しかし、例外として、自社による特許評価値を算出したい場合には、評価対象を自社アクションとしてもよいことは当然のことでもあります。この場合は、「出願」という自社のアクションが評価対象に含まれるようになります。さらには、例えば、海外出願(ファミリー出願)をしている特許、拒絶査定不服審判を請求している特許については自社による評価が高い特許であるといえるのだから、これらのアクションも評価の対象に含むべきと考えます。
自社が特許に対してかけたコストに注目し、これを集計すれば、コストアプローチの考えで『自社にとっての特許資産価値』を算出することが可能となります。本発明は、第三者のアクションのみを評価対象とした場合において、もっとも効果が高いと言えますが、自社のアクションのみを評価対象とした場合にも大きな効果をあげることが可能ですし、また、すべてのアクションを評価の対象とすることも考えられます。
では、図面も参照しながら、本発明の詳細について解説していきます。
実施形態
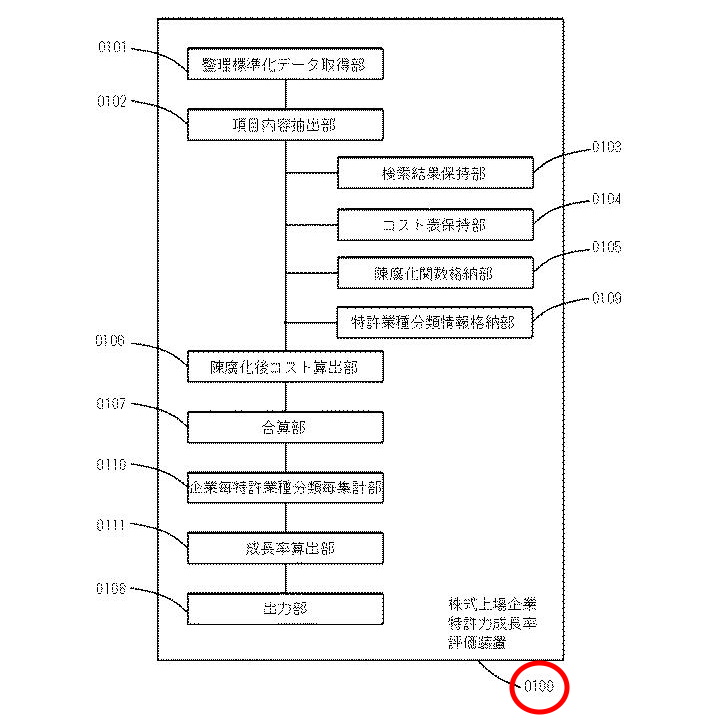 【図1】株式上場企業特許力成長率評価装置の機能ブロック図
【図1】株式上場企業特許力成長率評価装置の機能ブロック図
図1に示す株式上場企業特許力成長率評価装置(0100)は、以下の構成を備えます。
- 「整理標準化データ取得部」(0101)
- 「項目内容抽出部」(0102)
- 「検索結果保持部」(0103)
- 「コスト表保持部」(0104)
- 「陳腐化関数格納部」(0105)
- 「陳腐化後コスト算出部」(0106)
- 「合算部」(0107)
- 「出力部」(0108)
- 「特許業種分類情報格納部」(0109)
- 「企業毎特許業種分類毎集計部」(0110)
- 「成長率算出部」(0111)
いくつか抜粋して解説していきます。
整理標準化データ取得部(0101)
整理標準化データとは、特許庁が保有している審査経過情報等の各種情報を整理標準化して加工したものです。整理標準化データを参照することにより、出願日、出願人、発明者、権利者などの情報や、出願審査請求の有無や審査経過の状況などを知ることが可能です。そして、これら整理標準化データは、例えば特許庁の電子図書館やその他の特許情報サービスによって電子化され提供されているので、ネットワークや各種記録媒体などを介して本株式上場企業特許力成長率評価装置はこれらデータを容易に取得するよう構成することができます。
もちろん、オペレータなどが手入力で、公表されている整理標準化データを入力する構成なども挙げられます。
項目内容抽出部(0102)
取得した整理標準化データに記述されている特許に対して取られた法律的手続きを示す標準項目名称の組合せを、予め準備したパターンを利用したパターンマッチング処理により検索し、検索された標準項目名称の組合せに応じて整理標準化データに記述されている項目内容を、その手続日と関連付けて抽出する機能を有する部分です。
ここで、特許に対して取られた法律的手続とは、例えば閲覧請求や情報提供、異議申立、無効審判などのことをいいます。
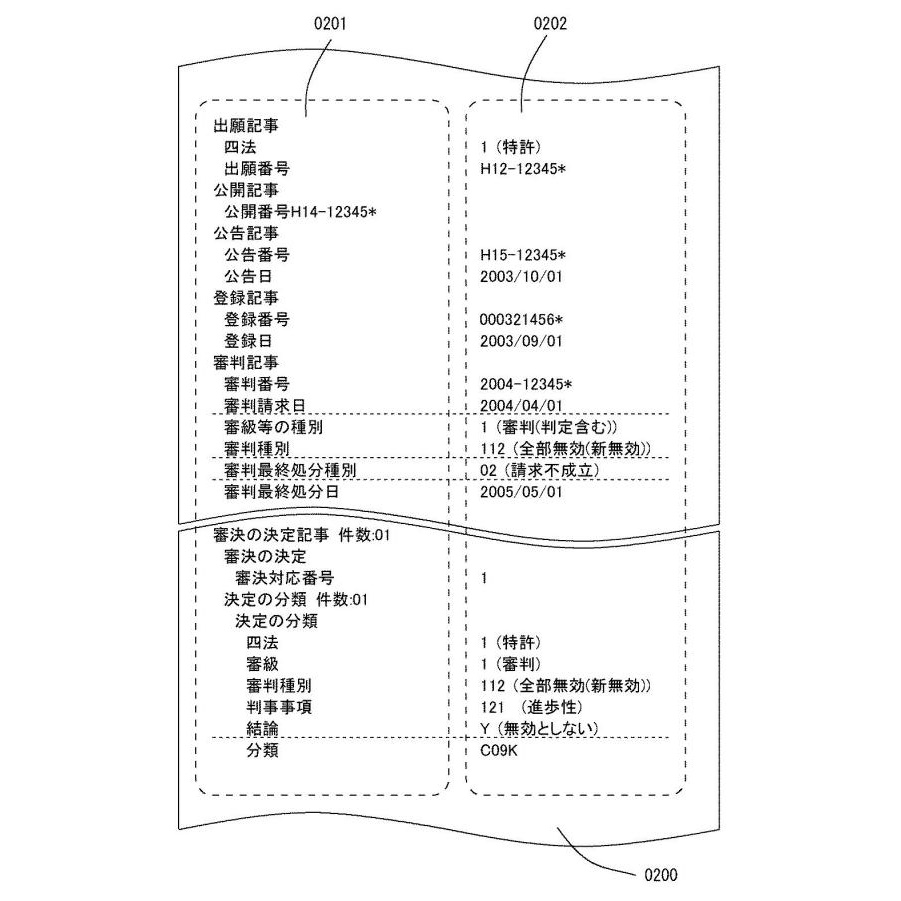 【図2】整理標準化データの例
【図2】整理標準化データの例
コスト表保持部(0104)
標準項目名称の組合せに関連付けて保持されている項目内容の組合せごとに、予め準備されているコストを対応付けたコスト表を保持する機能を有する部分です。
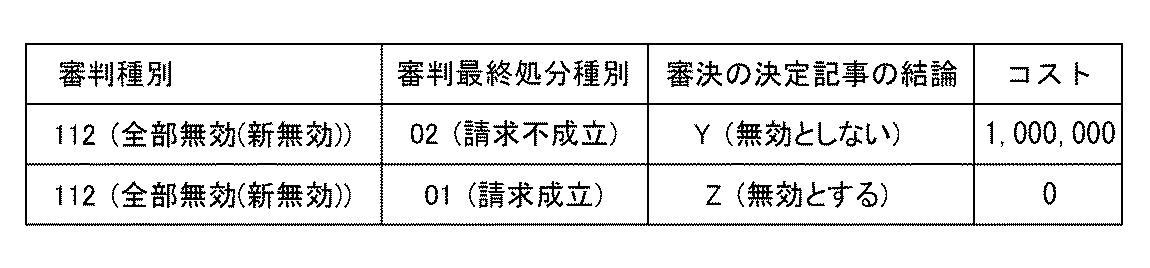 【図3】
【図3】
図3の1行目には、標準項目名称の組合せが示されています。
例えば、無効審判に対する標準項目名称の組合せは、審判種別、審判最終処分種別、審決の決定記事、などです。そして、2行目、3行目には項目内容の組合せの例が示されています。
2行目の例は、無効審判が起きて、最終処分が請求不成立であり、さらに、審決が無効としないというものであった場合です。この場合には、第三者が無効審判にかけたコスト、例えば、1,000,000(百万)円をコストとしてコスト表に保持します。
また、3行目の例は、無効審判が起きて、最終処分が請求成立であり、さらに、審決が無効とするというものであった場合です。この場合には、特許は無効となり、当該特許に価値はないものと考え、コストとしてゼロをコスト表に保持します。
コスト表に記述されているコストは金銭単位であってもよいし、適当な値で割算した値や、その法律手続に対応する指数などであっても良いものとします。
陳腐化関数格納部(0105)
技術分野ごとにその技術の陳腐化の目安となる陳腐化関数を格納するという機能を有する部分です。
陳腐化関数は、例えば次のようにして求めます。
図4上図は、ある技術分野において、出願から何年目に特許権が消滅したかという統計をとったグラフです。縦軸は消滅した特許権の割合で、横軸は出願からの年数です。この統計データは、出願のときを起点としていることがひとつの特徴です。当たり前のことかもしれませんが、技術の陳腐化は権利が登録されたときから始まるのではなく、発明がなされたときをピークに始まるものであると考えられるからです。ゆえに、発明の瞬間を起点とするのが最も正しいと思われますが、その統計をとることはできないので、出願のときを起点とすることとしました。
図4上図を詳しく見てみると、出願から4年目ぐらいまでに消滅する特許権はほぼ0(ゼロ)であり、その後、徐々に消滅する特許権が増えているのが分かります。そして、出願から20年目に登録特許のうち25%〜30%にあたる特許権が消滅します。これは、特許権の存続期間が原則として出願から20年であることによります。もし、存続期間が20年よりも長い場合にはもっと長い期間維持されたであろう特許権が20年目にすべて消滅しているのです。20年目に技術の陳腐化が一気に起こったわけではありません。
そこで、この20年目に消滅した特許権は20年目以降の数年間に渡って徐々に消滅していくものであったとの仮説に則って、図4下図の丸で囲んだような割合で年々消滅していくであろうとの予測をしました。
なお、この20年目に消滅した特許を、計算上21年目以降に消滅したものと仮定するのは補助的な処理にすぎません。この処理は必ずしも行う必要はありませんが、このように少しでも実際の分布を正規分布に近づける下処理を行うことにより、より正確に陳腐化曲線を求めることができると考えられます。もっとも、実際のデータ(図4上図)をそのまま正規分布で近似した方が、より現実に即していると考えることも可能ですので、この処理を行うか否かは適宜判断すべきものといえます。
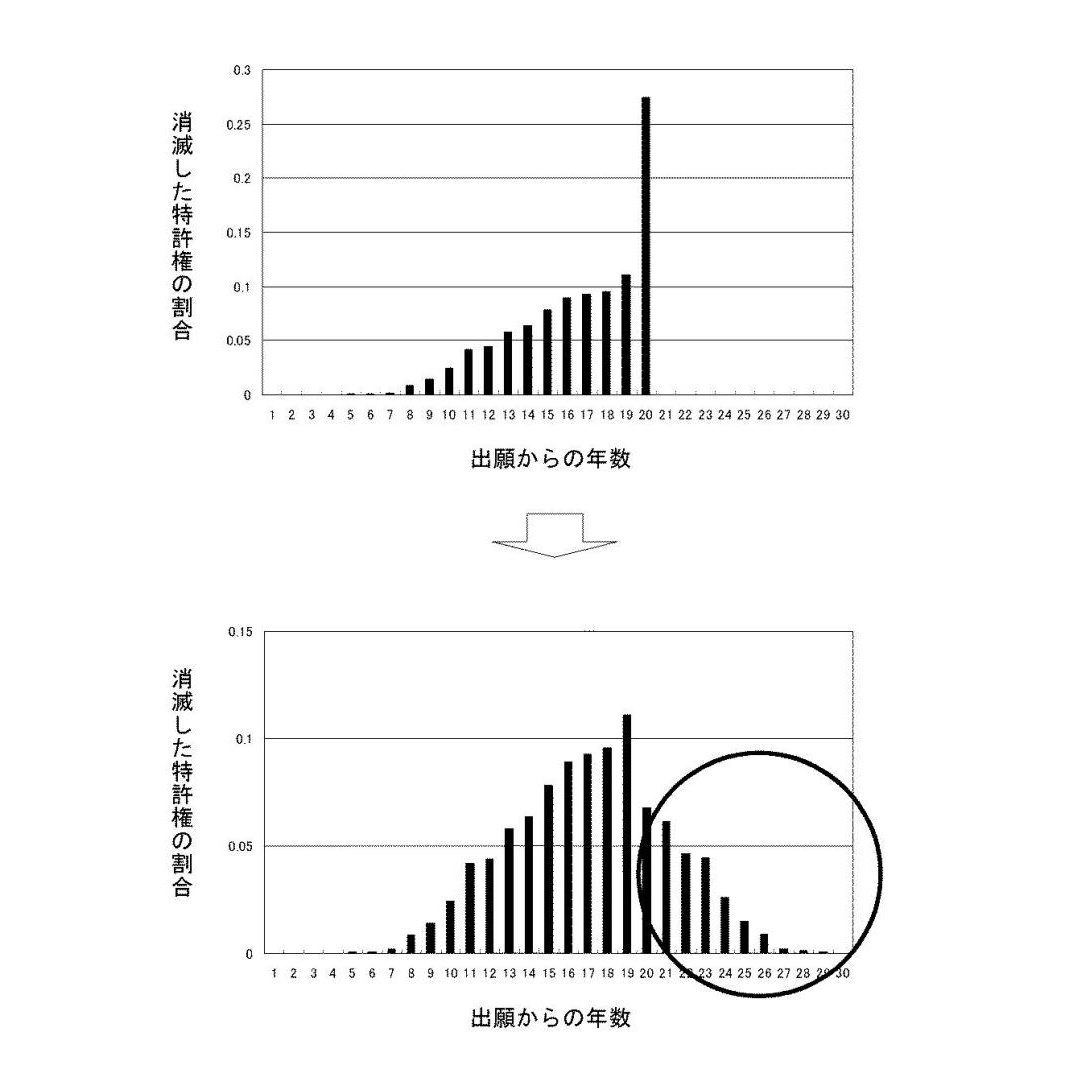 【図4】消滅した特許権の割合
【図4】消滅した特許権の割合
さて、これ以降は、図4下図を用いて説明するものとします。
図4下図を正規分布で近似し、「1−正規累積分布」を計算したものが図5です。この曲線が陳腐化関数ということになります。これは、技術価値陳腐化曲線ということもできます。
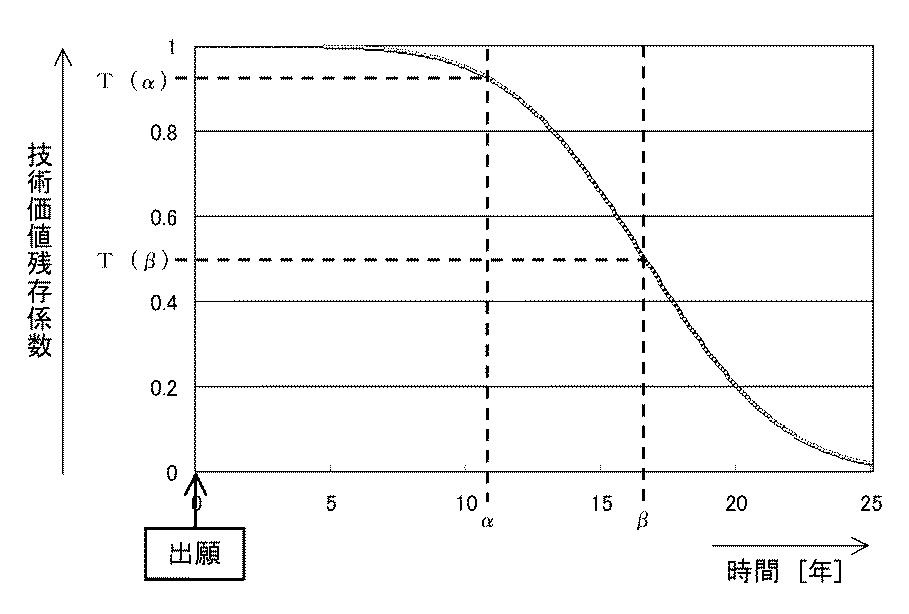 【図5】陳腐化関数
【図5】陳腐化関数
この図によると、存続期間が20年という区切りがないとすれば、出願から25年程度でほとんどすべての特許が維持する価値を失うことになります。このグラフの特徴は、最初の数年間ほとんど陳腐化しないものの、平均的な特許が消滅する年数に近づくにつれてその陳腐化のレートが加速し、平均消滅年数を通過するとまた、陳腐化レートが緩やかになることです。
陳腐化後コスト算出部(0106)
各特許の標準項目名称の組合せに応じて抽出された項目内容の組合せごとに、コスト表保持部に保持されているコスト表を用いてコストを取得するとともに、算定基準日と、その項目内容の組合せごとに関連付けられている手続日と、その特許の出願日と、この特許が属する技術分野の陳腐化関数とを用いて算定基準日における陳腐化後コストを算出する機能を有する部分です。
例えば、ある特許権について、出願からα年目に特許無効審判が請求されたが、維持審決がでたとします。そして、コスト表によるとその一連の手続が100ポイントであったとします。さらに、算定基準日が出願からβ年目であるとします。この場合において、α年の技術価値残存係数をT(α)、β年目の技術価値残存係数をT(β)とおくと、算定基準日における陳腐化後コストは、以下の式で求めることができます。
陳腐化後コスト=100×T(β)/T(α)
算定基準日を現在として考えると、アクション日(α年)が出願から2年で、現在(β年)が出願から3年であれば、ほとんど陳腐化はしないことになります。そして、アクション日(α年)が出願から2年で、現在(β年)が出願から15年であれば、陳腐化は大きいことになります。つまり、昔に起きた法律的手続きであるほど現在における陳腐化後コストに引き直すと小さい値となるわけです。
このようにして算出したコストを、各特許について全て合算し、特許分類ごとに整理します。特許分類としては、全世界の特許を同一の基準で業種と対応づけられる、IPCを使うことが最も望ましいでしょう。本発明の明細書においては、発明者が独自に作成した「YKS分類」が使われていますが、これに限定する必要はありません。
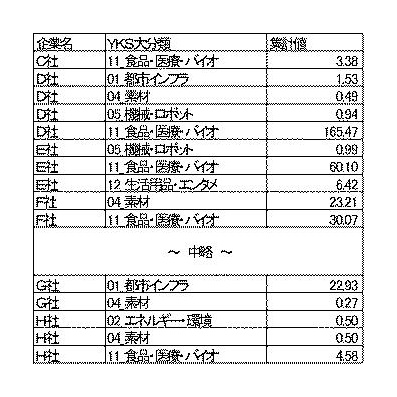 【図21】整理標準化データに記録された特許の特許力の集計例
【図21】整理標準化データに記録された特許の特許力の集計例
このような「特許力」を集計値として算出し、これを2以上の異なる時点における同一の企業の数値と比較すると、「企業毎特許業種分類毎集計値成長率」を算出することが可能となります。
<実施形態1>
図9に、実施形態1としての株式上場企業特許力成長率評価装置の動作方法の処理の流れを記載します。
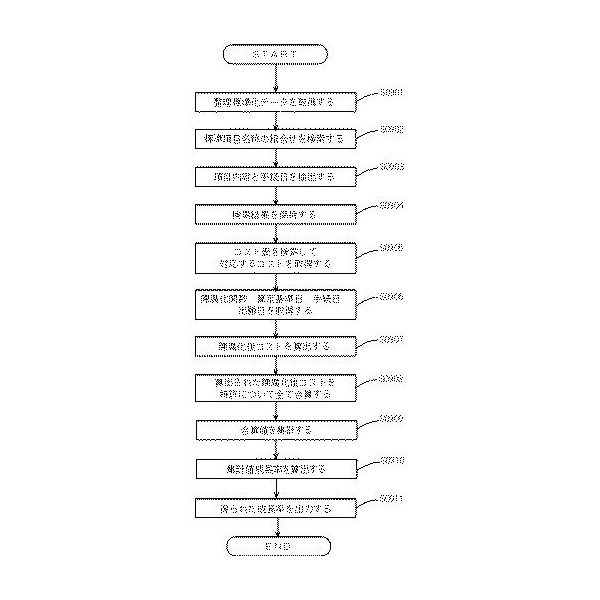 【図9】
【図9】
【ステップS0901】
整理標準化データを例えばネットワーク上の情報提供サーバ装置や入力デバイスからの入力情報などを介して取得します。
【ステップS0902】
前記取得した整理標準化データを対象として、予め準備したパターンを利用したパターンマッチング処理をCPUなどの演算処理により実行し、法律的手続きを示す標準項目名称の組合せを検索します。
【ステップS0903】
整理標準化データから検索された標準項目名称の組合せに応じて項目内容をその手続日と関連づけて抽出します。
【ステップS0904】
抽出された項目内容およびそれに関連付けられている手続日を標準項目名称の組合せに関連付けて、各種記録装置に記録、保持します。
【ステップS0905】
前記抽出保持されている項目内容をキーとして予め準備されているコスト表をCPUなどの演算処理により検索して、その項目内容に対応するコストを取得します。
【ステップS0906】
特許が属する技術分野に対応して予め準備されている陳腐化関数を取得します。また前記取得した整理標準化データや前記記録装置に記録されたデータから算定基準日、手続日、出願日を取得します。
【ステップS0907】
取得したコスト、陳腐化関数、算定基準日、手続日、出願日を利用したCPUの演算処理によって各項目に係る陳腐化後コストを算出します。
【ステップS0908】
算出された各項目の陳腐化後コストを特許について全て合算するCPUの演算処理を実行します。また、その他の特許に関しても同様にCPUの演算処理によって合算値を算出します。
【ステップS0909】
特許ごとに得られた合算値を、特許権利者ごとに、かつ、各特許に付された特許分類に対応付けられた特許業種分類ごとに集計し、企業毎特許業種分類毎集計値とします。なお、ステップS0910において企業毎特許業種分類毎集計値成長率を算出するために、2以上の異なる時点における整理標準化データを用いるなどして、2以上の異なる時点における企業毎特許業種分類毎集計値を得ておきます。
【ステップS0910】
ステップS0909で得られた2以上の異なる時点における企業毎特許業種分類毎集計値を比較することにより(例えば、新しい時点の当該集計値を古い時点の当該集計値で除することにより)、企業毎特許業種分類毎集計値成長率を算出します。
【ステップS0911】
得られた企業毎特許業種分類毎集計値成長率を、例えばディスプレイへ出力表示したり、プリンター装置から印刷出力したり、フラッシュメモリなどに記録出力したりします。
<実施形態1で得られる効果>
実施形態1のような株式上場企業特許力成長率評価装置によれば、以下のような特許群の経済的評価を行なうことができます。
これまでは、特許1件ごとの経済的価値をミクロ評価するために莫大な費用(例えば、1件当たり300万円程度)と時間を必要としていたので、特許群の経済的価値のミクロ評価は難しいとされていました。ここでいうミクロ評価とは1件の特許に対して詳細な調査を行い、その経済的価値を算出することです。本実施形態では、第三者が障害特許を調査し自己の事業への障害度合いを評価した結果起こしたアクションを評価対象としているので、第三者のミクロ評価の結果を間接的に評価していることになります。第三者の感じる事業障害度合いが経過情報に散りばめられており、それを評価対象としているのでマクロ評価でありながら解像度の高いデータになっています。
よって、本発明によって、算出される特許当たりの合算値は、スコアリングを利用せずに客観データのみを用いて算出されたものであるので、恣意性を完全に排除しているという特徴を持ちます。
そして、そのような特徴を有する合算値を、特許権利者毎かつ特許業種分類ごとに集計し、その集計値の成長率を算出することにより、極めて精緻かつ客観的に、各特許権利者の、各業種に関わりの深い分野の特許力の成長率を把握することができます。これにより、高成長業種における技術的および特許的観点からの高成長企業を把握することができるようになるのです。
<実施形態2>
実施例1で求められた、企業成長率の算出を行った後、さらに技術的および特許的観点からの高成長企業を選定し、出力することを特徴とする実施例です。
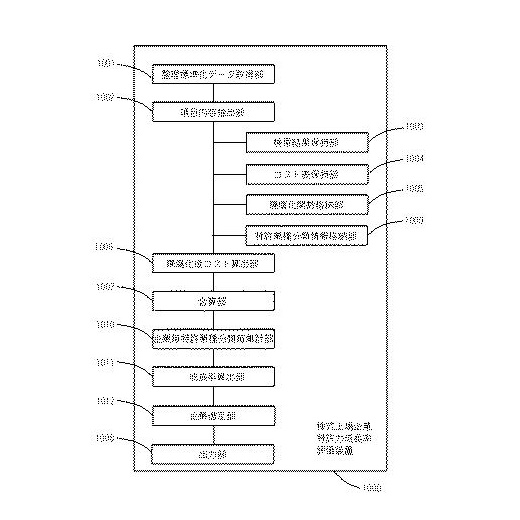 【図10】実施例2の機能ブロック図
【図10】実施例2の機能ブロック図
図10に示す株式上場企業特許力成長率評価装置(1000)は、以下の構成を有するものです。
- 「整理標準化データ取得部」(1001)
- 「項目内容抽出部」(1002)
- 「検索結果保持部」(1003)
- 「コスト表保持部」(1004)
- 「陳腐化関数格納部」(1005)
- 「陳腐化後コスト算出部」(1006)
- 「合算部」(1007)
- 「出力部」(1008)
- 「特許業種分類情報格納部」(0109)
- 「企業毎特許業種分類毎集計部」(1010)
- 「成長率算出部」(1011)
- 「企業選定部」(1012)
「企業選定部」は、企業毎特許業種分類毎集計値成長率が上位である企業を選定することに特徴があります。もっとも単純な選定の条件としては、各特許業種分類に属する企業のなかで、成長率が「上位20社」に含まれる企業や、「上位10%以上のグループ」に属する企業など、上位の一定以上に含まれることのみを選定条件として企業を選定する方法でありますが、さらにさまざまな条件を付すことが可能です。
というのも、成長率には、絶対値として成長した値が同じでも、元の値が小さいほど大きな率として算出されてしまうという性質があるからです。すなわち、極端な例を挙げれば、企業Aの「環境・エネルギー」分野における、ある過去の時点の値が0.1点であり、現在の値が1点である場合、わずか0.9点の成長幅であるにも関わらず、成長率は+900%と、極めて高い値に計算されてしまうのです。これは成長率の計算結果としては間違っていませんが、「環境・エネルギー」分野の集計値の平均値が、100点ぐらいだとすると、わずか0.1点が1点に伸びた企業を「環境・エネルギー」分野の技術高成長企業とみなすことは妥当ではないということになります。
そこで、「企業選定部」では、例えば、成長後の企業毎特許業種分類毎集計値が50点以上の企業のみを選定対象の母集団とする、などの条件を付することができることとしています。
<実施形態2:処理の流れ>
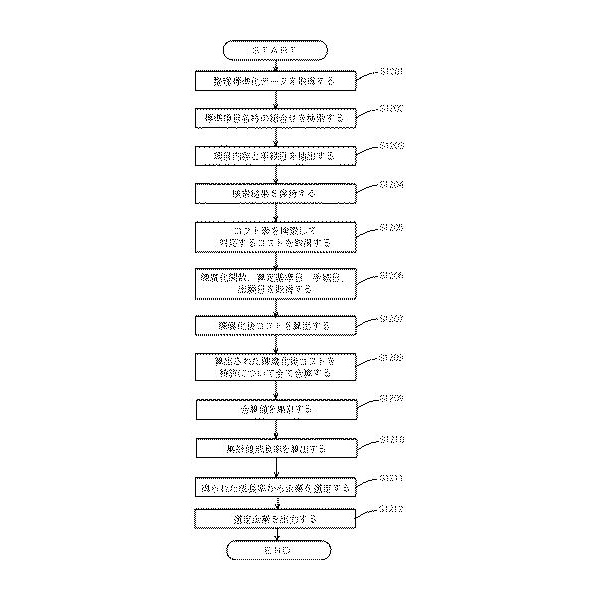 【図12】
【図12】
最初に、ステップS1201において、整理標準化データを例えばネットワーク上の情報提供サーバ装置や入力デバイスからの入力情報などを介して取得します。
次に、ステップS1202において、前記取得した整理標準化データを対象として、予め準備したパターンを利用したパターンマッチング処理をCPUなどの演算処理により実行し、法律的手続きを示す標準項目名称の組合せを検索します。
ステップS1203において、整理標準化データから検索された標準項目名称の組合せに応じて項目内容をその手続日と関連づけて抽出します。
ステップS1204において、抽出された項目内容およびそれに関連付けられている手続日を標準項目名称の組合せに関連付けて、各種記録装置に記録、保持します。
ステップS1205において、前記抽出保持されている項目内容をキーとして予め準備されているコスト表をCPUなどの演算処理により検索して、その項目内容に対応するコストを取得します。
ステップS1206において、特許が属する技術分野に対応して予め準備されている陳腐化関数を取得します。また、前記取得した整理標準化データや前記記録装置に記録されたデータから算定基準日、手続日、出願日を取得します。
ステップS1207において、取得したコスト、陳腐化関数、算定基準日、手続日、出願日を利用したCPUの演算処理によって各項目に係る陳腐化後コストを算出します。
ステップS1208において、算出された各項目の陳腐化後コストを特許について全て合算するCPUの演算処理を実行します。
ステップS1209において、特許ごとに得られた合算値を、特許権利者ごとに、かつ、各特許に付された特許分類に対応付けられた特許業種分類ごとに集計し、企業毎特許業種分類毎集計値とします。なお、ステップS1210において企業毎特許業種分類毎集計値成長率を算出するために、2以上の異なる時点における整理標準化データを用いるなどして、2以上の異なる時点における企業毎特許業種分類毎集計値を得ておきます。
ステップS1210においては、ステップS1209で得られた2以上の異なる時点における企業毎特許業種分類毎集計値を比較することにより(例えば、新しい時点の当該集計値を古い時点の当該集計値で除することにより)、企業毎特許業種分類毎集計値成長率を算出します。
ステップS1211において、S1210で得られた企業毎特許業種分類毎集計値成長率が上位である企業を選定します。
最後に、ステップS1212において、得られた選定企業を、例えばディスプレイへ出力表示したり、プリンター装置から印刷出力したり、フラッシュメモリなどに記録出力したりします。
<実施形態2で得られる効果>
実施形態2に掛かる株式上場企業特許力成長率評価装置によっても、実施形態1と同様にスコアリングを利用せずに客観データのみを用いて算出された合算値を、特許権利者毎かつ特許業種分類ごとに集計し、その集計値の成長率を算出することにより、極めて精緻かつ客観的に、各特許権利者の、各業種に関わりの深い分野の特許力の成長率を把握することができます。さらには当該成長率をもとに、さまざま条件を付して成長率上位の企業を選定することにより、さまざま目的に応じた技術的および特許的観点からの高成長企業を選定することができるようになります。
<実施形態3>
この実施形態では、実施形態2と同様に、算出された成長率を用いて、技術的および特許的観点からの高成長企業を選定します。そして、選定された株式上場企業のある時点における時価総額又は株価を基準として、他の時点における相対値である特許力高成長銘柄指数を算出し、出力することを特徴とします。
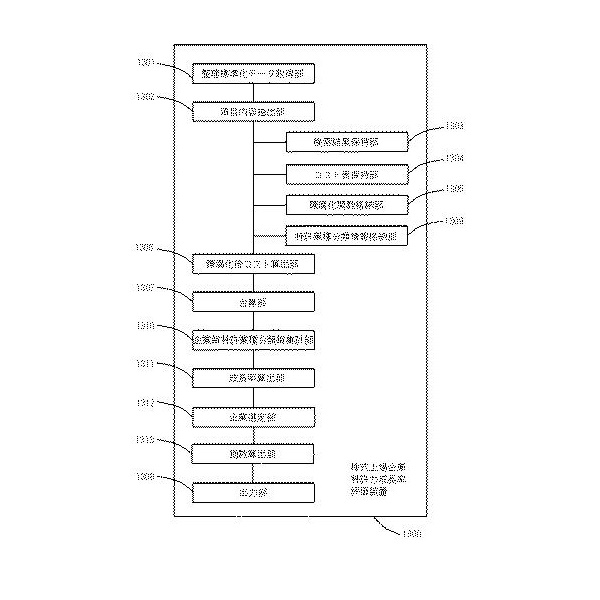 【図13】実施形態3の機能ブロック図
【図13】実施形態3の機能ブロック図
図13に示す株式上場企業特許力成長率評価装置は、以下の構成を有します。
- 「整理標準化データ取得部」(1301)
- 「項目内容抽出部」(1302)
- 「検索結果保持部」(1303)
- 「コスト表保持部」(1304)
- 「陳腐化関数格納部」(1305)
- 「陳腐化後コスト算出部」(1306)
- 「合算部」(1307)
- 「出力部」(1308)
- 「特許業種分類情報格納部」(1309)
- 「企業毎特許業種分類毎集計部」(1310)
- 「成長率算出部」(1311)
- 「企業選定部」(1312)
- 「指数算出部」(1313)
<実施形態3:処理の流れ>
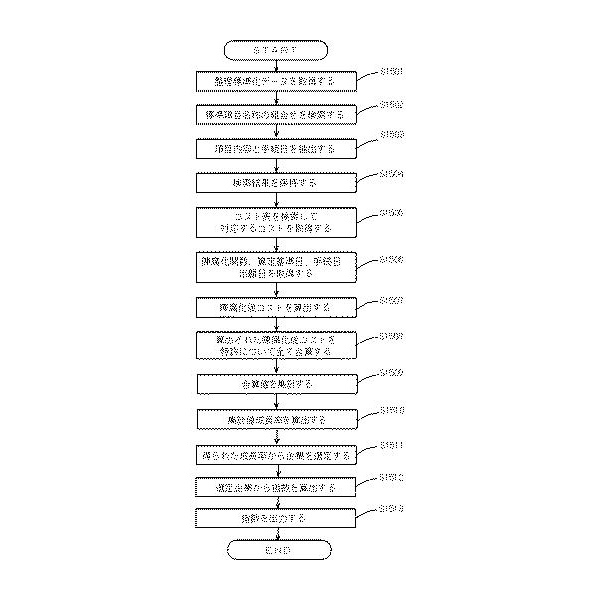 【図15】動作方法の処理の流れ
【図15】動作方法の処理の流れ
最初に、ステップS1501において、整理標準化データを例えばネットワーク上の情
報提供サーバ装置や入力デバイスからの入力情報などを介して取得します。
ステップS1502において、前記取得した整理標準化データを対象として、予め準備したパターンを利用したパターンマッチング処理をCPUなどの演算処理により実行し、法律的手続きを示す標準項目名称の組合せを検索します。
ステップS1503において、整理標準化データから検索された標準項目名称の組合せに応じて項目内容をその手続日と関連づけて抽出します。
ステップS1504において、抽出された項目内容およびそれに関連付けられている手続日を標準項目名称の組合せに関連付けて、各種記録装置に記録、保持します。
ステップS1505において、前記抽出保持されている項目内容をキーとして予め準備されているコスト表をCPUなどの演算処理により検索して、その項目内容に対応するコストを取得します。
ステップS1506において、特許が属する技術分野に対応して予め準備されている陳腐化関数を取得します。また前記取得した整理標準化データや前記記録装置に記録されたデータから算定基準日、手続日、出願日を取得します。
ステップS1507において、取得したコスト、陳腐化関数、算定基準日、手続日、出願日を利用したCPUの演算処理によって各項目に係る陳腐化後コストを算出します。
ステップS1508において、算出された各項目の陳腐化後コストを特許について全て合算するCPUの演算処理を実行します。
ステップS1509において、特許ごとに得られた合算値を、特許権利者ごとに、かつ、各特許に付された特許分類に対応付けられた特許業種分類ごとに集計し、企業毎特許業種分類毎集計値とします。なお、ステップS1510において企業毎特許業種分類毎集計値成長率を算出するために、2以上の異なる時点における整理標準化データを用いるなどして、2以上の異なる時点における企業毎特許業種分類毎集計値を得ておきます。
ステップS1510においては、ステップS1509で得られた2以上の異なる時点における企業毎特許業種分類毎集計値を比較することにより(例えば、新しい時点の当該集計値を古い時点の当該集計値で除することにより)、企業毎特許業種分類毎集計値成長率を算出します。
ステップS1511において、S1510で得られた企業毎特許業種分類毎集計値成長率が上位である企業を選定します。
ステップS1512において、S1511で選定された株式上場企業のある時点における時価総額又は株価を基準として他の時点における相対値である特許力高成長銘柄指数を算出します。
最後に、ステップS1513において、得られた指数を、例えばディスプレイへ出力表示したり、プリンター装置から印刷出力したり、フラッシュメモリなどに記録出力したりします。
<実施形態3で得られる効果>
実施形態3によっても、実施形態1と同様にスコアリングを利用せずに客観データのみを用いて算出された合算値を、特許権利者毎かつ特許業種分類ごとに集計し、その集計値の成長率を算出することにより、極めて精緻かつ客観的に、各特許権利者の、各業種に関わりの深い分野の特許力の成長率を把握することができます。
また、実施形態2と同様に、当該成長率をもとに、さまざま条件を付して成長率上位の企業を選定することにより、さまざま目的に応じた技術的および特許的観点からの高成長企業を選定することができるようになります。
さらには、このように選定された企業から構成される株式投資などに好適な指数を作成することができます。例えば高成長分野である「環境」や「バイオ」をテーマとしたファンドやETFの組成、技術系銘柄の株式指数作成などを、容易かつ客観的なデータのみに基づいて行うことが可能となるのです。
ここがポイント!
本発明は、従来の特許を用いた企業の評価方法(金銭的評価手法や相対的評価手法)とは異なり、特定の業種に関連の深い特許の特許力、特にその成長率などを用いて企業の成長度合いを客観的に評価できる点が優れたポイントです。
特に、第三者のアクションを評価の対象として限定する点で、自社をよく見せよう、といった恣意が入らないところに、評価手法の信頼性が担保されていると考えられます。
未来予想
特許制度は新しい技術を所定の期間、国が独占排他権の保持・行使を「特別に許す」ものですが、同時に、これまで積み上げられたきた特許情報は、いわゆるビッグデータともいえる膨大な技術情報の塊でもあります。
このようなビッグデータのデータベースを、コンピュータ解析によってさらに役に立つ情報へと変換して活用することは、今後どんどん開発・発展していくものと考えられます。これまでは企業の持つ力を判断するのに株価などの少ない情報しかなかったものが、今後は特許をも含めた多面的な企業力の判断が可能となってくることでしょう。
本発明は、すでに「特許価値評価WEBサービス(https://www.patware.net/)」としてリリースがされており、「PATWARE(パットウェア)」という名称のシステムとして実用化されています。
このようなツールを活用することによって、これまで技術開発の面で活用されることが多かった特許が、金融機関や投資家が活用しやすい形に変われば、企業経営の考え方も根本的に変化していくかもしれませんね。
特許の概要
|
発明の名称 |
株式上場企業特許力成長率評価装置、株式上場企業特許力成長率評価装置の動作方法及び株式上場企業特許力成長率評価プログラム |
|
出願番号 |
特願2014-107741 |
|
公開番号 |
特開2015-225357 |
|
特許番号 |
特許第6448078号 |
|
出願日 |
2014.5.26 |
|
公開日 |
2015.12.14 |
|
登録日 |
2018.12.14 |
|
審査請求日 |
2017.5.25 |
|
出願人 |
工藤 一郎 |
|
発明者 |
工藤 一郎 他 |
| 国際特許分類 |
G06Q 50/18 (2012.01) |
|
経過情報 |
・進歩性違反で一旦拒絶されたが、補正を行い、特許査定となった。 |
 【図1A】
【図1A】 【図2】
【図2】 【図3】
【図3】 【図4】
【図4】 【図5】
【図5】 【図6】
【図6】 【図7】
【図7】 【図8】
【図8】 【図9】
【図9】 【図10】
【図10】 【図11】
【図11】 【図1】
【図1】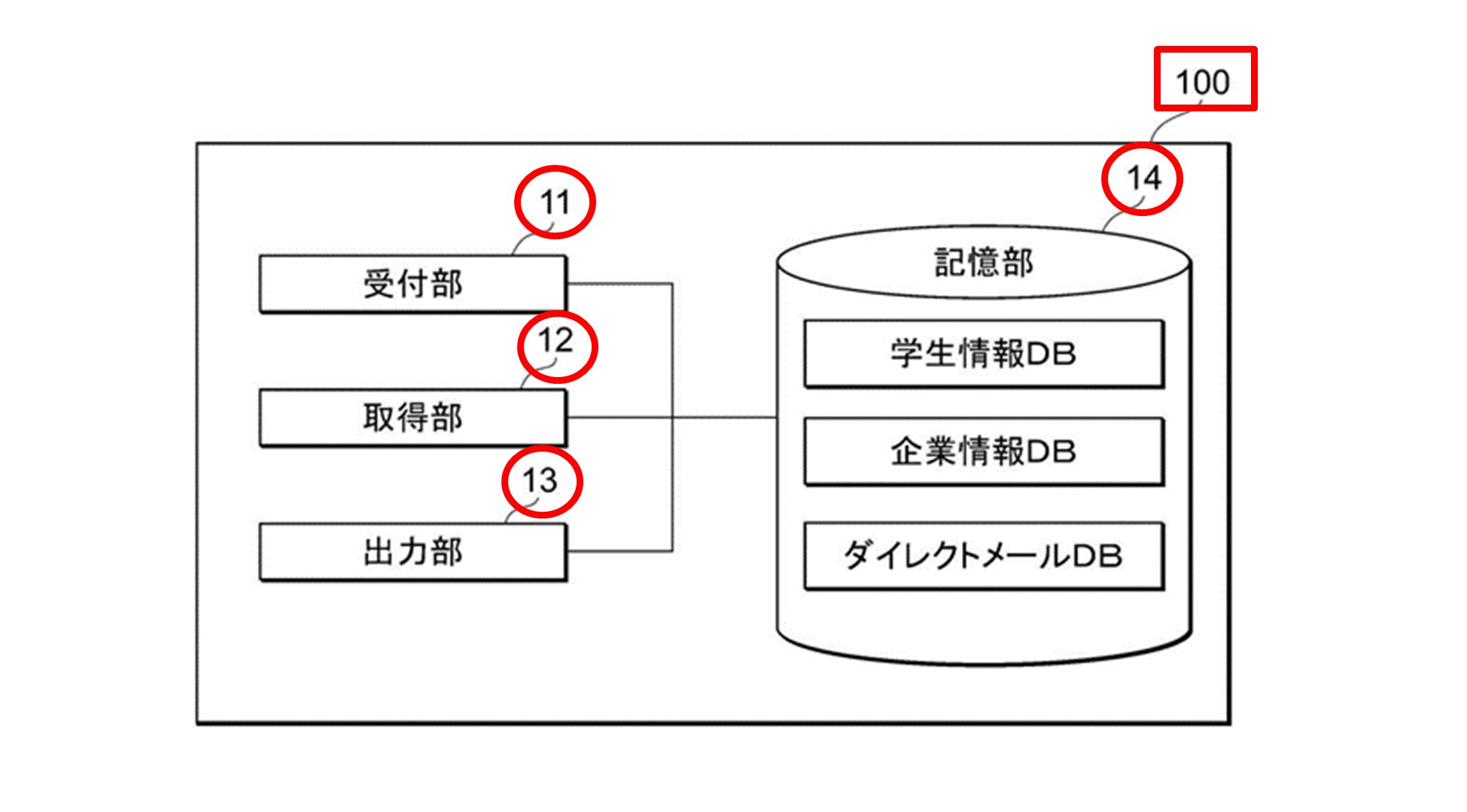 【図2】
【図2】 【図3】
【図3】 【図4】
【図4】