在庫物品管理
商品の移動を検出してレジの行列解消?
現在の電子商取引においては、配送センターの在庫を管理し、顧客が商品を注文すると、ピッカーにより在庫から商品が選択され、梱包ステーションで梱包され、顧客のもとへ出荷されるのが一般的な流れです。実店舗においても、顧客がアクセスできる場所(ショッピングエリア)の在庫をそれぞれ維持管理し、顧客は店舗内で商品を探し、購入のためにレジへ運んでいくという点で、商品の流れは同様といえます。
しかし、どちらの店舗形態でも、ピッカーや顧客が商品を取得するために、最初にその商品を探索しなければならないという問題点があります。
そこで、商品を在庫場所に配置する際、及び、除去する際に、商品リストの更新を自動で行わせることとしました。 例えば、ピッカーや顧客の手をカメラで常に撮影し、手が在庫場所に入る前の画像と、在庫場所を出た後の画像を比較することで、商品を在庫場所に配置したかどうかを判断します。これに基づいて、在庫リストを更新していけるわけです。
逆に、このシステムを応用すると、実店舗において顧客が商品を購入する場合に、商品をカートやバッグ、ポケットに商品を入れ、顧客が店舗を出た段階で、レジでの精算を経ることなく、顧客に代金を請求できることになります(もちろん事前に顧客登録等が必要となりますが)。
このような技術がスーパーマーケットなどの小売店にも採用されれば、長いレジ待ちの列に並んでイライラすることもなくなるかもしれませんね。在庫物品を管理する物流システムに関して、すでに特許となった特許出願をご紹介します。
今回ご紹介する特許出願は、アメリカで出願された特許出願を基にして国際特許出願(PCT出願)され、その後、日本へ移行してきた出願です。この出願(親出願)は審査されたものの特許になっていません。しかし、分割出願された本特許出願(子出願)が以下の通り特許となりました。
このように、アメリカの出願人によって出願されて特許となった内容についてご紹介します。
■従来の課題
従来、小売業者や卸売業者は、顧客の購入や取引先の注文に伴って変動する物品の在庫を管理しています。
例えば、電子商取引(ネット販売)で物品が注文されると、注文された物品は、在庫のなかから選ばれて取り出され、梱包ステーションに送られて、梱包され、出荷されます。同様に、実店舗での販売で購入される物品は、店舗の在庫のなかから選択され、顧客がレジまで持って行って購入されます。
一般的に、在庫は、倉庫または配送センターで管理されます。しかし、在庫のなかからどれだけの物品が取り出され(搬出され)、一方で、どれだけの物品が供給(搬入)されたかを管理することは、非常に手間がかかるため、めんどうな作業です。また、在庫の数を正確に管理することは困難です。
本発明は、上記の問題に鑑みてなされたものであり、在庫場所において物品の取り出しまたは供給を追跡するコンピュータシステムと、物品の追跡方法を提供することを目的とします。
■本発明の効果
本発明は、画像処理などを利用して在庫物品を管理するためのコンピュータシステム、および、その方法に関するものです。本発明では、人による手間を省いて、正確に物流管理できます。
■特許請求の範囲のポイントなど
本発明の特許請求の範囲における概要を説明します。本発明のコンピュータシステムは、在庫場所からの物品の取り出しと供給を追跡するシステムです。
詳細は、後で詳細にご説明しますが、本発明によって、手作業による在庫管理を省いて、ほぼ自動的に在庫管理することができます。
具体的には、ユーザが、在庫場所から物品を取り出し、取り出しが検出されると、取り出された物品が識別され、ユーザ物品リストが更新されます。ユーザ物品リストは、取り出したユーザにあらかじめ紐づけ(関連付け)されています。
例えば、ユーザが物品を搬出する担当者である場合、その搬出担当者のユーザ物品リストは、在庫場所から搬出するあらゆる物品を識別するために紐付け(関連付け)されています。搬出担当者が物品を取り出すと、その物品が識別され、搬出担当者がその物品を取り出したことを記録として残すために、ユーザ物品リストが更新されます。
反対に、ユーザが、在庫場所に物品を供給した場合、上記と同様に、物品が識別され、そのユーザにあらかじめ紐づけされたユーザ物品リストが更新されます。
例えば、ユーザが搬入担当者である場合、搬入担当者のユーザ物品リストは、在庫場所に搬入(供給)するあらゆる物品を識別するために紐づけ(関連付け)されています。搬入担当者が物品を搬入すると、その物品が識別され、搬入担当者が物品を搬入したことを記録として残すために、ユーザ物品リストが更新されます。
■全体構成
本発明の特許請求の範囲には、大きく分けて、「コンピューティングシステム」の発明と、上記コンピュータによって実行される「方法」の発明とが記載されています。
実施される代表例を概説しますと、以下の通りです。
ユーザ(物流倉庫の搬入者など)が在庫場所に近づくと、カメラなどによってそのユーザを認識します。その特定のユーザが取り出すと予想される物品リスト(いろいろな物品のリスト)は、データストア(データベース)から入手されます。
ユーザが物品を取り出す前のカメラ画像(ビフォア画像)と、取り出した後のカメラ画像(アフター画像)とを画像解析などによって解析します。そして、ユーザが取り出した物品が、ユーザの物品リストのなかにある物品と一致した場合には、物品リストを更新します(物品リストにおいて、その物品を表す識別子(管理記号など)を変更します)。
まず、「コンピューティングシステム」について説明します。
本発明の「コンピューティングシステム」は、
・1つまたは複数のプロセッサと、
・プロセッサに接続されたメモリと、で構成されています。
メモリは、上記のプロセッサに実行させるプログラム命令を格納しています。そして、プログラム命令は、プロセッサに以下のことを実施させます。
1.物資取扱施設内の第1入力装置で入力された第1データ(例えばカメラで撮った画像)を使って、物資取扱施設内のユーザの位置(在庫場所近く)を判断する。
2.ユーザに紐付けされたユーザ物品リスト(ユーザによって取り出される予定の物品を識別している)を、(あらかじめ作成されている)データストアから取り出す。
3.在庫場所にユーザが到達する前に撮影されたユーザの第1画像(ビフォア画像)を、第1入力装置または別の第2入力装置(カメラなど)から受信する。
4.ユーザが在庫場所から離れた後に撮影されたユーザの第2画像(アフター画像)を、第1入力装置または別の第2入力装置(カメラなど)から受信する。
5.第1画像(ビフォア画像)と第2画像(アフター画像)との比較に基づいて、ユーザが持っている対象物が、第2画像(アフター画像)のなかにあるか否かを判断させる。
6.ユーザが持っている対象物が第2画像(アフター画像)にある、という判断に基づいて、その対象物と、在庫場所に関連付けられた在庫物品とが同じであると判断させる。
7.その物品を表す物品識別子(物品の管理記号など)をユーザ物品リストに追加させる。
また、本発明のコンピュータによって実行される「方法」の発明では、以下のことを実行します。
1.物資取扱施設内に配置された第1入力装置で入力された第1データ(例えばカメラで撮った画像)を使って、物資取扱施設内のユーザの位置を判断する。
2.ユーザによって動かされる物品(あらかじめユーザに紐づけされた物品)を識別するユーザ物品リストを(あらかじめ作成されている)データストアから取得する。
3.第1入力装置または別の第2入力装置(カメラなど)から、物資取扱施設内の在庫場所にユーザが手を置く前に撮影された第1画像(ビフォア画像)を受信する。
4.第1入力装置または別の第2入力装置(カメラなど)から、ユーザが在庫場所に手を置いた後に撮影された第2画像(アフター画像)を受信する。
5.第1画像(ビフォア画像)と第2画像(アフター画像)とに基づいて、(画像解析などによって)ユーザが在庫場所に対象物を置いたと判断する。
6.在庫場所に関連付けられた対象物の識別を判断する。
7.在庫場所に置かれた対象物を表す物品識別子(物品の管理記号など)をユーザ物品リストから取り除いて、ユーザ物品リストを更新する。
■細部
■上記コンピューティングシステムにおいて、プロセッサに第1画像(ビフォア画像)と第2画像(アフター画像)とを比較させるプログラム命令は、以下のことをさらに実施できます。すなわち、手の色と物品の色とを区別して物品を認識します。
第1画像(ビフォア画像)と第2画像(アフター画像)とにそれぞれ写っているユーザの皮膚の色に基づいて識別を実行し、
第2画像(アフター画像)における、ユーザの皮膚の色と異なる色の対象物(ユーザの手が持っている物)を識別する。
■対象物が在庫の物品と一致するという判断は、好ましくは、在庫場所にある物品の重量、圧力計、形状などを基にして考察します。
本発明に含まれる上記「方法」の発明は、好ましくは以下のように設計されています。
◆対象物が在庫の物品と一致するか否かを判断するときに、
第1画像(ビフォア画像)および第2画像(アフター画像)の一方または両方を画像処理し、
物品と対象物との関連性を判断すべく、過去に記録された物品と、対象物とを比較し、
最も高い信頼度スコアを有する物品(総合的に判断して最も高い確率で、確かにその物品であると決定できる物品)の物品識別子(リスト中の記号等)を変更することによって、ユーザ物品リストを更新する。
◆対象物が在庫の物品と一致するか否かを判断するときに、
最も高い関連性を数値化するために信頼性スコアを計算し、
信頼性スコアがスレショルド(設定値)を超えているかを判断し(すなわち、信頼性の得点が合格点以上かどうかを判断し)、
ユーザ物品リストの更新を、無人入力によって自動的に行う。
◆在庫場所に残っている対象物を判断し、
在庫場所に関連付けられた物品の在庫数を更新する。
このような発明を実施するための具体例について、以下に説明します。
■実施形態
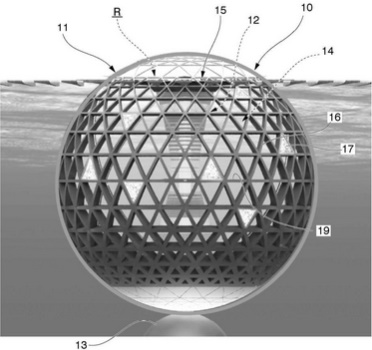
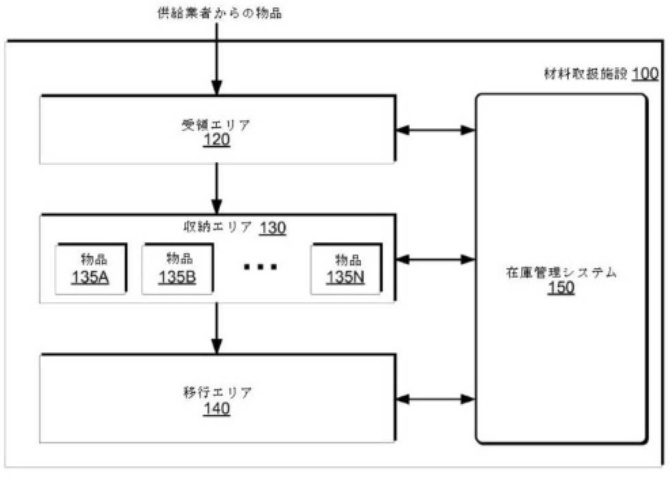
図1は、物資取扱施設の一例を図示したブロック図です。
【図1】
図1に示されているように、物資取扱施設100は、受領エリア120と、任意の数の在庫物品135A~135Nを収納するために構成された収納エリア130と、1つ以上の移行エリア140とを備えます。また、物資取扱施設100は、この施設内で各ユーザが相互に情報を伝え合うように構成された在庫管理システム150をさらに備えています。
物資取扱施設100は、様々な供給業者から在庫物品135を受け取り、そして、ユーザが物品を取り出したり、注文を受けるまで保管したりするように構成されています。物品の一般的な流れは、矢印で示されています。具体的には、製造業者、流通業者、卸売業者などから物品135を受領エリア120で受領できます。物品135は、例えば、商品、日用品、生鮮食品など、さまざまなタイプの物品です。
物品135は、パッケージ、カートン、木箱、パレットといった数えることが可能なものであり、個数単位で、管理されます。また、物品135は、長さ、面積、体積、重量といった単位で管理できます。
物品135は、顧客の注文を受信した場合、またはユーザが物資取扱施設100を進んでいくと、収納エリア130内の在庫から選択されて取り出されます。例えば、ユーザは、物資取扱施設を進みながら収納エリア130内の在庫場所から物品135を取り出します。なお、物資取扱施設の従業員は、顧客の注文に基づいたリストに基づいて、収納エリア130内の在庫場所から物品135を取り出すこともあり得ます。
例えば、ユーザが在庫場所に到達し、収納エリア130内の在庫場所に手を入れる前に、ユーザの手の画像が撮影されます。また、ユーザの手が在庫場所から離れるときに、手の画像が撮影されます。これらの画像を比較することによって、ユーザが、在庫場所から対象物を取り出したか、または、在庫場所に対象物を供給したかを判断できます。例えば、ユーザの手の肌色を判断するために、画像解析が実行されます。
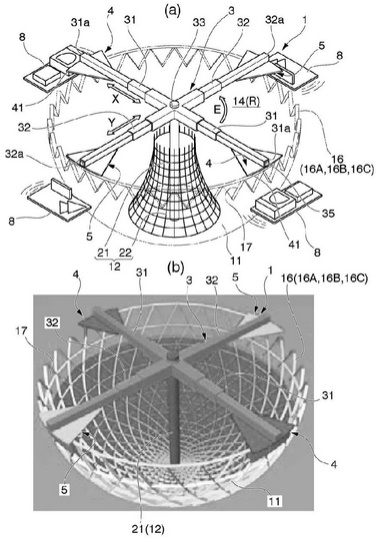
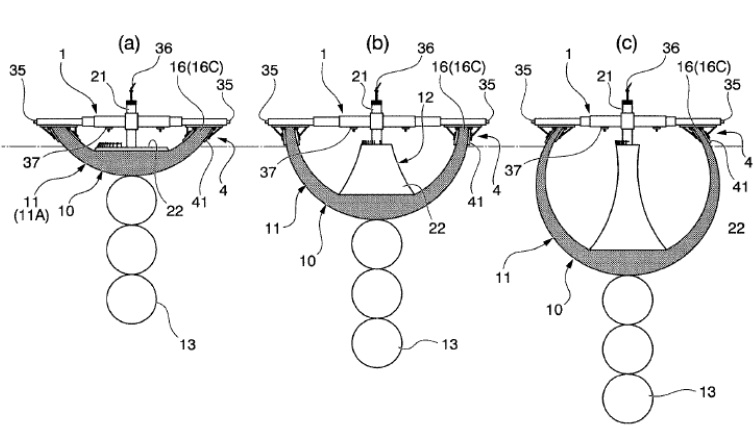
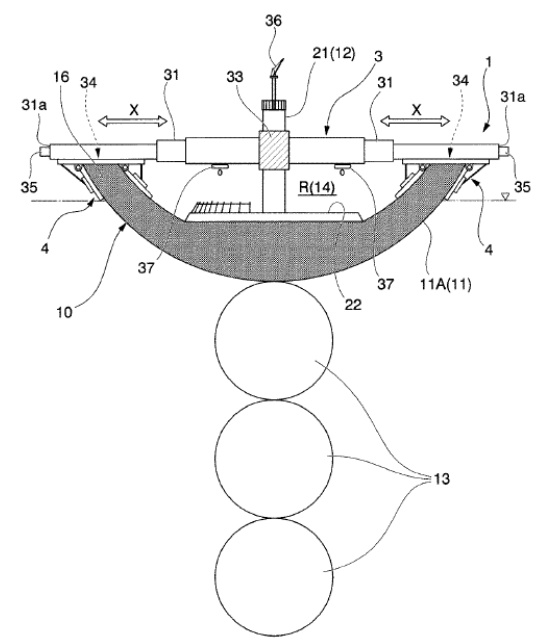
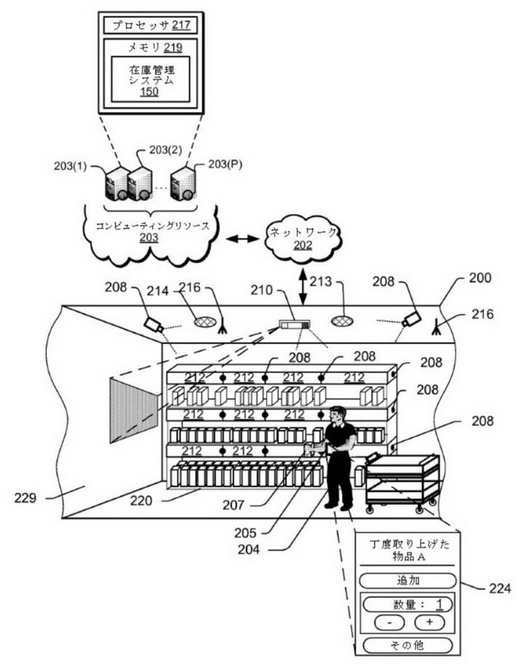
次に、図2に基づいてさらに詳しく説明します。図2のブロック図は、物資取扱施設のさらなる詳細を図示しています。
【図2】
図2は、物資取扱施設200の例を示しています。例えば、物資取扱施設200は、物資取扱施設内の画像が撮影できるように複数のカメラ208を備えています。画像撮影装置208は、物資取扱施設内のユーザや場所の画像を撮影するために、天井などに配置されています。複数のカメラ208は、例えば、ユーザの画像や在庫場所の周囲の画像を撮影でき、また、物品、物品の在庫場所への移動、在庫場所から移動する対象物(例えば、ユーザの手、物品)の画像を撮影できます。
カメラに加えて、圧力センサ、赤外線センサ、重量計、体積変位センサなどの入力装置を使用することも可能です。例えば、対象物が在庫場所から取り出しまたは供給されることを検出するために、圧力センサや重量計を使用することができます。同様に、ユーザの手と在庫物品とを区別する赤外線センサを使用できます。
物資取扱施設200内にいるユーザ204は、携帯装置205を所有することも可能です。携帯装置を通して、物資取扱施設200内に配置されている物品207の情報を確認できる場合もあります。
帯装置205は、在庫管理システム150との通信を容易にするために、例えば無線モジュール205と、ディスプレイ(例えば、タッチベースのディスプレイ)とを有します。携帯装置205は、在庫管理システム150へ提供できる「固有の識別子」を有します。
携帯装置205は、在庫管理システム150と連携して、作動または通信できます。同様に、在庫管理システム150は、携帯装置205と相互に情報を伝達し合い、ユーザを識別することができ、また、ユーザと通信することができます。
在庫管理システム150は、ユーザ204との間の通信を容易にするために、プロジェクタ210、ディスプレイ212、スピーカ213、マイクロフォン214のような入力/出力装置を備えることができます。同様に、在庫管理システム150は、携帯装置205との間の無線通信を容易にするために、無線アンテナ216などの通信デバイスを備えることができます(例えば、WiFi、ブルートゥースなど)。
携帯装置205が在庫管理システム150に接続して通信するために、物資取扱施設内のアンテナ216を利用できます。一方、在庫管理システム150が物資取扱施設200から離れている場合でも、在庫管理システム150は、同様に、ネットワーク202を通じて、在庫管理システム150及び/または携帯装置205と通信することが可能です。
以下、ユーザが物資取扱施設内の在庫場所から物品を取り出した(搬出した)ことを判断する例について説明します。
ユーザが物資取扱施設に入ると、在庫管理システム150は、顔認識、ユーザIDカード、ユーザ提供情報などによって、ユーザを識別できます。ユーザ情報を識別すると、ユーザの物品検索履歴、購入履歴などが、データストアから取得されます。
ユーザが物資取扱施設200を進んでいくと、画像装置208は、ユーザ204の画像を撮影し、その画像を処理するためにコンピューティングリソース203に提供できます。例えば、在庫場所に写り込む直前のユーザの手の画像が撮影されるか、または、在庫場所から対象物を取り出した直後のユーザの手の画像が撮影され、コンピューティングリソース203に提供されます。
コンピューティングリソース203は、対象物が在庫場所から取り出されたか、在庫場所に供給されたかを判断するために画像を処理できます。在庫場所から取り出されたと判断した場合には、在庫管理システム150は、在庫場所に収納されている在庫品の識別情報を取得し、ユーザがその在庫品を在庫場所から取り出したことを識別して、ユーザ物品リスト(そのユーザに紐づけされた物品リスト)において、その在庫品の物品識別子を変更できます。同様に、物品が在庫場所から取り出されたことを反映するために、在庫場所における在庫品の在庫量を減少させることができます。
別の例では、ユーザが在庫場所から取り出した対象物を識別できなかった場合、在庫管理システム150は、対象物の識別をサポート(支援)します。そのサポートでは、ユーザに関する他の情報(例えば、過去の購入履歴、現在取得している物品)を利用することができます。例えば、在庫管理システム150は、取り出された対象物がケチャップのボトルかマスタードのボトルか判断できない場合、過去の購入履歴、または、以前に在庫場所から取り出された物品を参考にできます。具体的には、ユーザの購入履歴を参照したときにケチャップのみ購入履歴がある場合、ユーザがおそらくケチャップを在庫場所から取り出したことを確認するために、このような情報を使用できます。
なお、対象物が在庫場所から取り出し/供給されたことの判断をサポート(支援)するために、画像解析に加えて、重量計または圧力センサから受信したデータに基づいて、対象物の重量を判断できます。複数のしくみを組み合わせることによって、識別される物品と、実際に在庫場所から取り出された物品とが一致する確率を高めることができ、これによって高い信頼度スコアを生み出すことができます。
さらなる工夫も可能です。例えば、取り出された在庫品の識別は確認できたが、取り出された後の在庫品数を確実には判断できない場合、在庫管理システムは、携帯装置205を通して、ユーザに情報を提供できます。例えば、まず、ユーザが在庫場所から物品Aを供給/取出したことを携帯装置が識別します。次に、制御装置224によって、物品をユーザ物品リストに追加すべきか、物品の数量をどれだけユーザ物品リストに追加すべきかをユーザが念のための確認をすることができます。
展望、結語
以上ご説明しましたように、本発明のコンピューティングプログラム、および、そのプログラムを利用する方法によって、在庫場所において物品の取り出しおよび供給を精度よくしかも簡便に追跡できます。上述したような工夫が詰め込まれた本発明は、人が作業しなくても物流管理できることから、将来的に注目できるものです。
■概要
出願国:日本 発明の名称:物品の相互作用及び移動検出方法
出願番号:特願2017-124740(P2017-124740)
特許番号:特許第6463804号(P6463804)
出願日:2017年6月27日
公開日:2017年11月24日
登録日:2019年1月11日
出願人:アマゾン テクノロジーズ インコーポレイテッド
経過情報:親出願は特許査定となりましたが特許料不納により権利とならず、分割出願された本出願(子出願)が審査を経て、特許となりました。本出願からさらに分割出願された孫出願は、審査中です。
その他情報:本権利は抹消されていません。存続期間満了日は2034年6月18日です。国、加国で特許登録となっています。
IPC:G06Q
<免責事由>
本解説は、主に発明の紹介を主たる目的とするもので、特許権の権利範囲(技術的範囲の解釈)に関する見解及び発明の要旨認定に関する見解を示すものではありません。自社製品がこれらの技術的範囲に属するか否かについては、当社は一切の責任を負いません。技術的範囲の解釈に関する見解及び発明の要旨認定に関する見解については、特許(知的財産)の専門家であるお近くの弁理士にご相談ください。