


アートとテクノロジーの融合で創造の扉を開く

アートの世界において、新しいスタイルや表現方法を追求することは、常にクリエイターたちの挑戦となっています。そして今、テクノロジーがその挑戦をサポートし、新しい可能性を切り開く手段となりつつあります。今回紹介する特許発明は、まさにアートとテクノロジーの融合から生まれた、新しい創造の道を開くツールです。
このシステムは、多くの異なるアートワークから「特徴データ」を抽出し、それを基にまったく新しいスタイルの画像を生成することを可能にします。異なるアーティストや時代から得られたデータを解析し、新しい作風を探求することで、アーティストやデザイナーがこれまでにない新しい表現を生み出す手助けをします。
この技術は、アートの新しいトレンドを生み出すだけでなく、デザインの分野においても新しい波を作る可能性を秘めています。アートとテクノロジーが交わることで、私たちの表現の形がどのように変わり、進化していくのか、その未来が非常に楽しみです。
発明の背景
本発明は、新規な作風のデジタルデータを特定できる情報処理方法、プログラム、および情報処理装置に関します。
近年、キーワードを入力して画像を生成する画像生成AI(Artificial Intelligence)が知られています。入力するキーワード(すなわち、命令文)を工夫すれば、自分の思い通りの画像を生成してくれる可能性を秘めている技術が、画像生成AIです。
従来技術では、ユーザが作成したい画像をキーワード化し、このキーワードを入力することで、キーワードに適合する唯一無二の画像が生成されます。しかし、画像生成AIは、過去に蓄積されたデータを参考にしているため、生み出された画像も、過去の画像のうち多数派の画像を参考にしてしまう可能性が高いといえます。したがって、従来の画像の作風(画家の特色や傾向)と全く異なる新規な画像が生成されるとは限りません。
そこで、従来の多数派に類似する作風ではなく、新規な作風のデジタルデータを容易に特定できる仕組みが要望されています。
どんな発明?
発明の目的
本発明で提供するアイデアは、新規な作風を有するデジタルデータを容易に特定できる仕組みです。換言すると、本発明は、新規な作風を有するデジタルデータを容易に特定できる情報処理方法、および、この方法を実施する情報処理装置です。
本発明の情報処理方法では、
まず第1ステップで、情報処理装置に含まれるプロセッサが、画像生成指示を受け付けます。
次の第2ステップで、複数の画像におけるN次元の各第1特徴データと、生成指示に応じて生成されるN次元の第2特徴データとの距離を用いて、各第2特徴データの中から、N次元の座標系のなかで「疎な領域」内の第3特徴データを特定します。簡単に説明しますと、過去の画像の特徴データ(第1特徴データ)と、AI技術で生成された画像の特徴データ(第2特徴データ)とを比較して、第2特徴データのうち、第1特徴データ(従来の作風)から最も類似しない特徴データ(第3特徴データ)を特定し(選び出し)ます。
最後の第3ステップで、特定された第3特徴データに関する情報を出力します。
好ましくは、第2ステップで、
各時代に分類された画像(ルネサンス時代の画像、印象派時代の画像など)から各時代の流行を学習する学習モデルを用います。この学習モデルは、各時代の画像の流行から将来の画像の流行を予測できます。そして、この学習モデルを用いて、将来の流行を示す画像の第3特徴データを特定します。
好ましくは、本発明の情報処理方法では、機械学習モデルを利用して第3特徴データから画像を生成し、生成される画像を第3ステップで出力します。
発明の詳細
図面を参照して、本発明の具体例を説明します。なお、各図において、同一の符号を付したものは、同一または同様の構成を有します。
<システム構成>
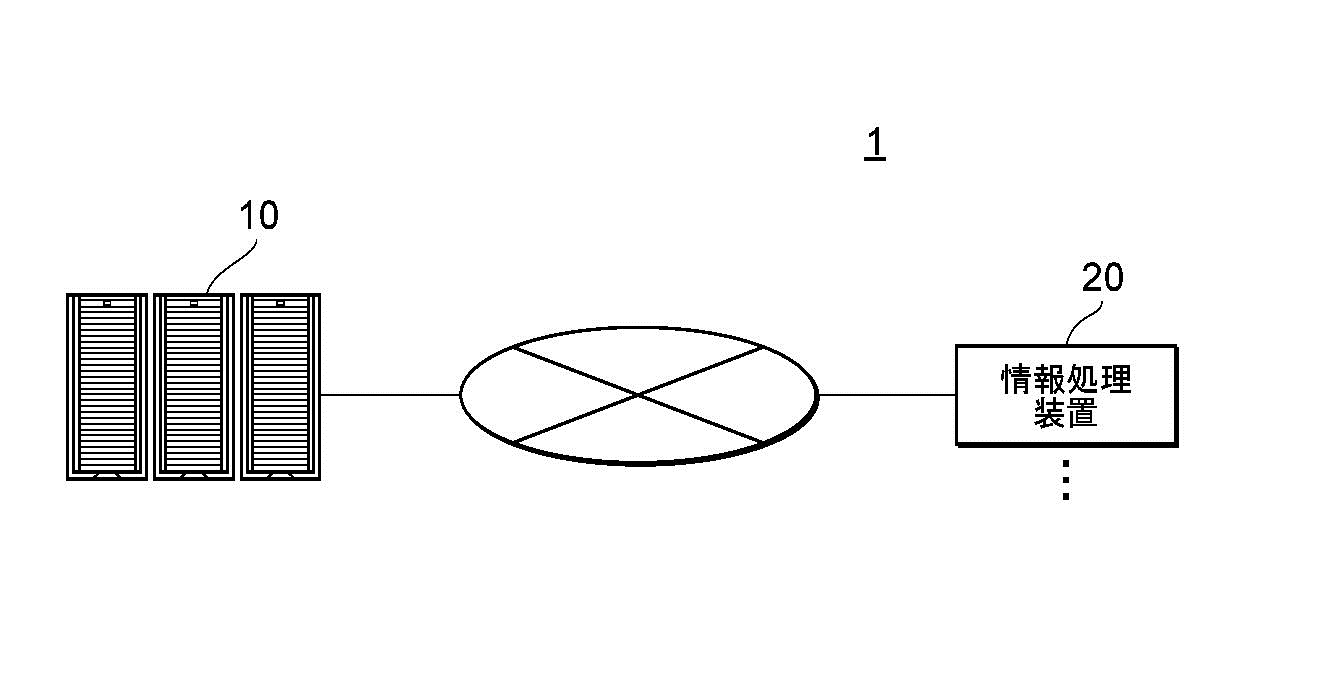
図1は、本発明のシステム構成の一例を示します。図1に示すシステム1において、サーバ10と情報処理装置20とが、ネットワークを介してデータ送受信できるように接続されています。
サーバ10は、データを収集および分析できる情報処理装置であり、1つまたは複数の情報処理装置で構成されます。情報処理装置20は、例えばユーザが利用するパーソナルコンピュータ、スマートフォン、タブレット端末などの装置です。
情報処理装置20は、例えば、ネットワークを介してサーバ10に接続されます。
図1に示すシステム1では、例えば、新規な作風の画像を生成する画像生成指示を、情報処理装置20からサーバ10が受け付けます。そして、様々な流派や年代の画像の特徴データによって生成される空間(後に詳述)を用いて、これまで描かれたり生成されたりしていない作風の画像を特定します。後に具体的に説明しますが、特徴データがマッピングされた空間のなかで「疎な空間」は、これまで存在しない作風の特徴データを含む空間を示します。この「疎な空間」内から特徴データを特定できるのです。
 【図1】
【図1】
次に、本発明を構成する各装置の物理的構成について説明します。
<ハードウェア構成>
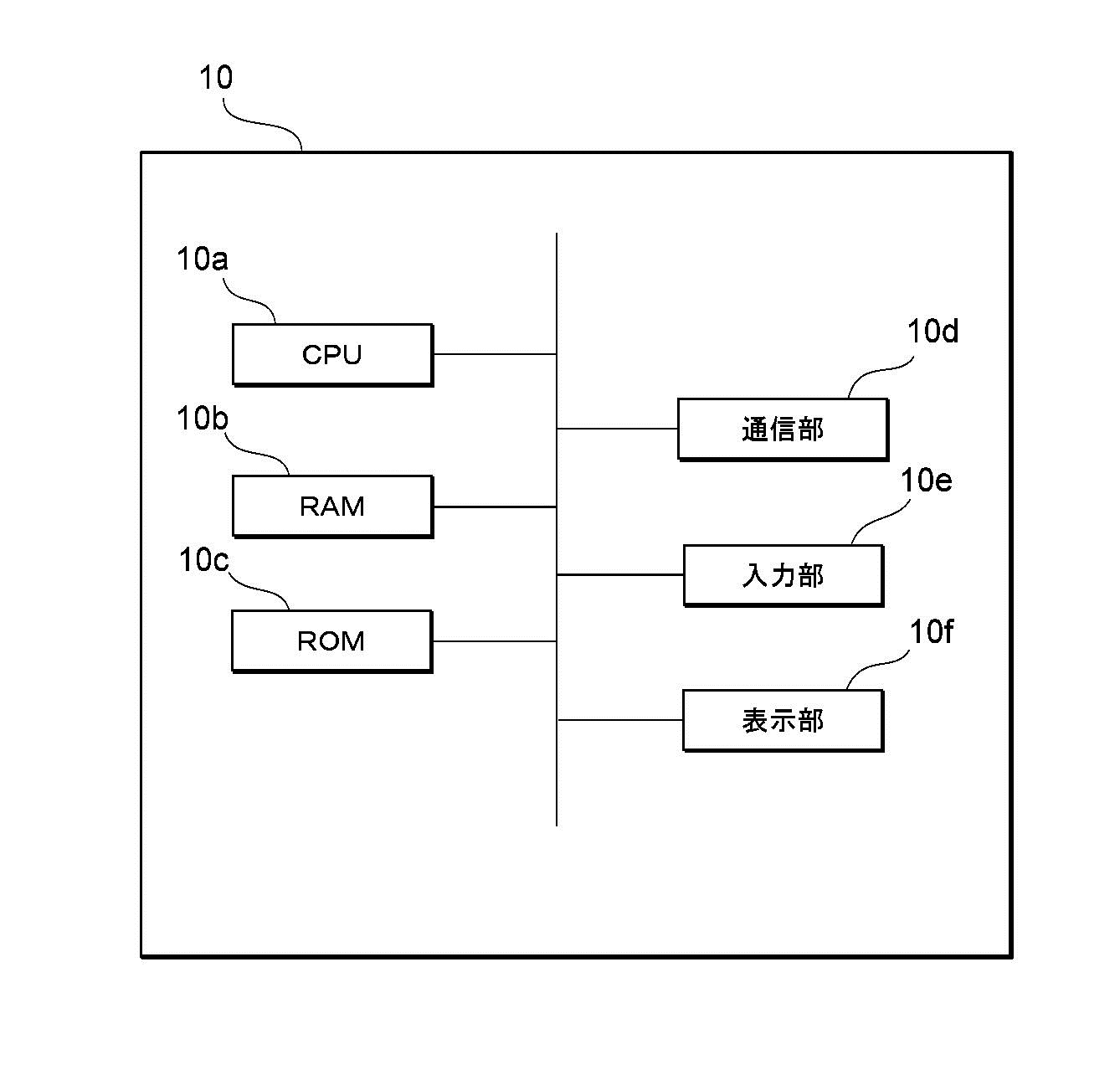
図2は、サーバの情報処理装置10の物理的構成の一例を示します。サーバ10は、演算部に相当するCPU(Central Processing Unit)10a、記憶部に相当するRAM(Random Access Memory)10b、記憶部に相当するROM(Read only Memory)10c、通信部10d、入力部10e、および、表示部10fを有します。これらの各構成は、相互にデータ送受信できるように接続されています。
 【図2】
【図2】
本具体例では、情報処理装置10が一台の情報処理装置で構成される場合について説明しますが、情報処理装置10では、例えば、複数のコンピュータまたは複数の演算部が組み合わされる場合があります。
CPU10aは、RAM10bまたはROM10cに記憶されたプログラムの実行に関する制御、データの演算、加工を行う制御部です。CPU10aは、演算部であり、例えば、所定の生成指示を取得すると、これまでに存在しない新規な作風の特徴データを特定するプログラムを実行します。CPU10aは、入力部10eや通信部10dから種々のデータを受け取り、データの演算結果を表示部10fに表示したり、RAM10bに格納したりします。
RAM10bは、記憶部のうちデータの書き換えが可能なものであり、例えば半導体記憶素子で構成されます。RAM10bは、CPU10aが実行するプログラム、様々な作風や年代の画像、これらの画像の特徴データなどのデータを記憶します。
ROM10cは、記憶部のうちデータの読み出しが可能なものであり、例えば半導体記憶素子で構成されます。ROM10cは、例えば生成プログラム、または、書き換えできないデータを記憶します。
通信部10dは、情報処理装置10を他の機器に接続するインターフェースです。通信部10dは、インターネット等の通信ネットワークに接続されます。
入力部10eは、ユーザからデータの入力を受け付けるものであり、例えば、キーボードおよびタッチパネルを含みます。
表示部10fは、CPU10aによる演算結果を視覚的に表示するものであり、例えば、液晶表示装置(LCD Liquid Crystal Display)により構成されます。表示部10fは、例えば、学習結果などを表示します。
本発明のプログラムは、コンピュータによって読み取り可能な非一時的な記憶媒体(RAM10bやROM10c等)に記憶されて提供されたり、通信部10dにより接続される通信ネットワークを介して提供されたりします。情報処理装置10では、CPU10aが特定プログラムを実行することにより、様々な動作(後の図3で説明)を行います。なお、例えば情報処理装置10は、CPU10aと、RAM10bやROM10cとが一体化したLSI(Large-Scale Integration)を備える場合があります。また、情報処理装置10は、GPU(Graphical Processing Unit)やASIC(Application Specific Integrated Circuit)を備える場合があります。
<処理構成例>
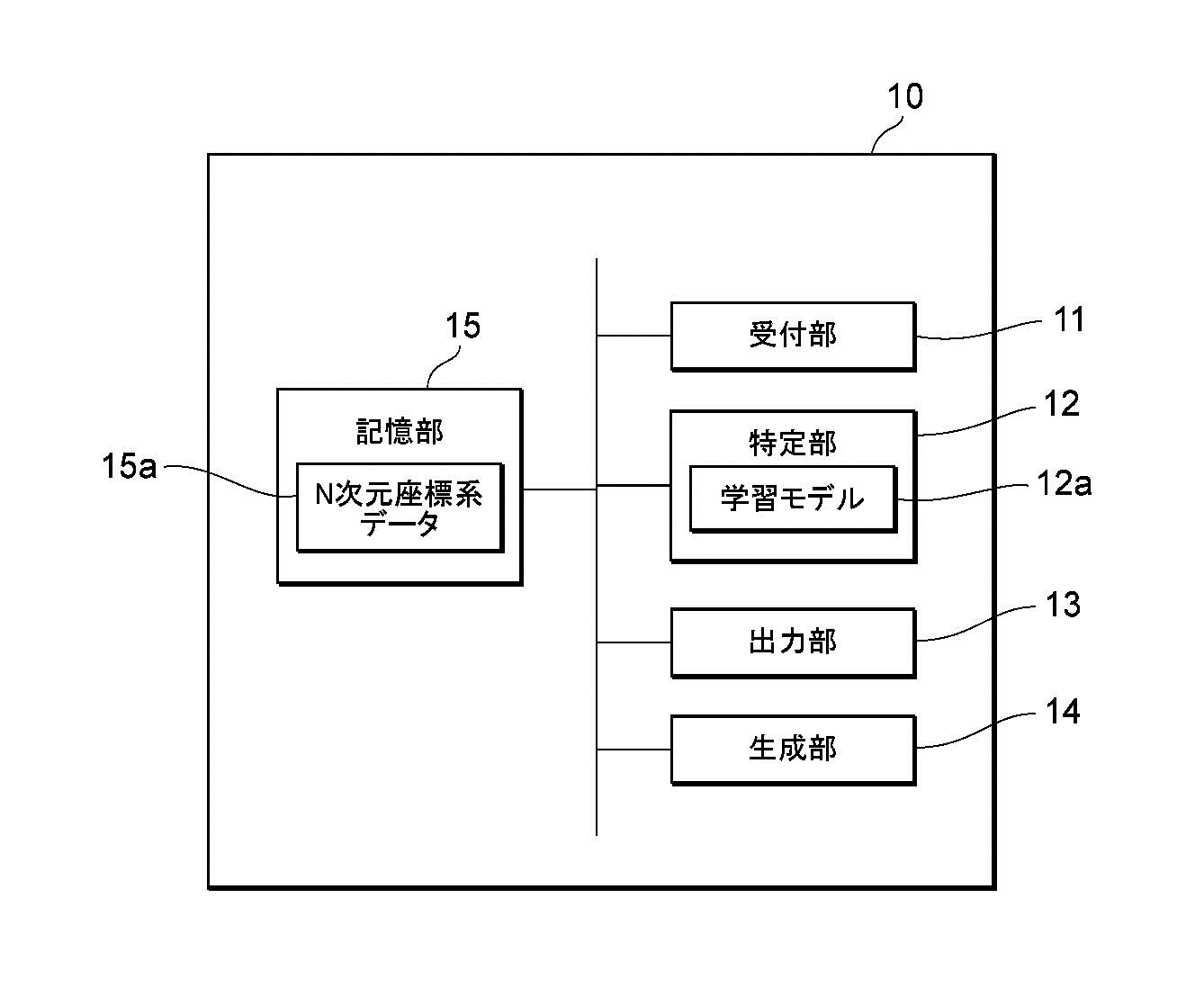
図3は、情報処理装置10の処理ブロックの一例を示します。情報処理装置10は、受付部11、特定部12、出力部13、生成部14、および記憶部15を備えます。図3に示す特定部12、生成部14は、例えばCPU10aなどによって実現されます。受付部11および出力部13は、例えば通信部10dなどによって実現されます。記憶部15は、RAM10bやROM10cなどによって実現されます。情報処理装置10は、量子コンピュータなどで構成される場合があります。
 【図3】
【図3】
受付部11は、所定の生成指示を受け付けます。例えば、受付部11は、ユーザ装置などの他の情報処理装置20から送信された画像生成指示を、通信部10dを介して受け付けます。画像生成指示は、例えば、特徴データ生成指示です。
特定部12では、すでにある多数の画像の特徴と、生成指示に従って生成された画像の特徴とを比べます。詳しくは、特徴を測るためにN個の指標(物差し)を採用します。例えば、色の表現法としてRGB[赤(Red)、緑(Green)、青(Blue)]を採用すると、指標として3つの原色を採用するため、Nは3となります。色自体は、N=3の3次元の立体的なグラフ上で表せますが、画像の特徴には、色の他にも明度(明るさ)や透明度という指標もあります。さらにほかの指標も関係します。よって、通常、Nは3以上の整数になります。
そして、多数の画像におけるN次元の各特徴データ(「第1特徴データ」)を取得したうえで、さらに、生成指示に従って生成される画像でも、N次元の特徴データ(「第2特徴データ」)を取得します。
ここで、「第1特徴データ」と「第2特徴データ」とを比較するために、「第1特徴データ」と「第2特徴データ」との距離を計算します(後に詳述)。そして、計算によって求めた距離を基にして、各第2特徴データの中から、N次元の座標系内の「疎な領域」内の特徴データ(「第3特徴データ」)を特定します。すなわち、第1特徴データから最もかけ離れた特徴データを決めます。
N次元の座標系のデータは、例えば、各時代の多数の絵画などを撮影するなどしてデジタルデータ化し、デジタルデータ化した画像からN次元の特徴データが抽出され、N次元の特徴データがN次元の座標系にマッピングされて生成されます。N次元は、例えば、RGBなどの各成分、輝度、透明度などによって表され、座標系の各軸は所定範囲(例、0~255)で表されます。
「疎な領域」にある特徴データ「第3特徴データ」は、過去の画像データの特徴データをマッピングした座標系において、これまでにない作風の画像の特徴データであることを示しています。「疎な領域」を探索するための方法では、例えば、ランダムにN次元の第2特徴データを所定数になるまで生成された第2特徴データと、座標系にマッピングされた多数の過去画像の各第1特徴データとを用いて平均二乗誤差(MSE:Mean Square Error)を算出します。次に、このMSEが一番大きい特徴データ、すなわち、過去画像の各第1特徴データから最も離れている第2特徴データを、「疎な領域」内の第3特徴データとして特定します。要約しますと、AIなどを利用して生成した画像の特徴のなかで、従来の画像の特徴から最も離れている特徴データを抽出します。なお、MSEは、類似度を計算する手法の一例であり、その他の計算手法を用いることも可能です。
出力部13は、特定部12により特定された上記の第3特徴データに関する情報を出力します。例えば、出力部13は、特定された第3特徴データそのものを出力したり、特定された第3特徴データに基づいて生成された情報を出力したりします。第3特徴データに基づいて生成された情報は、例えば、この第3特徴データから生成された画像、および、この第3特徴データを直接的または間接的にユーザに通知する通知情報などを含みます。
以上の処理により、新規な作風を有する画像の第3特徴データを容易に特定できます。
<適用例>
抽象的な説明が続いたため、次に具体的な適用例を挙げて説明します。
図4~図7は、適用例を説明するための図です。図4は、3次元の座標空間に過去画像の特徴データがマッピングされた例を示します。図4に示す例において、過去画像の特徴データ(第1特徴データ)は点で表され、第1乃至3次元は、例えばRGB(赤、緑、青)の各成分に対応します。
 【図4】
【図4】
さらに具体的な適用例を示します。時代に応じて作風の流行を推定する例を次の図7で説明します。
 【図7】
【図7】
時代に応じて作風の流行を推定する図7の例では、第N年代(第1~第5年代)の作風が密集した領域が特定されます。例えば、古代から現代における各年代の作風の第1特徴データを推定する関数F1が求められます。関数F1は、1次関数の直線、または、N次関数などの曲線です。関数F1は、年代を入力することで、その年代の流行の作風を推定する方程式、と認識できます。
例えば、西洋美術の場合、以下の時代ごとに流行した画像の第1特徴データを用いることが可能です。
12世紀:ゴシック美術
15世紀末:北方ルネサンス美術
15世紀末から30年間ほど:盛期ルネサンス美術
17世紀:バロック美術
18世紀:ロココ美術
18世紀後半:新古典主義
19世紀前半:写実主義
19世紀後半:印象派
20世紀初頭:キュビズム
20世紀以降:21世紀美術
関数F1は、例えば、各年代の第1特徴データを学習データとし、流行の特徴データを推定する回帰問題を解く(方程式を解く)機械学習モデルを使い、機械学習によって算出されます。
以上の処理により、ある時代を特定することで、その時代の作風を表す第3特徴データを推定可能です。また、生成部14は、推定された第3特徴データに基づいて画像を生成できます。これにより、年代を指定することで、その年代の流行を示す作風の画像を自動で生成できます。算出された関数(学習モデル)F1は、記憶部15に記憶され、外部の装置に出力されます。なお、各年代の流行の作風は、例えば世界の地域ごとに設定されます。具体的には、特定部12は、西洋美術、日本美術、東洋美術などの各地域の各絵画の画像の作風から、各地域の流行の作風を推定する関数を求めます。
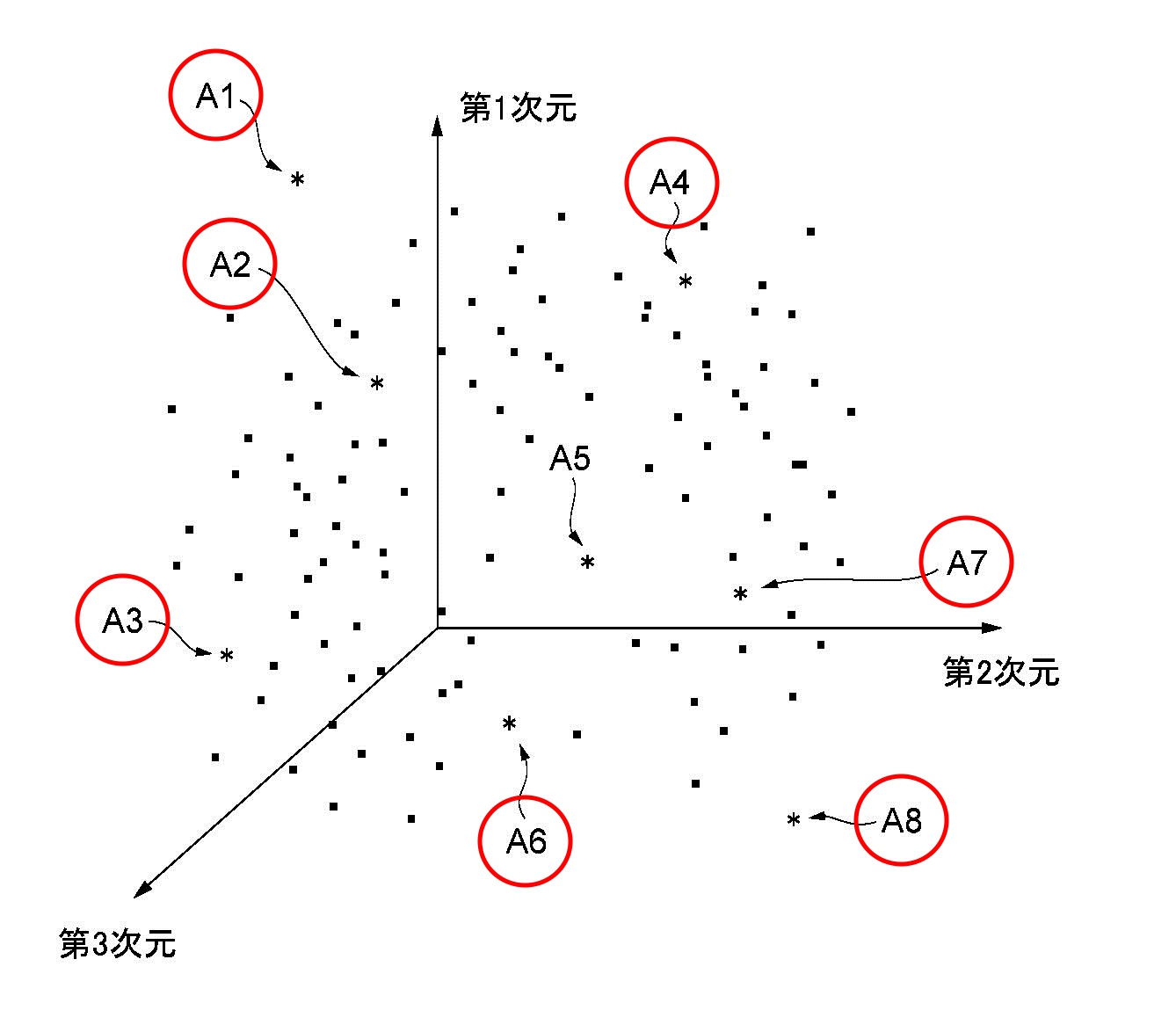
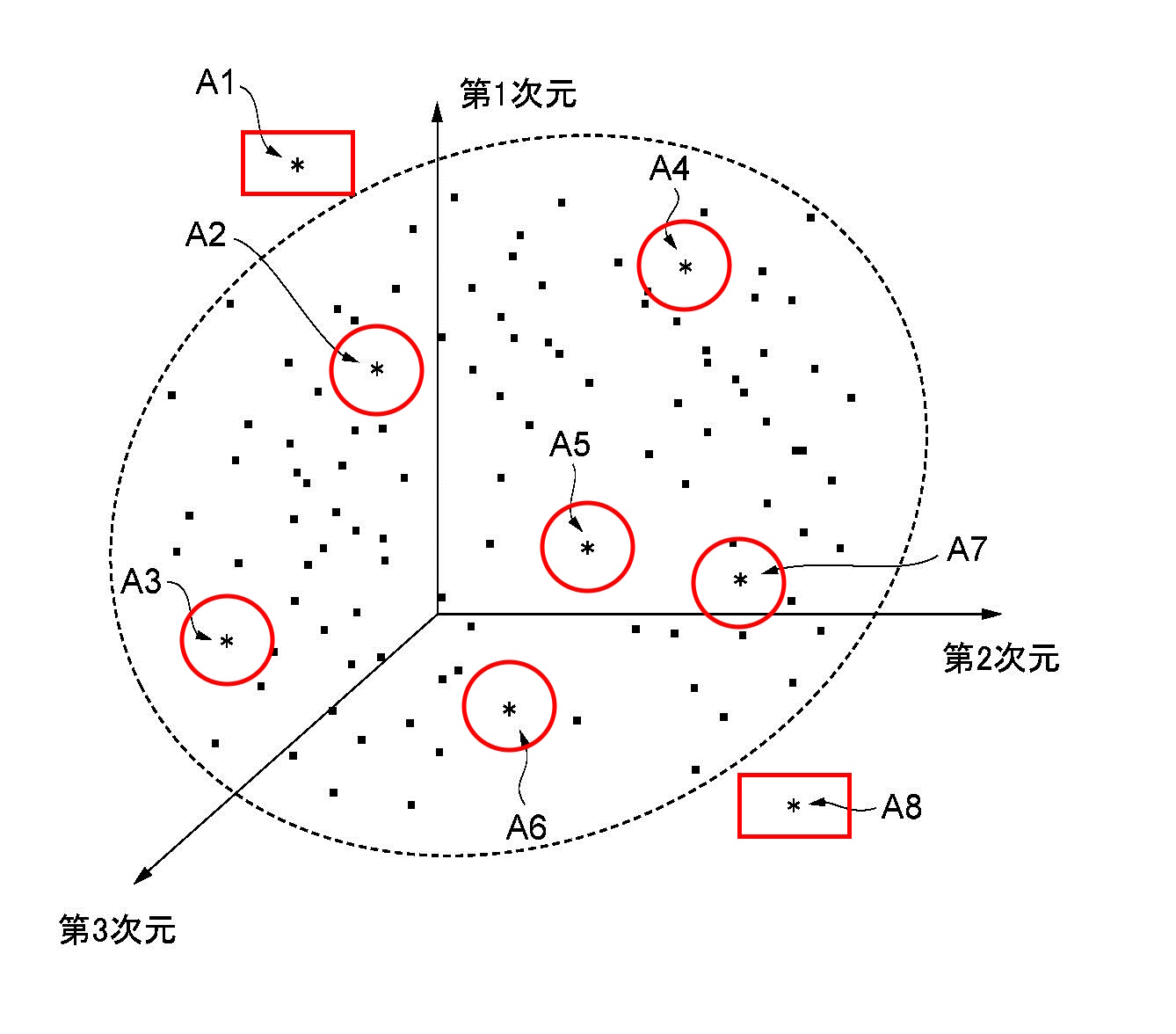
上記の図7で具体的な一例を説明しました。具体例を示したところで(少し抽象的になりますが)本発明の概念を説明します。図5は、特徴データが同様に3次元座標空間にマッピングされた例ですが、図5に示す点A1乃至A8は、AI等によってランダムに生成された特徴データ(第2特徴データ)であり、*で表されます。
図5に示す例において、第2特徴データそれぞれと、各第1特徴データとの平均二乗誤差(類似度の一例)を求め、平均二乗誤差が一番大きい第2特徴データを第3特徴データとして特定します。図5に示す例では、第2特徴データA1が、各第1特徴データから最も離れた第3特徴データとなります。生成部14は、第2特徴データA1に基づいて画像を生成します。これにより、新規な作風の画像を生成できます。
 【図5】
【図5】
図6は、3次元座標空間における各第1特徴データの最外形を形成する例を示します。図6に示す例では、最外形を点線の楕円形状で表しますが、ポリゴン形状(多面体形状)で表すことも可能です。図6に示す例において、最外形の外側にある第2特徴データA1およびA8は、特定対象から除外します。あまりにも常識から外れた特徴を取り除く作業です。そして、最外形の内部にある第2特徴データの中から、各第1特徴データとの平均二乗誤差が一番大きい(類似度が一番小さい)第3特徴データを特定します。例えば、第2特徴データA5の平均二乗誤差が一番大きいとします。
第2特徴データA5は、既存の作風によって形成される領域の中で、最も「疎な空間」に存在する特徴データであり、これまでに存在しない作風の特徴データであることを表します。第2特徴データA5に基づいて画像を生成することで、既存の作風によって形成される領域または空間の中であり、かつ、既存にはない作風の画像を自動で生成できます。
 【図6】
【図6】
また、各第1特徴データに基づいて画像を分類する学習が行われた学習モデル(学習済みモデル)12aに、第2特徴データを入力して、第3特徴データを特定することも可能です。
例えば、過去画像の第1特徴データを分類(クラスタリング)する機械学習を行います。このとき、ランダムに新たな第2特徴データを学習モデル12aに入力し、各クラスタ(分類群)と最もかけ離れた(類似度が一番低い)第2特徴データを第3特徴データとして特定します。なお、外部装置から取得した学習済みの学習モデル12aを利用可能です。
以上の処理により、新規な作風の画像の第3特徴データを探索することを容易に行うことができるようになります。
また、学習モデル12aを用いる場合は、最外形の外側にある第2特徴データに対してペナルティ項を設けて損失関数を定義することで、最外形の外側にある第2特徴データが第3特徴データとして特定されにくくできます。換言すると、異常値と考えられる特徴データを簡便に取り除くことが可能です。
以上の処理により、過去画像の作風に基づき形成される領域のうち「疎な領域」を特定でき、これまで評価されてきた作風に基づき、これまでに存在しなかった作風の特徴データを特定できます。すなわち、人に受け入れられやすい作風の画像の特徴データを特定できます。
生成部14は、特定された第3特徴データに基づいて画像を生成します。このとき、生成部14は、生成された画像が、特定された第3特徴データを維持するようにして画像を生成します。
出力部13は、生成部14によって生成された画像を出力します。出力部13は、画像生成要求を行った情報処理装置20に、生成された画像を出力する場合があります。
以上の処理により、新規な作風を示す第3特徴データから生成された画像をユーザに提供できます。
また、生成部14は、画像生成を行う機械学習モデルを利用して探索された第3特徴データから画像を生成することも可能です。例えば、生成部14は、公知の画像生成AIを利用して、第3特徴データを画像生成AIに入力することで画像を生成できます。
以上の処理により、容易に画像を生成でき、第3特徴データを有する複数の画像を容易に生成できます。なお、画像生成AIにより生成された複数の画像をユーザに提示し、少なくとも1つの画像を選択してもらうことで、ユーザの好みを画像生成AIが学習することも可能です。これにより、そのユーザの好みの画像を生成できます。
また、学習モデル12aを用いて、将来の流行を示す画像の第3特徴データを特定できます。学習モデル12aは、各時代に分類された複数の画像から各時代の流行を学習し、さらに、各時代の画像の流行から将来の画像の流行を予測できます。例えば、画像の作風の流行を予測する学習モデル12aを用いることにより、将来人類に好まれる作風を予測し、予測された第3特徴データを特定します。
また、何年先かを指定することで、指定された年に流行すると予測される作風の特徴データを特定することも可能です。生成部14は、予測された特徴データに基づいて画像を生成することも可能です。
以上の処理により、将来流行すると予測される作風の特徴データを特定できます。例えば、10年後、20年後などの将来の所定年を指定することで、その指定年の流行の作風の特徴データを予測可能です。
ここがポイント!
以上説明しましたように、本発明によって、新規な作風を有するデジタルデータの特定を容易に行えます。
本発明の情報処理方法および情報処理装置では、まず第1ステップで、情報処理装置に含まれるプロセッサが、画像生成指示を受け付けます。
次の第2ステップで、複数の画像におけるN次元の各第1特徴データと、生成指示に応じて生成されるN次元の第2特徴データとの距離を用いて、各第2特徴データの中から、N次元の座標系のなかで「疎な領域」内の第3特徴データを特定します。
最後の第3ステップで、特定された第3特徴データに関する情報を出力します。
未来予想
本特許は、クリエイターズネクスト社から出願されました。クリエイターズネクスト社は、窪田 望氏によって設立されました。ウェブサイトを見ますと、今までのクリエイターはモノづくりをしていたが、「次の(NEXT)」時代のクリエイターは「笑顔」を創るべきだ、というコンセプトがあります。
窪田 望氏は、過去に日本一のウェブ解析士として2年連続で選出されたという経歴をお持ちです。事業分野は、ウェブサイト制作事業、ウェブ上メディア運営事業、ウェブサイト記事執筆事業などです。
本発明は、AI技術を利用しつつ独自性のある画像を生成するためのアイデアです。独自性や創造性は人間だけの能力と考えられていますが、近い将来、属自制や創造性のある画像が簡単に生成される可能性を秘めた発明です。
特許の概要
|
発明の名称 |
新規な作風のデジタルデータの特定 |
|
出願番号 |
特願2022-197061 |
|
特許番号 |
特許第7270894号 |
|
出願日 |
2022.12.09 |
|
公開日 |
2023.05.11(特許公報) |
|
審査請求日 |
2022.12.09(早期審査対象出願) |
|
登録日 |
2023.04.28 |
|
出願人 |
株式会社Creator’s NEXT |
|
発明者 |
窪田 望 |
| 国際特許分類 |
G06T 1/40 |
| 経過情報 |
本願は出願日と同日に早期審査請求され、拒絶理由通知を受けずに特許となりました。 |
 【図1】
【図1】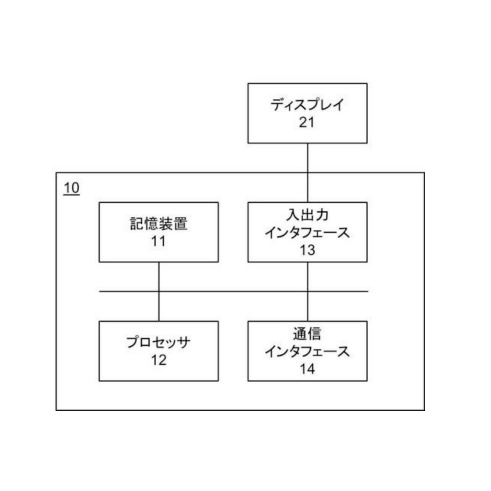 【図2】
【図2】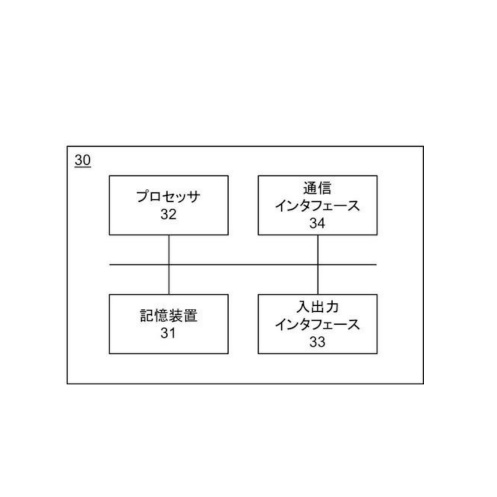 【図3】
【図3】 【図4】
【図4】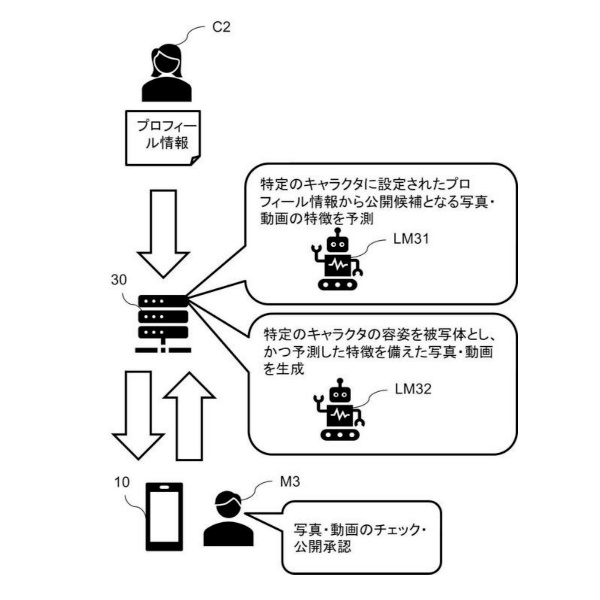 【図5】
【図5】 【図6】
【図6】 【図7】
【図7】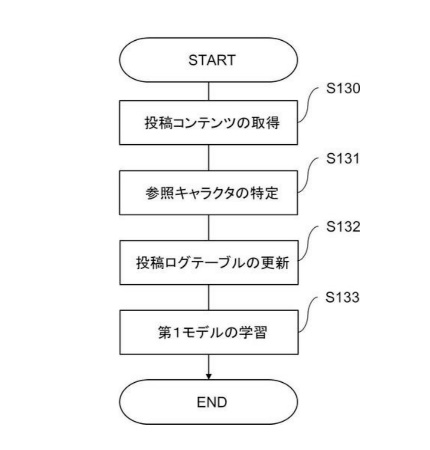 【図8】
【図8】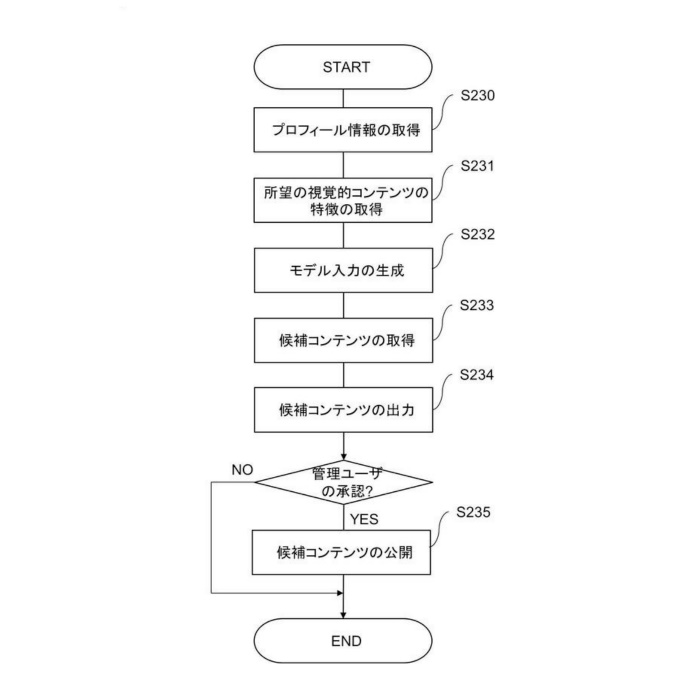 【図9】
【図9】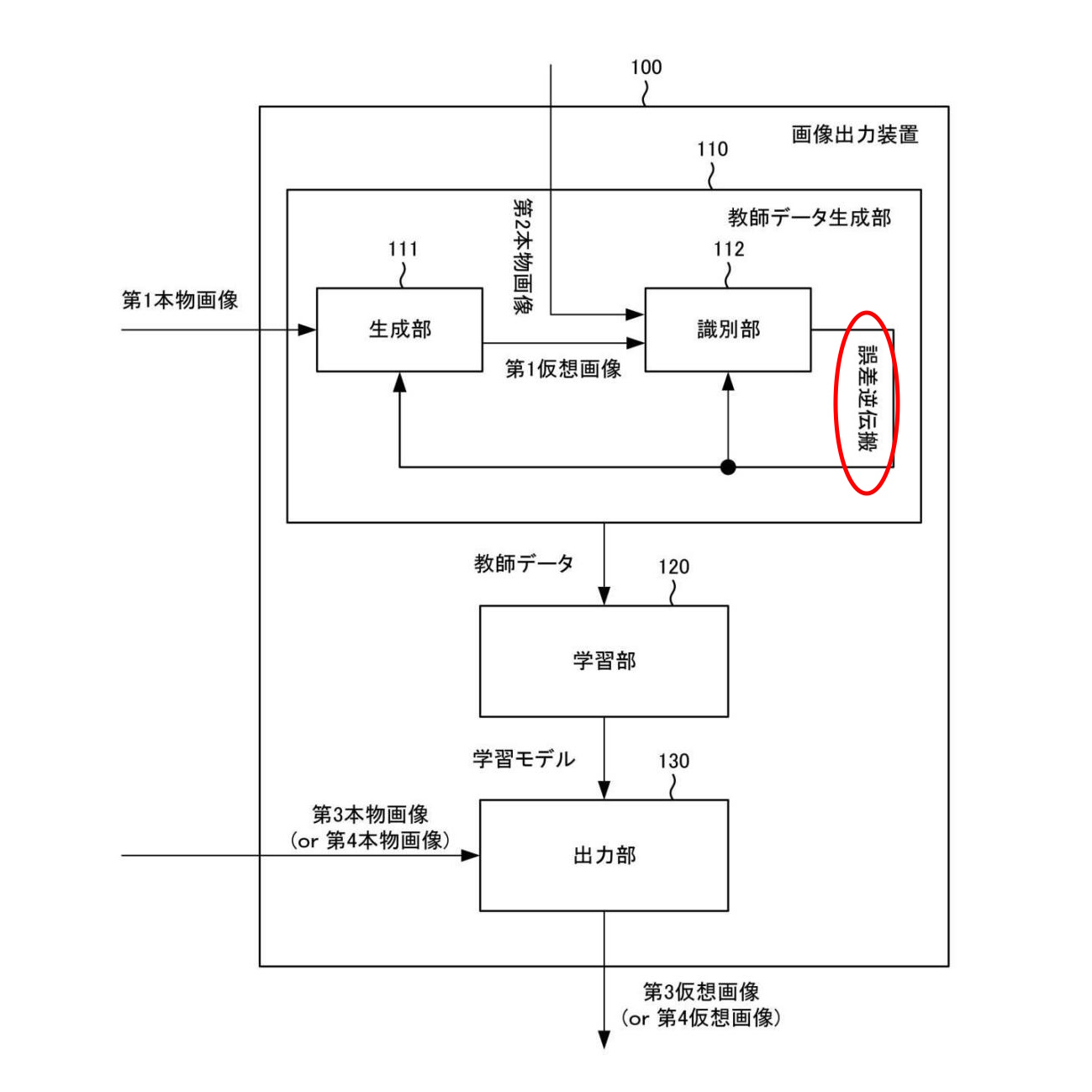 【図1】画像出力装置の概要
【図1】画像出力装置の概要 【図2】
【図2】 【図3】
【図3】 【図4】
【図4】 【図5】
【図5】

